Problem impact
The impact level of a problem defines whether or not an abnormal situation is affecting infrastructure (INFRASTRUCTURE), software services (SERVICE), or user-facing applications (APPLICATION).
A fourth, special impact level (ENVIRONMENT) is used to classify a general problem in the monitoring environment. These problems are used to report an interruption of your Dynatrace monitoring or ActiveGates. See the following section for details about Monitoring interruptions. Within the Dynatrace problem feed, these three major impact levels are shown for each detected problem. The impact level can also be used to filter the feed of problems within your environment, as shown within the screenshot below:
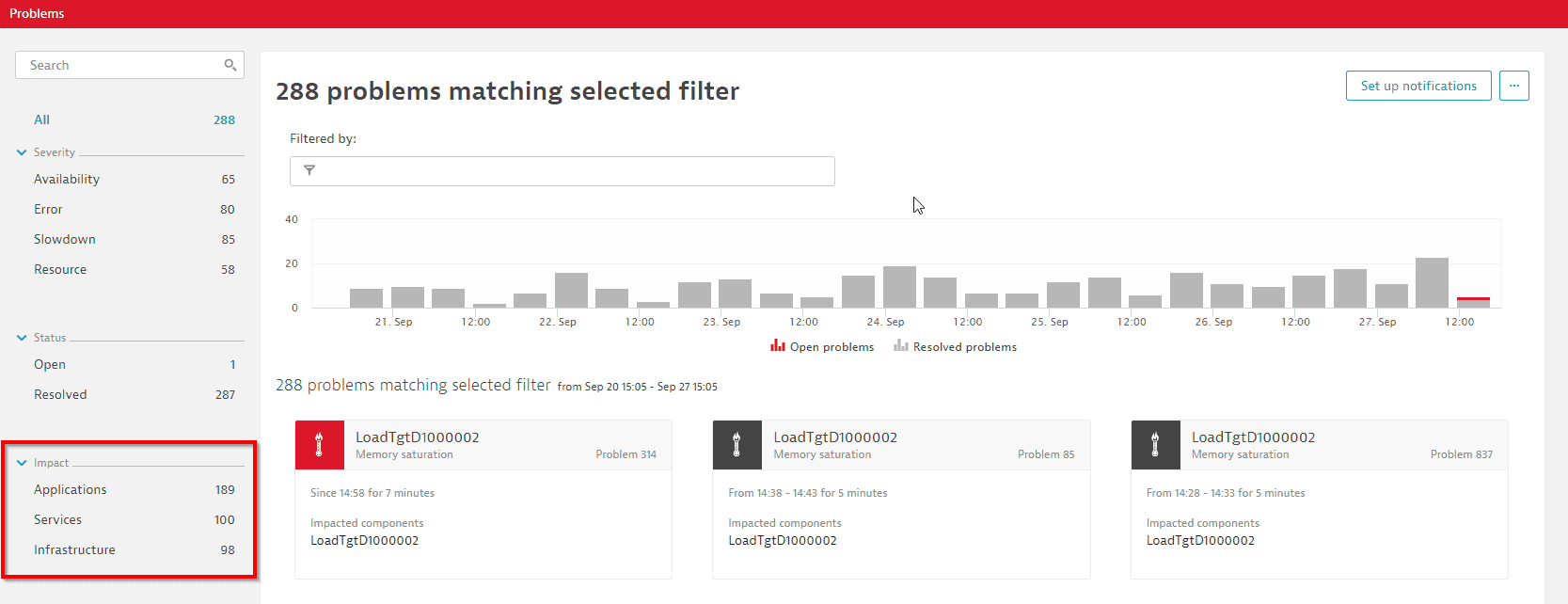
A problem follows a defined lifecycle and therefore the problems impact level can increase from infrastructure only, to the service, and application levels. The impact level of a problem is always derived from the individual impact levels of the involved entities within the abnormal situation.
Each entity that's shown on the host or process level within Smartscape is classified as infrastructure. Each event raised by those hosts or processes automatically leads to an infrastructure event and therefore opens an infrastructure type of problem.
