Problem analysis and root cause detection
Problems in Dynatrace represent anomalies in normal behavior or state. Such anomalies can be, for example, a slow service response or user login process. Whenever a problem is detected, Dynatrace raises a specific problem event indicating such an anomaly.
Raised problems provide insight into their underlying root causes. To identify the root causes of problems, Dynatrace follows a context-aware approach that detects interdependent events across time, processes, hosts, services, applications, and both vertical and horizontal topological monitoring perspectives. Only through such a context-aware approach is it possible to pinpoint the true root causes of problems. For this reason, newly detected anomalous events in your environment won't necessarily result in the immediate raising of a new problem.
Events represent different types of individual detected anomalies, such as metric-threshold breaches, baseline degradations, or point-in-time events, such as process crashes. Dynatrace also detects and processes informational events such as new software deployments, configuration changes, and other event types.
A problem might result from a single event or multiple events, which is often the case in complex environments. To prevent a flood of seemingly unrelated problem alerts for related events in such environments, Dynatrace Davis® AI correlates all events that share the same root cause into a single, trackable problem. This approach prevents event and alert spamming.
Problems have defined lifespans and are updated in real-time with all incoming events and findings. Once a problem is detected, it's listed in your problems feed.
Problem detection
Dynatrace continuously measures incoming traffic levels against defined thresholds to determine when a detected slowdown or error-rate increase justifies the generation of a new problem event. Rapidly increasing response-time degradations for applications and services are evaluated based on sliding 5-minute time intervals. Slowly degrading response-time degradations are evaluated based on 15-minute time intervals.
Understanding thresholds
Dynatrace utilizes two types of thresholds:
- Automated baselines: Multidimensional baselining automatically detects individual reference values that adapt over time. Automated baseline reference values are used to cope with dynamic changes within your application or service response times, error rates, and load.
- Anomaly detection: Dynatrace automatically detects infrastructure-related performance anomalies such as high CPU saturation and memory outages.
The methodology used for raising events with automated baselining is completely different from anomaly detection. Anomaly detection offers a simple and straightforward approach to defining baselines that works immediately without requiring a learning period. We don't recommend host anomaly detection due to the following limitations:
