Metric events
Dynatrace Davis® AI automatically analyzes abnormal situations within your IT infrastructure and attempts to identify any relevant impact and root cause. Davis relies on a broad spectrum of information sources, such as a transactional view of your services and applications, as well as all events raised on individual nodes within your Smartscape® topology. One of the sources for events in Dynatrace is metric events, that is, events based on metric data. They are configured in the global settings of your environment and are visible to all Dynatrace users in your environment. There are two types of metric events based on how the metric is queried for event evaluation:
- Metric key. Metric key events evaluate the incoming measures of a single metric. You can use only static thresholds with this query type.
- Metric selector. Metric selector events evaluate a complex query defined by the selector. This query type can include historical data and even arithmetic operations with multiple metrics.
Dynatrace uses three monitoring strategies for such events:
- Static threshold—the threshold that doesn't change over time.
- Auto-adaptive threshold—Dynatrace calculates the threshold automatically and adapts it dynamically to your metric's behavior.
- Seasonal baseline—Dynatrace calculates a confidence band for a metric with seasonal patterns.
Auto-adaptive thresholds and seasonal baselining are available only for metric selector events.
- The number of metric event configurations (both metric key and metric selector) is limited to 10,000.
Event duration
In the configuration of a metric event, you specify how many one-minute samples must violate the threshold during a specific period (the sliding window). When the specified number of violations is reached, Dynatrace raises an event. The goal is to avoid overly aggressive alerting on single violations, avoiding situations in which every measurement that violates the threshold raises an event.
The event remains open until the metric stays within the threshold for a certain number of one-minute samples within the same sliding window, at which point Dynatrace closes the event. Keeping the event open helps to avoid over-alerting by adding new threshold violations to an existing problem instead of raising a new one.
