
If cloud-native technologies and containers are on your radar, you’ve likely encountered Docker and Kubernetes and might be wondering how they relate to each other. Is it Kubernetes vs Docker or Kubernetes and Docker—or both?
What is the difference between Kubernetes and Docker?
Docker is a suite of software development tools for creating, sharing and running individual containers; Kubernetes is a system for operating containerized applications at scale.
Think of containers as standardized packaging for microservices with all the needed application code and dependencies inside. Creating these containers is the domain of Docker. A container can run anywhere, on a laptop, in the cloud, on local servers, and even on edge devices.
A modern application consists of many containers. Operating them in production is the job of Kubernetes. Since containers are easy to replicate, applications can auto-scale: expand or contract processing capacities to match user demands.
Docker and Kubernetes are mostly complementary technologies—Kubernetes and Docker. However, Docker also provides a system for operating containerized applications at scale, called Docker Swarm—Kubernetes vs Docker Swarm. Let’s unpack the ways Kubernetes and Docker complement each other and how they compete.
What is Docker?
Just as people use Xerox as shorthand for paper copies and say “Google” instead of internet search, Docker has become synonymous with containers. Docker is more than containers, though.
Docker is a suite of tools for developers to build, share, run and orchestrate containerized apps.
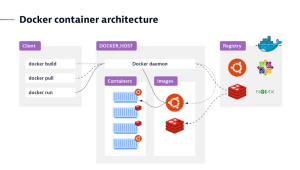
How does Docker work?
In Docker’s client-server architecture, the client talks to the daemon, which is responsible for building, running, and distributing Docker containers. While the Docker client and daemon can run on the same system, users can also connect a Docker client to a remote Docker daemon.
Developer tools for building container images
Docker Build creates a container image, the blueprint for a container, including everything needed to run an application – the application code, binaries, scripts, dependencies, configuration, environment variables, and so on. Docker Compose is a tool for defining and running multi-container applications. These tools integrate tightly with code repositories (such as GitHub) and continuous integration and continuous delivery (CI/CD) pipeline tools (such as Jenkins).
Sharing images
Docker Hub is a registry service provided by Docker for finding and sharing container images with your team or the public. Docker Hub is similar in functionality to GitHub.
Running containers
Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux, and Windows servers, the cloud, and on edge devices. Docker Engine is built on top containerd, the leading open source container runtime, a project of the Cloud Native Computing Foundation (CNCF).
Built-in container orchestration
Docker Swarm manages a cluster of Docker Engines (typically on different nodes) called a swarm. Here the overlap with Kubernetes begins.
What is Kubernetes?
Kubernetes is an open source container orchestration platform for managing, automating, and scaling containerized applications. Kubernetes is the de facto standard for container orchestration because of its greater flexibility and capacity to scale, although Docker Swarm is also an orchestration tool.
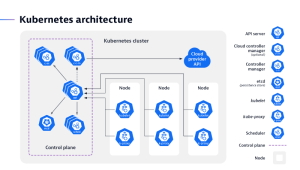
How does Kubernetes work?
A Kubernetes cluster is made up of nodes that run on containerized applications. Every cluster has at least one worker node. The worker node hosts the pods, while the control plane manages the worker nodes and pods in the cluster.
What is Kubernetes used for?
Organizations use Kubernetes to automate the deployment and management of containerized applications. Rather than individually managing each container in a cluster, a DevOps team can instead tell Kubernetes how to allocate the necessary resources in advance.
Where Kubernetes and the Docker suite intersect is at container orchestration. So when people talk about Kubernetes vs. Docker, what they really mean is Kubernetes vs. Docker Swarm.
Benefits of using Kubernetes and Docker
When used together, Kubernetes and Docker containers can provide several benefits for organizations that want to deploy and manage containerized applications at scale.
Some of the key benefits of using include:
- Scalability: Kubernetes can scale containerized applications up or down as needed, ensuring they always have the resources they need to perform optimally. This is helpful for applications that experience a boost in traffic or demand.
- High availability: Kubernetes can ensure that containerized applications are highly available by automatically restarting containers that fail or are terminated. This can keep applications running smoothly and prevent downtime.