Too much manual configuration is required for specific service methods or user actions.
Difficulty in setting thresholds for dynamic services.
Inability to adapt to changing environments.
The preferred automated, multidimensional baselining approach works out of the box, without manual configuration of thresholds. Most importantly, it automatically adapts to changes in traffic patterns.
Note that Dynatrace allows you to adjust the sensitivity of problem detection either by adapting the thresholds or by deviating from automated baselines.
Problem analysis
Once a problem is detected, you can directly analyze its impact on the problem's overview page. Dynatrace offers both user and business impact analysis. The problem overview page also provides root cause analysis.
Root cause analysis
To identify the root cause of a problem, Dynatrace follows a context-aware approach to detect interdependent events across time, processes, hosts, services, applications, and both vertical and horizontal topological monitoring perspectives.
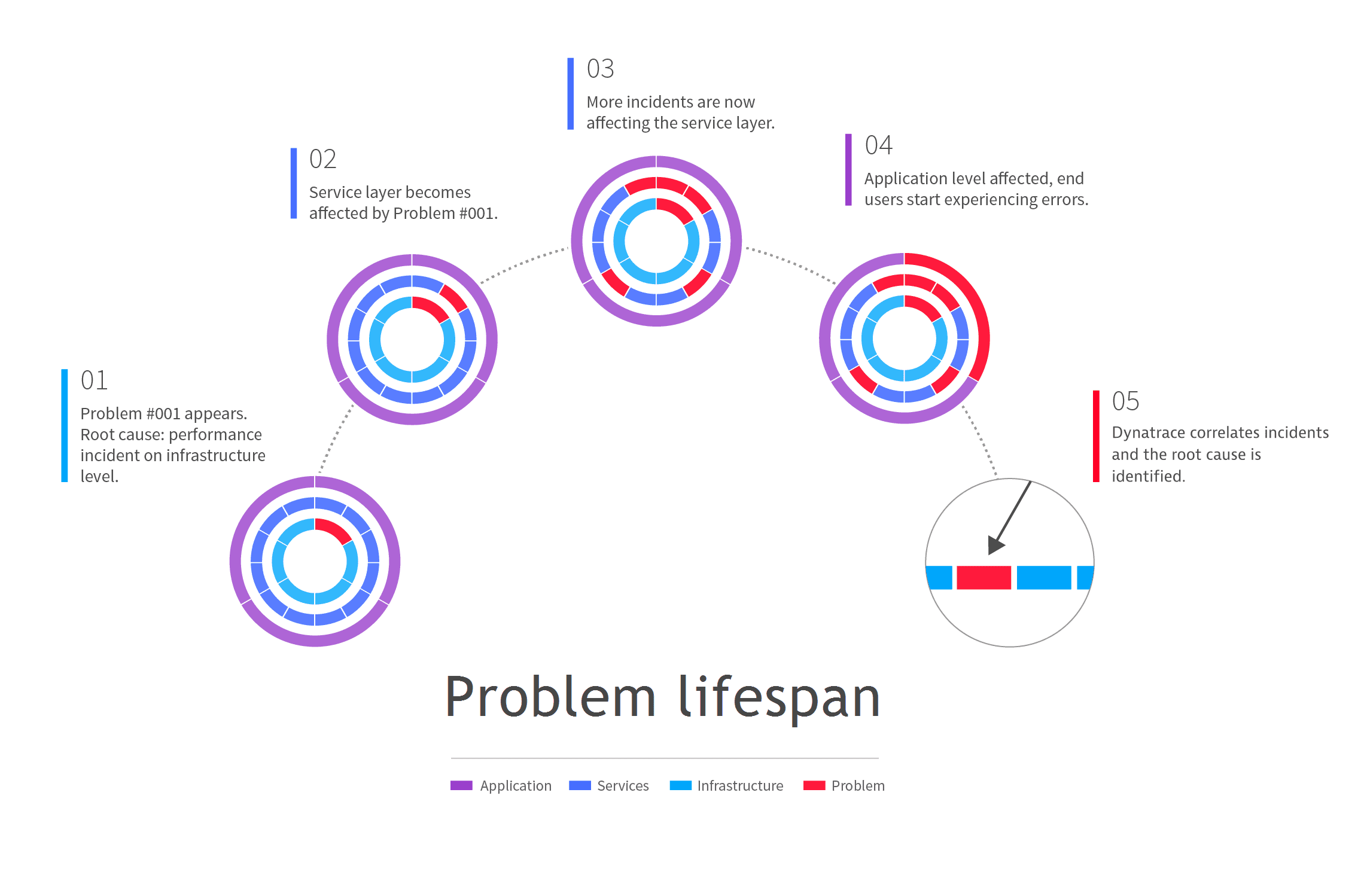
The following scenario involves a problem that has as its root cause a performance incident in the infrastructure layer.
-
Dynatrace detects an infrastructure-level performance incident. A new problem is created for tracking purposes and a notification is sent out via the Dynatrace mobile app.
-
After a few minutes, the infrastructure problem leads to the appearance of a performance degradation problem in one of the application's services.
-
Additional service-level performance degradation problems begin to appear. So what began as an isolated infrastructure-only problem has grown into a series of service-level problems that each have their root cause in the original incident in the infrastructure layer.
-
Eventually the service-level problems begin to affect the user experience of your customers who are interacting with your application via desktop or mobile browsers. At this point in the problem life span, you have an application problem with one root cause in the infrastructure layer and additional root causes in the service layer.
-
Because Dynatrace understands all the dependencies in your environment, it correlates the performance degradation problem your customers are experiencing with the original performance problem in the infrastructure layer, thereby facilitating quick problem resolution.
Duplicate problems
When Dynatrace Davis AI detects multiple problems that occur within 30 minutes of one another and share the same root cause, the problems are identified as duplicates.
When this happens before the problems are displayed in the Dynatrace web UI, the problems are consolidated into a single problem.
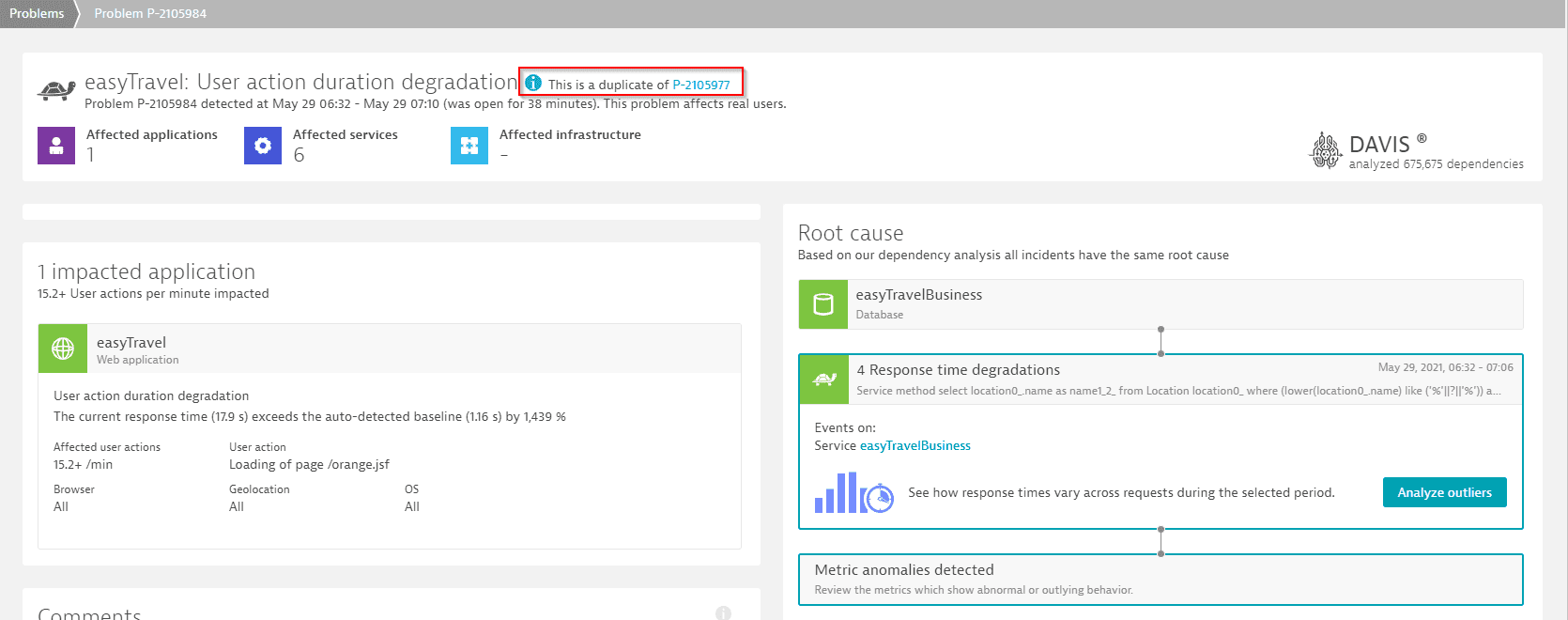
- If the problems are identified as duplicates after they are displayed in the Dynatrace web UI, Dynatrace will assign one as the primary problem and hide the duplicate problems. Problem backlinks still work for hidden, duplicate problems. Hidden, duplicate problem pages display the message This is a duplicate of [problem ID] and include a link to the primary problem.
Example duplicate problem showing navigation to primary problem:
Problem alerting
Upon the detection of an anomaly, Dynatrace can generate an alert to notify the responsible team members that a problem exists. Dynatrace allows you to set up fine-grained alert-filtering rules that are based on the severity, customer impact, associated tags, and/or duration of detected problems. These rules essentially allow you to define a problem alerting profile. Through alerting profiles, you can also set up filtered problem-notification integrations with 3rd party messaging systems like Slack, HipChat, and PagerDuty.
Your feedback
It's easy to submit feedback on a problem analysis and resolution.
-
In the upper-right corner of the problem details page, select Share feedback.
-
Select the thumbs-up or thumbs-down icon to let us know whether Dynatrace met your expectations.
-
optional Add a comment. We know you're busy, but if you have the time, we would like to know the reason behind your rating. What went right? What went wrong? What do you think we should change?
-
Select Submit feedback.
A similar feedback window pops up every third time you close problem analysis mode.
The Dynatrace product team regularly reviews this feedback so that we can identify any quality issues and assess the problems detected. We don't use your feedback for purposes such as automated AI training. We just want to know what you think, especially if you have ideas on how to make Dynatrace work better for you. We can't guarantee to implement every suggestion we hear, but all feedback is important to us.