You can find settings for the sliding window in the Advanced model properties section of the metric event configuration. By default, any three one-minute samples out of five must violate your threshold to raise an event; and five one-minute samples must be back to normal to close this event. You can set a sliding window of up to 60 minutes. Let's consider a case of a static threshold of 90% CPU usage.
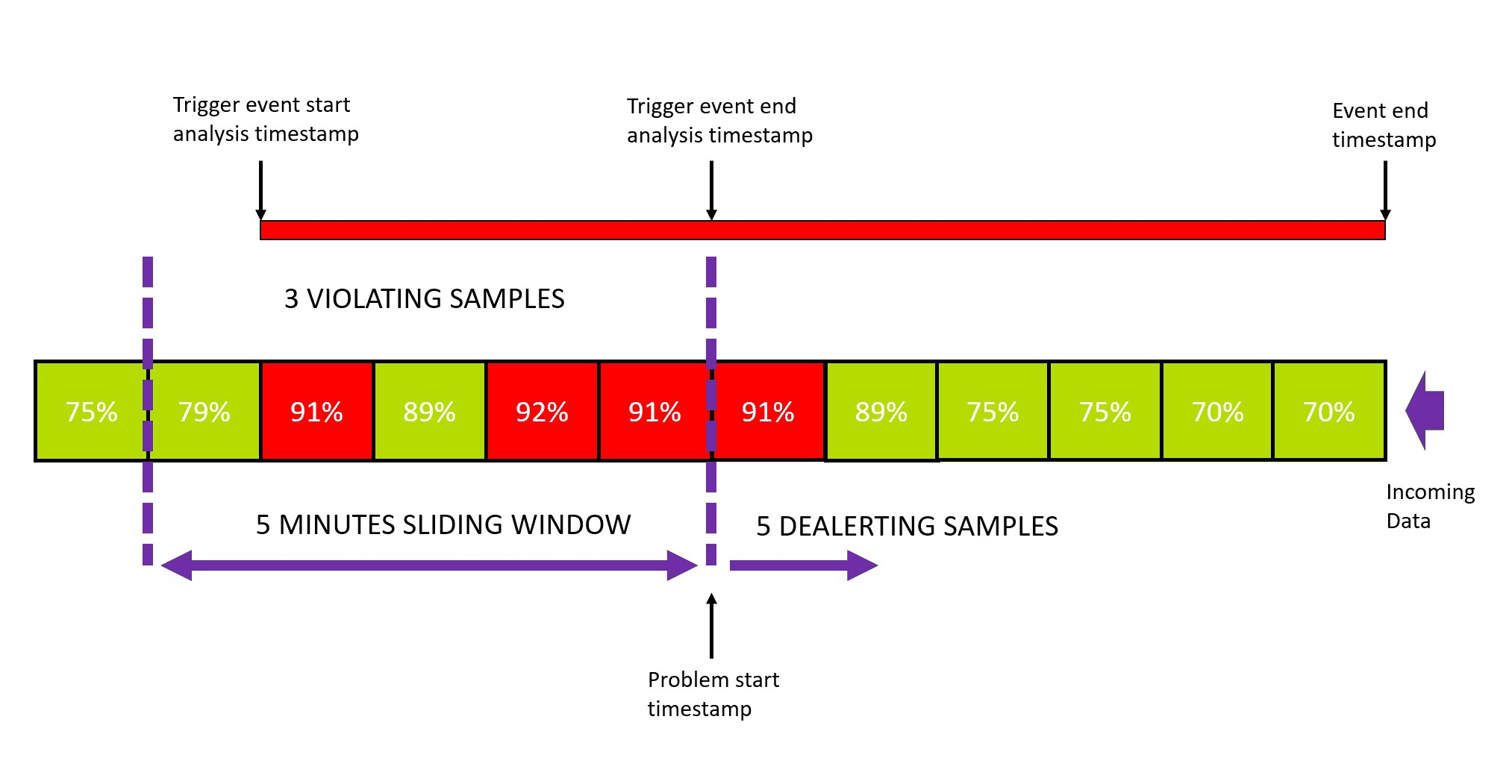
The event analysis starts with the first violating sample in the sliding window. Once the number of violating samples reaches the defined threshold, the event analysis stops, and a problem is raised. Even though event analysis is stopped, the event itself remains open until de-alerting criteria are fulfilled:
The number of violating samples must be lower than the number to raise the problem.
The number of "normal" samples must be greater than or equal to the number of de-alerting samples.
Both criteria must be fulfilled to close the event.
The default numbers (3 violating samples in the sliding window of 5 samples to trigger a problem, 5 de-alerting samples to close the event) are a good fit for most metric events. However, you might need to update them (for example, due to noise in measurements). The preview of a metric event provides a visual representation of your event's behavior. You can adjust the sliding window settings to see how they affect your event configuration.
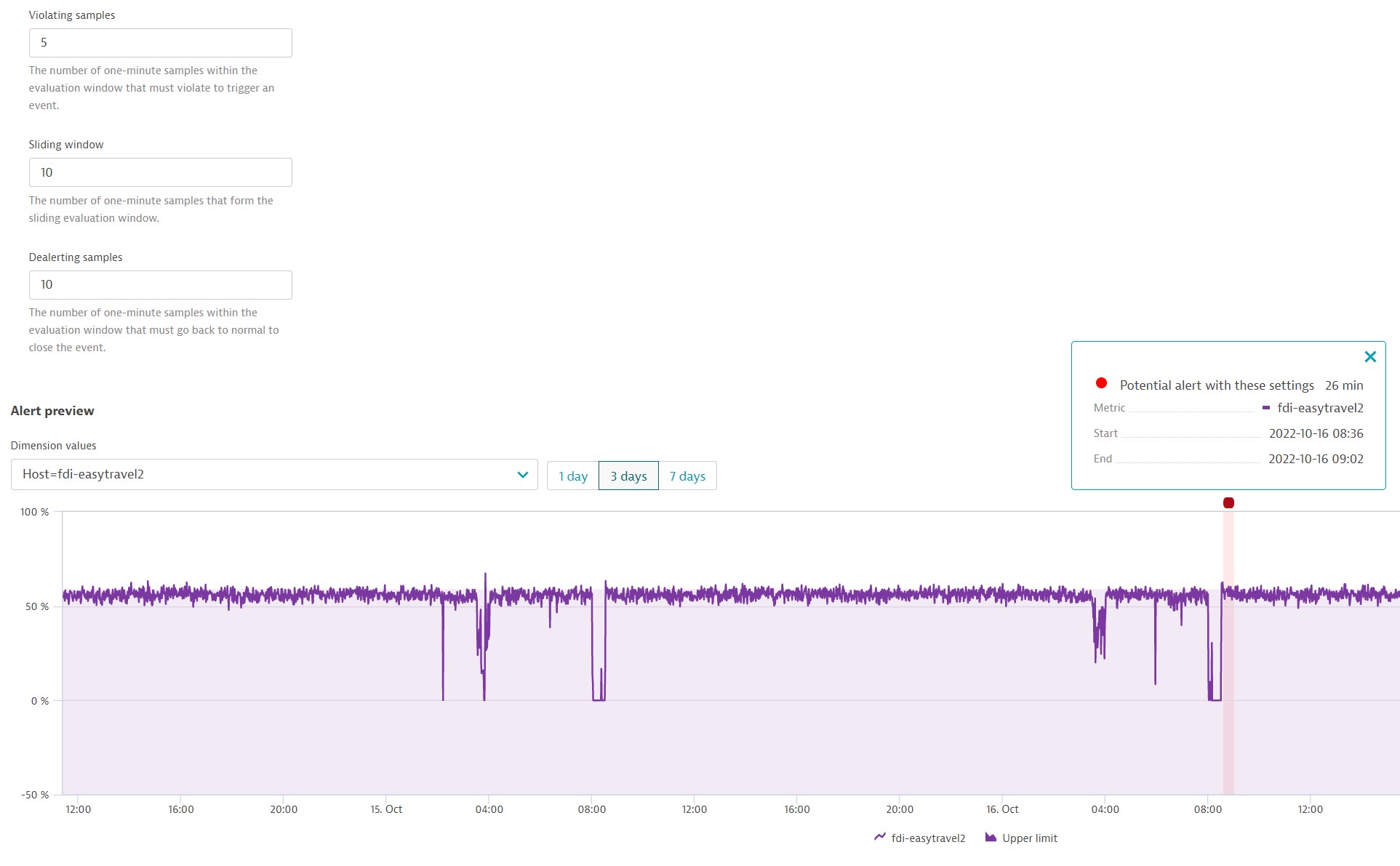
Event severity
The severity of an event determines if a problem should be raised and if Davis AI should determine the root cause of the given event.
| Severity | Problem raised | Davis analysis | Semantic |
|---|---|---|---|
| Availability | Yes | Yes | Reports any kind of severe component outage. |
| Error | Yes | Yes | Reports any kind of degradation of operational health due to errors. |
| Slowdown | Yes | Yes | Reports a slowdown of an IT component. |
| Resource | Yes | Yes | Reports a lack of resources or a resource-conflict situation. |
| Info | No | Yes | Reports any kind of interesting situation on a component, such as a deployment change. |
| Custom alert | Yes | No | Triggers an alert without causation and Davis AI involved. |
For more information about built-in events and their severity levels, see Categories of events.
Management zones in metric events
Dynatrace version 1.261+
If you have management-zone-level permissions, you can create metric event configurations that are tied to these management zones. Such configurations use only data coming from the specified management zone. You can also see all management zone configurations that use the management zone you have access to.
To create metric events without management zone scopes, you need admin access.
Management zones set up via dimensional data rules are not supported for metric events.
Topology awareness
Topology awareness and context are the key themes of the Dynatrace observability platform. Data—such as metrics, traces, events, and logs—is not simply reported and stored within the platform. Such data is rich with references to the topology where the data originated. For example, with process metrics, each measurement references the associated hosts and processes. Davis AI uses this topological information to automatically perform root cause detection and impact analysis for detected anomalies. The same applies to all metric events in your environment.
When an anomaly detection configuration raises an event, Dynatrace automatically identifies the most relevant entity to map the event to. If multiple entity references are detected, the most relevant one is automatically selected. For example, if a metric with reference to both a host and a process leads to an event, the event is raised on the process.
Metric ingestion enables you to submit all types of metric measurements, regardless of the number of entities they relate to. The following scenarios exist:
Measurements aren't related to any entity
If you define a metric event on a non-topological metric, the resulting event will be raised on the monitoring environment itself, and not on a specific Smartscape entity.
business.revenue,shop=shop111,city=NewYork 234business.revenue,shop=shop999,city=Atlanta 499
Measurements are related to a single entity
If you define a metric event on a measurement that is related to a single entity, the resulting event will be raised on that entity.
Measurements are related to multiple entities
When multiple entities are specified for each measurement, Dynatrace selects the most appropriate entity on which it should raise the event. In the case of a host and a process, the measurement presumably relates to the process rather than the host, so the event is raised on the process.
Metric events overview
Dynatrace provides an overview of all your metric events, with information about limitations and metric event failures within the last 24 hours. To access the overview, go to Settings > Anomaly detection > Metric events.