- Portability: Docker containers are portable, meaning they can be easily moved from one environment to another. This makes it easy to deploy containerized applications across different infrastructures, such as on-premises servers, public cloud providers, or hybrid environments.
- Security: Kubernetes can secure containerized applications by providing role-based access control, network isolation, and container image scanning. This can help to protect applications from unauthorized access, malicious attacks, and data breaches.
- Ease of use: Kubernetes can automate the deployment, scaling, and management of containerized applications. This can save organizations time and resources, and it can also help to reduce the risk of human error.
- Reduce costs: By automating the deployment and management of containerized applications, Kubernetes and Docker can help organizations reduce IT operations costs.
- Improve agility: Kubernetes and Docker can help organizations to be more agile by making it easier to deploy new features and updates to applications.
- Increase innovation: Kubernetes and Docker can help organizations to innovate more quickly by providing a platform that is easy to use and scalable.
Use cases for Kubernetes and Docker
When used in tandem, Kubernetes and Docker create a dynamic duo that unlocks a myriad of possibilities for seamless and scalable application deployment.
Here are a few use cases for using Kubernetes and Docker together:
- Deploying and managing microservices applications: Microservices applications are made up of small, independent components that can be easily scaled and deployed. Each microservice can be containerized using Docker, and Kubernetes can manage the deployment and scaling of these services independently. This allows for better maintainability, scalability, and fault isolation.
- Dynamic scaling: Together, Kubernetes and Docker enable dynamic scaling of applications. Kubernetes can automatically adjust the number of application instances based on demand. When traffic spikes, new containers can be spun up to handle the load, and when the load decreases, excess containers can be scaled down. This elasticity ensures efficient resource utilization and cost savings.
- Running containerized applications on edge devices: Kubernetes can be used to run containerized applications on edge devices, ensuring that they’re always available and up to date. Docker has redefined how applications are packaged and isolated. Docker eliminates the “it works on my machine” dilemma by encapsulating an application and its dependencies within a standardized container. This consistency ensures the application runs the same way across development, testing, and production environments.
- Continuous integration and continuous delivery (CI/CD): The combination of Docker and Kubernetes streamlines CI/CD pipelines. Docker images can be integrated into the CI/CD process, ensuring consistent testing and deployment. Kubernetes automates the deployment process, reducing manual intervention and accelerating the time to market for new features.
- Cloud-native applications: Docker and Kubernetes are cloud-agnostic, making it easier to deploy applications across different cloud providers or hybrid environments. This flexibility allows organizations to choose the most suitable infrastructure while avoiding vendor lock-in.
What are the challenges of container orchestration?
Although Docker Swarm and Kubernetes both approach container orchestration a little differently, they face the same challenges. A modern application can consist of dozens to hundreds of containerized microservices that need to work together smoothly. They run on multiple host machines, called nodes. Connected nodes are known as a cluster.
Hold this thought for a minute and visualize all these containers and nodes in your mind. It becomes immediately clear there must be a number of mechanisms in place to coordinate such a distributed system. These mechanisms are often compared to a conductor directing an orchestra to perform elaborate symphonies and juicy operas for our enjoyment. Trust me, orchestrating containers is more like herding cats than working with disciplined musicians (some claim it’s like herding Schrödinger’s cats). Here are some of the tasks orchestration platforms are challenged to perform.
Container deployment
In the simplest terms, this means to retrieve a container image from the repository and deploy it on a node. However, an orchestration platform does much more than this: it enables automatic re-creation of failed containers, rolling deployments to avoid downtime for the end-users, as well as managing the entire container lifecycle.
Scaling
This is one of the most important tasks an orchestration platform performs. The “scheduler” determines the placement of new containers so compute resources are used most efficiently. Containers can be replicated or deleted on the fly to meet varying end-user traffic.
Networking
The containerized services need to find and talk to each other in a secure manner, which isn’t a trivial task given the dynamic nature of containers. In addition, some services, like the front-end, need to be exposed to end-users, and a load balancer is required to distribute traffic across multiple nodes.
Observability
An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces. This is essential for operators to understand the health and behavior of the container infrastructure as well as the applications running in it.
