IBM DB2 monitoring
This extension documentation is now deprecated and will no longer be updated. We recommend using the new IBM DB2 extension for improved functionality and support.
Learn how to monitor IBM DB2 using the Dynatrace ActiveGate extension for IBM DB2.
Starting with Dynatrace OneAgent and ActiveGate version 1.231, we are upgrading the Extension Framework (also referred to as the plugins framework) from Python 3.6 to Python 3.8.
- Consequences: Some Dynatrace extensions running in your environment may stop working and require redeployment of a new version prepared for Python 3.8.
- Symptoms:
No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics.
- Extension logs display errors. Most often this will manifest itself as Python
ModuleNotFoundErrorin the PluginAgent log. Sometimes the Python virtual machine crashes.
- Impact: This issue affects only those extensions that use native libraries called from Python code distributed with the extension.
For remediation details, see Dynatrace Extensions.
Prerequisites
Environment ActiveGate
LUW distribution of IBM DB2
Host and port of the DB2 instance as well as user credentials to set up an endpoint for extension
DB2 user with one of the following permissions: EXECUTE privilege on the routine, DATAACCESS authority, DBADM authority, or SQLADM authority
ActiveGate sizing
During initial testing an ActiveGate instance with 1 CPU and 2 GB RAM was used. Two DB2 instance endpoints were configured for the ActiveGate to monitor. The additional CPU load during extension invocation was measured at 5-10% with no noticeable increase in memory usage.
Extension installation
To install the extension
-
In Dynatrace Hub, select the IBM DB2 for LUW extension.
-
Select Download to get the extension ZIP file. Don't rename the file.
-
Unzip the ZIP file to the
plugin_deploymentdirectory of your Environment ActiveGate host. -
In Dynatrace, go to Settings > Monitoring > Monitored technologies and select Add new technology monitoring > Add ActiveGate extension.
-
Select Upload extension and upload the
custom.remote.python.db2.zipfile. -
After you upload the extension, go to Settings > Monitoring > Monitored technologies and switch to the Custom extensions tab.
-
Find the extension and select it to open it for Endpoint configuration.
-
Enter the endpoint information.
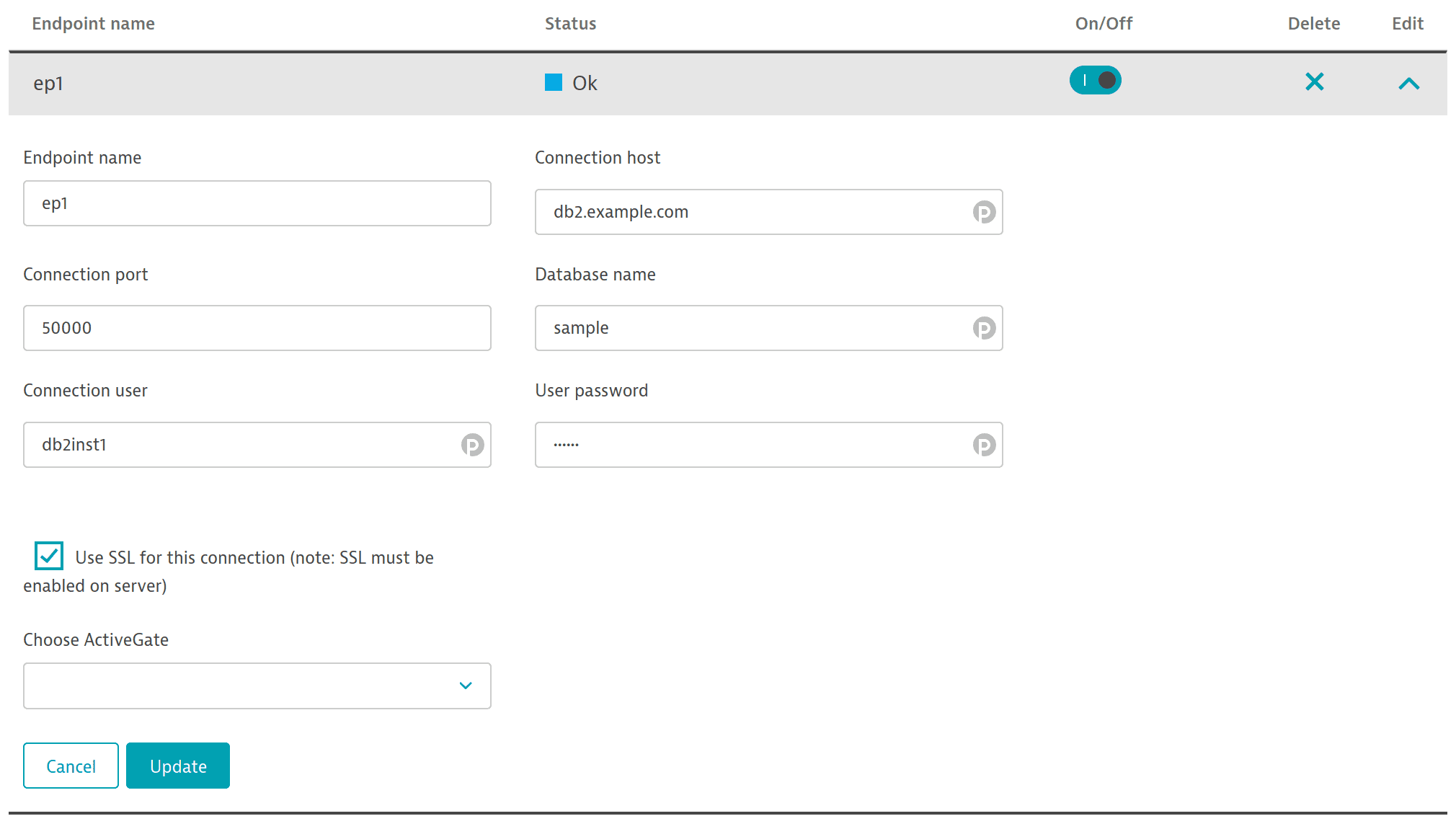
Setting Details Endpoint name
Enter a meaningful endpoint name. The name will only be visible on the configuration page.
Connection host
IP or DNS record pointing to your DB2 installation.
Connection port
Default =
50000Database name
Name of the database through which the connection will be made.
Connection user
User through which the connection will be made. User must have read access to monitoring table functions. Example value for default installation of DB2:
db2inst1. One of the following authorizations is required:EXECUTE privilege on the routine
DATAACCESS authority
DBADM authority
SQLADM authority
User password
Use SSL for this connection
SSL must be enabled on the server.
Choose ActiveGate
Select an Environment ActiveGate from the list.
Troubleshoot ActiveGate extensions
See Troubleshoot ActiveGate extensions.
Metrics
The following metrics are available.
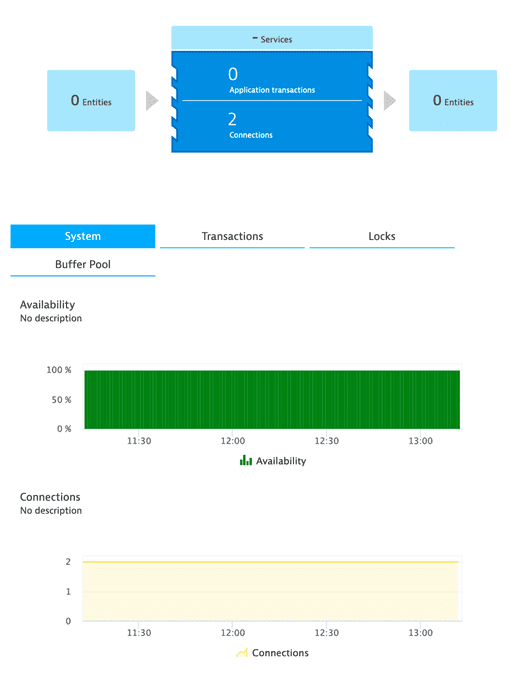
System status
| Metric name | Metric description |
|---|---|
AvailabilityPercent | Instance availability. Data points are reported as 100% for successful metric collection from instance and 0% in case of failure. Data points are later aggregated over the specified period of time. |
ConnectionsCount | Number of connections. Amount of connections to the database since it’s been activated as obtained from TOTAL_CONS value. |
Transactions
| Metric name | Metric description |
|---|---|
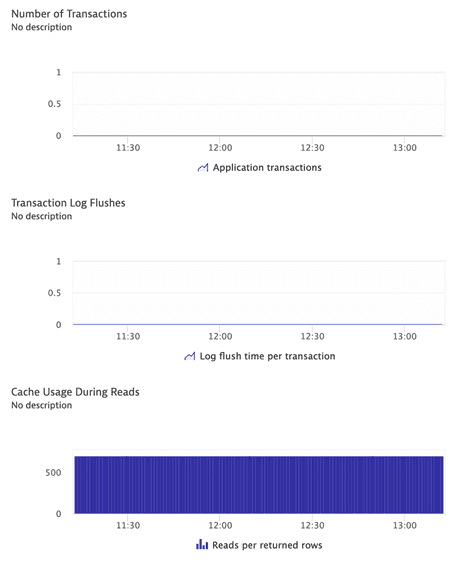
ApplicationTransactionsCount | Number of application transactions executed. This provides an excellent base level measurement of system activity. |
LogFLushTimePerTransactionRatio | The time an agent waits for log records to be flushed to disk. The transaction log has significant potential to be a system bottleneck, whether due to high levels of activity, or to improper configuration, or other causes. By monitoring log activity, you can detect problems both from the Db2 side (meaning an increase in number of log requests driven by the application) and from the system side (often due to a decrease in log subsystem performance caused by hardware or configuration problems). |
TableReadsPerReturnedRowsRatio | Cache usage during transaction reads. This calculation gives an indication of the average number of rows that are read from database tables to find the rows that qualify.
|
SortsPerTransactionRatio | The amount of sort operations per transaction. This is an efficient way to handle sort statistics, because any extra time due to spilled sorts automatically gets included here. |
Locks
| Metric name | Metric description |
|---|---|
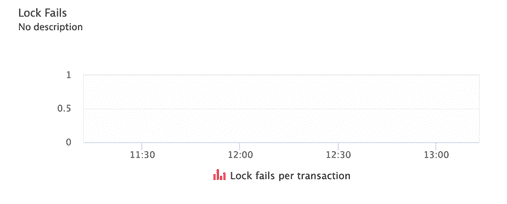
LockFailsPerTransctionRatio | Lock fails (deadlocks and lock timeouts) per transaction. Although deadlocks are comparatively rare in most production systems, lock timeouts can be more common. The application usually has to handle them in a similar way: re-executing the transaction from the beginning. Monitoring the rate at which this happens helps avoid the case where many deadlocks or lock timeouts drive significant extra load on the system without the DBA being aware. |
LockWaitPerTransactionRatio | Lock wait time per transaction. Excessive lock wait time often translates into poor response time, so it is important to monitor. The value is normalized to one thousand transactions because lock wait time on a single transaction is typically quite low. Scaling up to one thousand transactions provides measurements that are easier to handle. |
Buffer pool
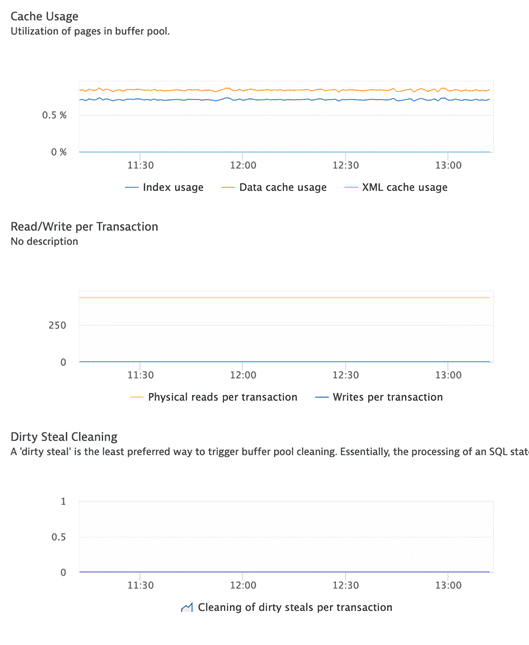
Buffer pool hit ratios, measured separately for data, index, XML storage object, and temporary data.
Buffer pool hit ratios are one of the most fundamental metrics and give an important overall measure of how effectively the system is exploiting memory to avoid disk I/O. Hit ratios of 80-85% or better for data and 90-95% or better for indexes are generally considered good for an OLTP environment, and of course these ratios can be calculated for individual buffer pools using data from the buffer pool snapshot.
Although these metrics are generally useful, for systems such as data warehouses that frequently perform large table scans, data hit ratios are often irretrievably low, because data is read into the buffer pool and then not used again before being evicted to make room for other data.
| Metric name | Metric description |
|---|---|
PoolIndexPageHitsPercent | Index pages usage. |
PoolDataPageHitsPercent | Data pages usage. |
PoolXdaPageHitsPercent | XML storage object (XDA) pages usage. |
PoolPhysicalReadsPerTransaction and PoolWritesPerTransaction | Pool physical reads and writes per transaction. These metrics are closely related to buffer pool hit ratios but have a slightly different purpose. Although you can consider target values for hit ratios, there are no possible targets for reads and writes per transaction. Why bother with these calculations?
These metrics are not just physical reads and writes, but are normalized per transaction. This trend is followed through many of the metrics. The purpose is to decouple metrics from the length of time data was collected, and from whether the system was very busy or less busy at that time. In general, this helps ensure that similar values for metrics are obtained, regardless of how and when monitoring data is collected. Some amount of consistency in the timing and duration of data collection is a good thing; however, normalization reduces it from being critical to being a good idea. |
PoolCleaningDirtyStealPerTransaction | Number of ‘dirty steal’ triggers per transaction. A "dirty steal" is the least preferred way to trigger buffer pool cleaning. Essentially, the processing of an SQL statement that is in need of a new buffer pool page is interrupted while updates on the victim page are written to disk. If dirty steals are allowed to happen frequently, they can have a significant affect on throughput and response time. |