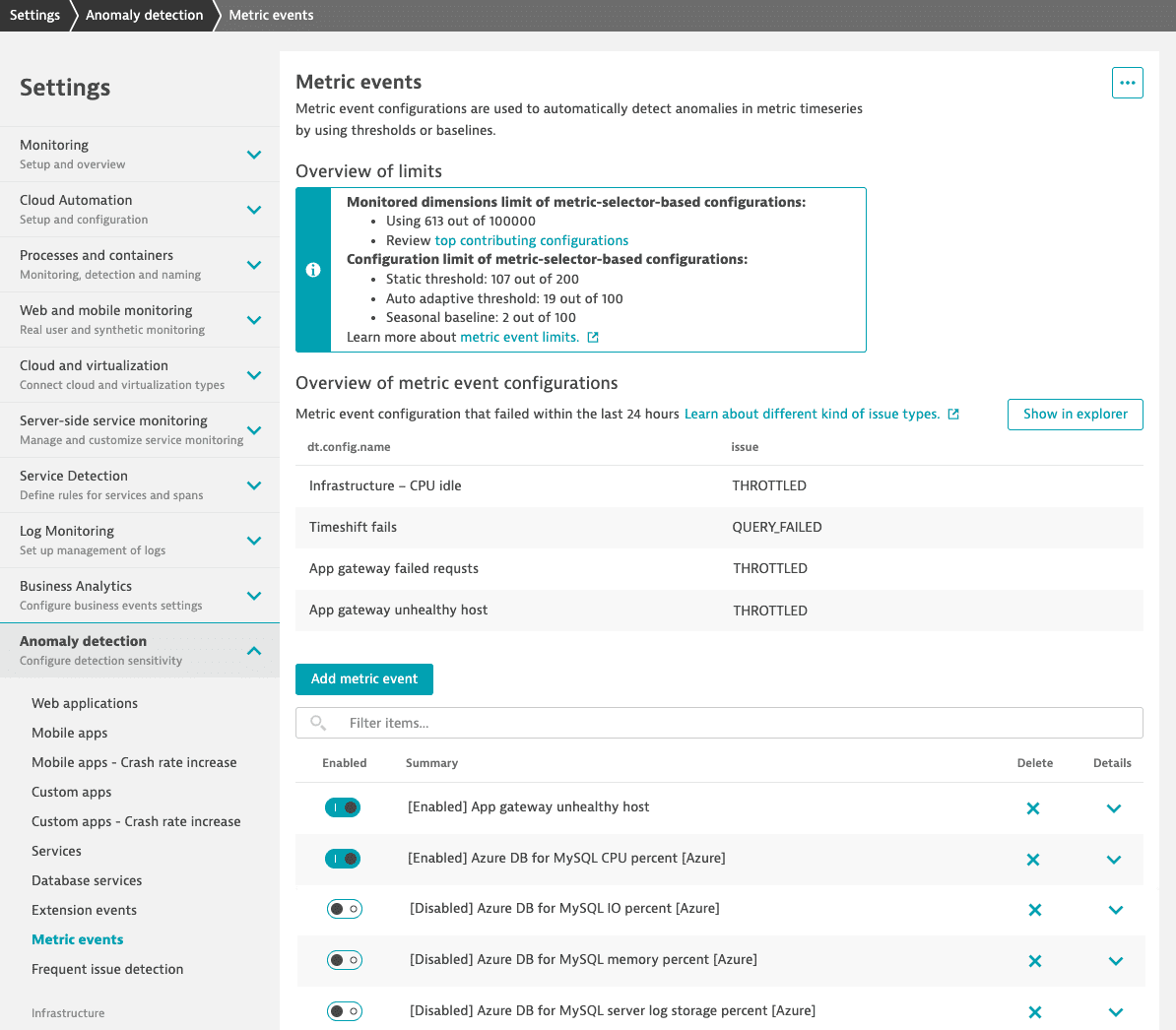
The overview of limits tells you how much of each limit type has been consumed. The review link takes you to Data Explorer with a pre-filled query set to display top-consuming configurations.
The metric events overview includes the configurations that experienced issues during the last 24 hours. Monitored issues include:
THROTTLED: The configuration reached the query limits of the metric selector.QUERY_FAILED: The metric query of the configuration has failed. Here are some possible reasons for query failure:Management zones or tags are no longer available.
Metric data is no longer available.
The queried data is not available in 1-minute resolution.