Security
Security is a growing area of concern for managing containers. An orchestration platform has various mechanisms built in to prevent vulnerabilities such as secure container deployment pipelines, encrypted network traffic, secret stores and more. However, these mechanisms alone are not sufficient, but require a comprehensive DevSecOps approach.
With these challenges in mind, let’s take a closer look at the differences between Kubernetes and Docker Swarm.
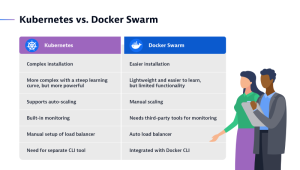
Kubernetes vs Docker Swarm
Both Docker Swarm and Kubernetes are production-grade container orchestration platforms, although they have different strengths.
Docker Swarm, also referred to as Docker in swarm mode, is the easiest orchestrator to deploy and manage. It can be a good choice for an organization just getting started with using containers in production. Swarm solidly covers 80% of all use cases with 20% of Kubernetes’ complexity.
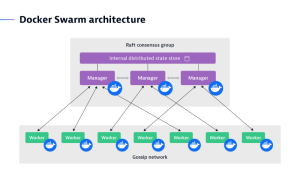
A swarm is made up of one or more nodes, which are physical or virtual machines running in Docker Engine.
Swarm seamlessly integrates with the rest of the Docker tool suite, such as Docker Compose and Docker CLI, providing a familiar user experience with a flat learning curve. As you would expect from a Docker tool, Swarm runs anywhere Docker does and it’s considered secure by default and easier to troubleshoot than Kubernetes.
Kubernetes, or K8s for short, is the orchestration platform of choice for 88% of organizations. Initially developed by Google, it’s now available in many distributions and widely supported by all public cloud vendors. Amazon Elastic Kubernetes Service, Microsoft Azure Kubernetes Service, and Google Kubernetes Platform each offer their own managed Kubernetes service. Other popular distributions include Red Hat OpenShift, Rancher/SUSE, VMWare Tanzu, IBM Cloud Kubernetes Services. Such broad support avoids vendor lock-in and allows DevOps teams to focus on their own product rather than struggling with infrastructure idiosyncrasies.
The true power of Kubernetes comes with its almost limitless scalability, configurability, and rich technology ecosystem including many open-source frameworks for monitoring, management, and security.
Docker and Kubernetes: Better together
Simply put, the Docker suite and Kubernetes are technologies with different scopes. You can use Docker without Kubernetes and vice versa, however they work well together.
From the perspective of a software development cycle, Docker’s home turf is development. This includes configuring, building, and distributing containers using CI/CD pipelines and DockerHub as an image registry. On the other hand, Kubernetes shines in operations, allowing you to use your existing Docker containers while tackling the complexities of deployment, networking, scaling, and monitoring.
Although Docker Swarm is an alternative in this domain, Kubernetes is the best choice when it comes to orchestrating large distributed applications with hundreds of connected microservices including databases, secrets, and external dependencies.
How does advanced observability benefit Kubernetes and Docker Swarm?
Whether you’re using Kubernetes or Docker Swarm, or both, managing clusters at scale comes with unique challenges, particularly when it comes to observability. Application teams and Kubernetes/Swarm platform operators alike depend on detailed monitoring data. Here are some examples.
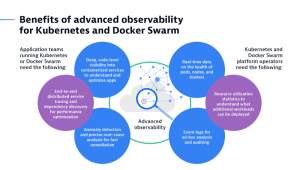
Kubernetes provides some very basic monitoring capabilities, like event logs and CPU loads for example. However, there’s a growing number of open-standard and open-source technologies available to augment Kubernetes’ built-in features. Some frequently used observability tools include: Promtail, Fluentbit and Fluentd for logs; Prometheus for metrics; and OpenTelemetry for traces, to name a few.
Dynatrace integrates with all these tools and more, and adds its own high-fidelity data to create a single real-time entity model. This unique capability enables Dynatrace to provide advanced analytics, AI-powered root-cause-analysis and intelligent automation, providing application teams and platform operators a unified view on the full technology stack.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum