Resource events
This page provides information about supported resource events and the logic behind raising them.
![]()
Alerts on the infrastructure level for AIX hosts out of the box are not supported.
Unexpected high traffic
UNEXPECTED_HIGH_LOAD
Dynatrace collects a multidimensional baseline for application and user action traffic and thereby learns the typical traffic patterns of all your applications and user actions. Alerting on abnormal high application traffic is an opt-in option in application settings at Settings > Anomaly detection > Applications.
If enabled, Dynatrace follows a two-seasonal pattern (daily and weekly) in alerting on abnormal traffic situations. The actual monitored application traffic is compared with the same period of last week and alerts if the comparison reports unusually high traffic.
See a typical unexpected high traffic event example below.
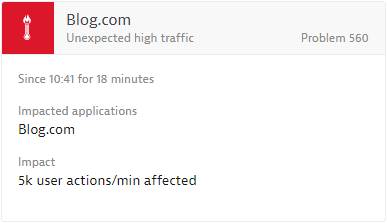
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Service
Application
Mobile application
CPU saturation
CPU_SATURATED
Dynatrace does not support CPU saturation events on AIX. As a workaround, you can configure custom alerts based on host metrics. Examples:
CPU idle: For example, raise an alert if the metric is below 10% for 5 minutes during a 5-minute period.CPU wait: For example, raise an alert if the metric exceeds 90%.
The above values are examples. Replace them as needed to suit your requirements.
CPU saturation events are raised on the host level when CPU usage rises above a critical threshold.
-
By default, Dynatrace alerts when average CPU usage is higher than 95% in 18 of 30 consecutive 10-second intervals or when usage is higher than 90% in a single five-minute interval.
-
Along with the typical OneAgent-related CPU saturation event, AWS cloud management can report CPU saturation events for EC2 instances. In the case of a OneAgent-monitored EC2 instance, Dynatrace prioritizes OneAgent events over AWS events. If one of your EC2 instances isn't monitored by OneAgent, but you have an active AWS integration and Dynatrace setup, a CPU saturation event will be raised.
See a typical CPU saturation event example below.
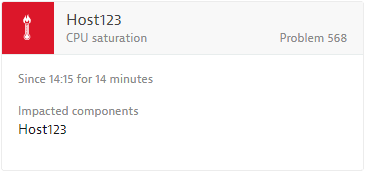
The screenshot below shows a CPU saturation event, raised through AWS integration.
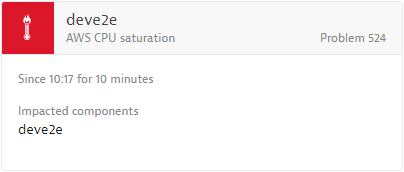
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Host
Hypervisor
Relational database service
Memory saturation
MEMORY_SATURATED
Dynatrace does not support memory saturation events on AIX.
-
Windows: By default, Dynatrace alerts if memory usage is higher than 90% and the memory page fault rate is higher than 100 faults/s within 18 of 30 10-second intervals.
-
Linux: By default, Dynatrace alerts if memory usage is higher than 80% and the memory page fault rate is higher than 20 faults/s within 18 of 30 10-second intervals.
See example below:
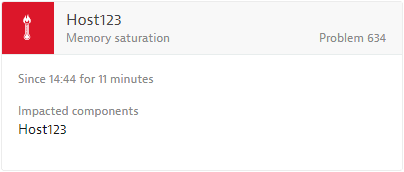
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Host
Hypervisor
Relational database service
Low disk space
LOW_DISK_SPACE
By default, Dynatrace alerts if free disk space on any of your disks falls below 3% in at least 18 of 30 10-second observation intervals.
Disk thresholds within Dynatrace are highly configurable, both at the host level and the global settings level. To support large numbers of disks, you can define global disk threshold rules along with flexible tag filters to group subsets of hosts.
See a typical low disk space event example below.
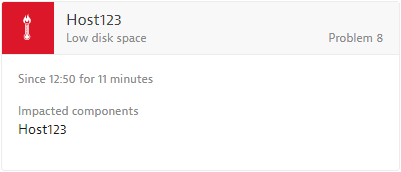
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Host
Slow disk
SLOW_DISK
By default, Dynatrace alerts if disk read or write time on any of your disks is higher than 200ms in at least 18 of 30 10-second observation intervals.
Disk thresholds in Dynatrace are highly configurable, both at the host level and the global settings level. To support large numbers of disks, you can define global disk threshold rules along with flexible tag filters to group subsets of hosts.
See a typical slow disk event example below.
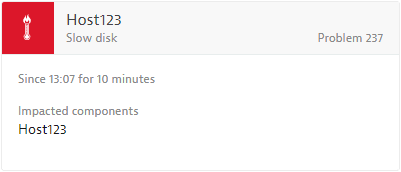
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Host
Hypervisor
Low number of inodes available
HOST_DISK_LOW_INODES
By default, Dynatrace alerts if the percentage of available inodes on any of your disks is lower than 5% in at least 18 of 30 10-second observation intervals.
Disk thresholds within Dynatrace are highly configurable, both on the host level and the global settings level. To support large numbers of disks, you can define global disk threshold rules along with flexible tag filters to group subsets of hosts.
See a typical low number of inodes available event example below.
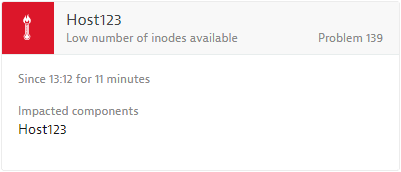
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Host
High network utilization
HIGH_NETWORK_UTILIZATION
By default, Dynatrace alerts if sent/received traffic utilization is higher than 90% in 18 of 30 10-second observation intervals.
See a typical high network utilization event example below.
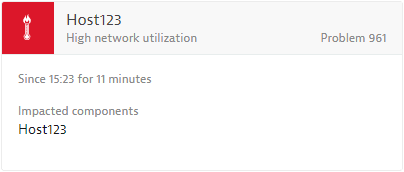
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Host
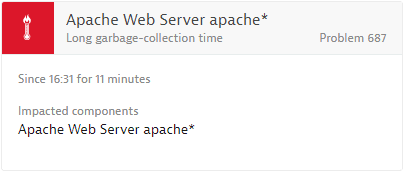
Long garbage-collection time
HIGH_GC_ACTIVITY
By default, Dynatrace alerts on long garbage-collection times if, in 18 of 30 10-second observation intervals, garbage-collection time is higher than 40% or suspension is higher than 25%.
This event is not triggered for processes running on non-OS module deployments such as Solaris and z/OS.
See a typical long garbage-collection time event example below.
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Process group instance
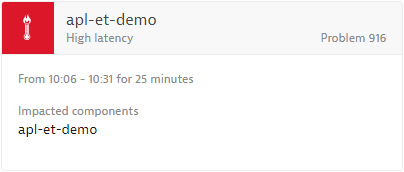
High latency
HIGH_LATENCY
By default, Dynatrace detects and alerts on high latency within your relational database services (RDS).
See a typical high latency event example below.
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Relational database service
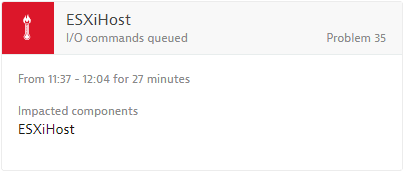
I/O commands queued
INSUFFICIENT_DISK_QUEUE_DEPTH
Applicable Dynatrace entities
The following Dynatrace entities apply to this event:
Hypervisor
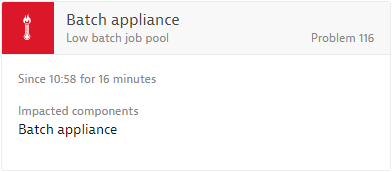
Custom resource contention event
RESOURCE_EVENT
This generic resource contention event can be used by monitoring plugins or through the Dynatrace REST API to raise a customized resource contention event with a user-defined title.
An example might be a custom resource contention event with a user-defined title Low batch job pool, as shown below:
Applicable Dynatrace entities
All Dynatrace entities apply to this event.