Services that are shown within their own level within Smartscape automatically lead to service level events. In case a service reports a slowdown or an error, a service impact level problem is raised. Real-user facing web, mobile, or custom applications are shown within the application level in Smartscape. Any real-user facing problems lead to an application impact level problem. See below the classification of impact level of entities shown along the Smartscape:
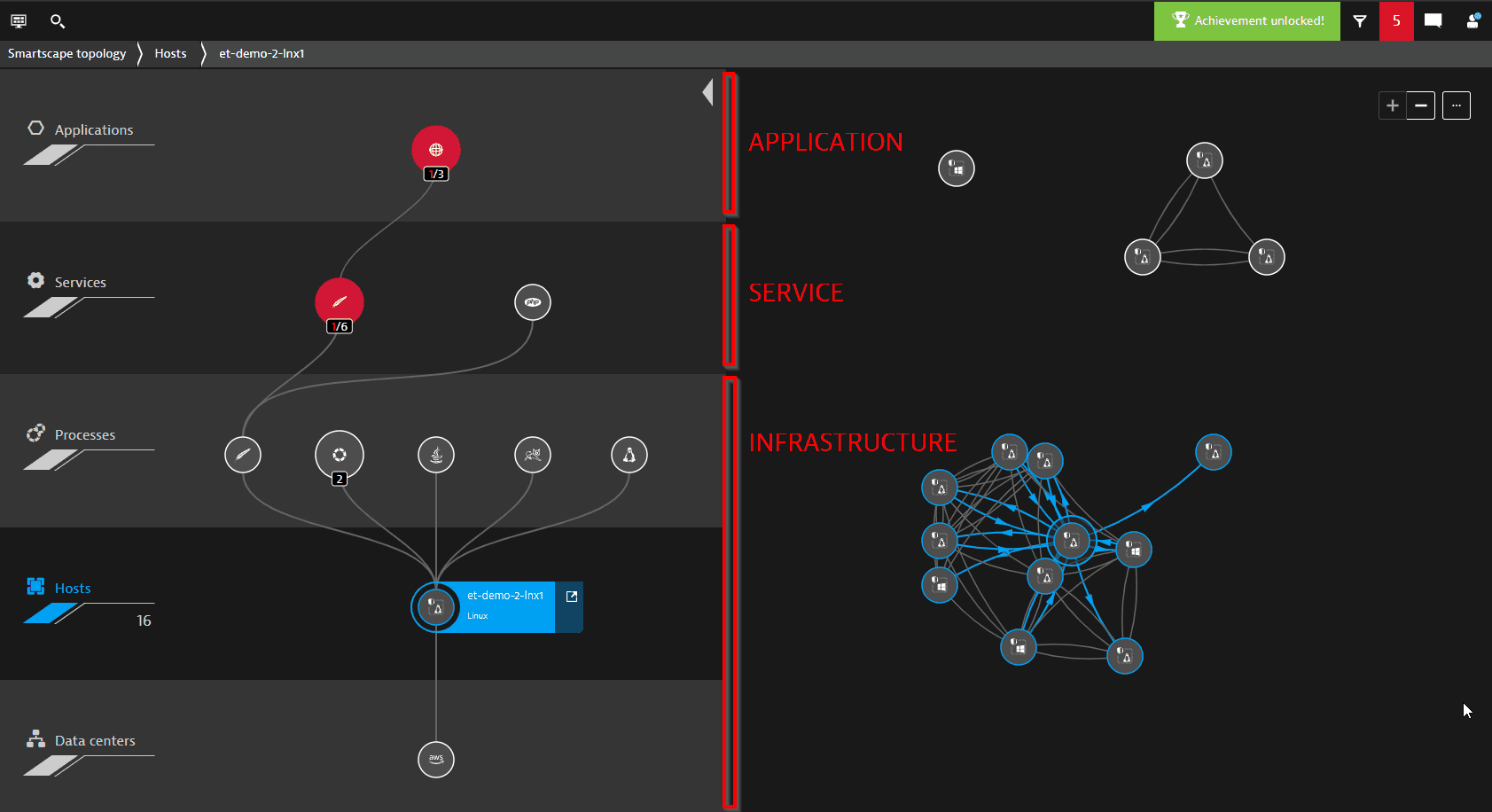
Let’s assume Dynatrace detected and reported a CPU spike on one of your monitored hosts. No service or any application is affected. In this case the problem is reported on the infrastructure impact level. If the CPU spike negatively impacts a running service in terms of decreased performance or increase in errors, a service level event is added to the opened problem. The problem then automatically increases its impact level to SERVICE level.
Note that each impact level is not exclusive. A problem can at the same time affect INFRASTRUCTURE as well as SERVICE-level entities. Therefore, the same problem will be returned as an INFRASTRUCTURE as well as SERVICE-level problem within the problem feed. Within all alerting channels (such as ServiceNow, email, or Slack) a problem is assigned with the highest level impacted.
Another aspect to note is that a problem can affect a service, while not affecting any underlying infrastructure. In such cases, the problem is classified as a SERVICE-level only problem. This situation can appear in serverless scenarios as well as in cases where no clear root-cause can be found on any underlying infrastructure.