
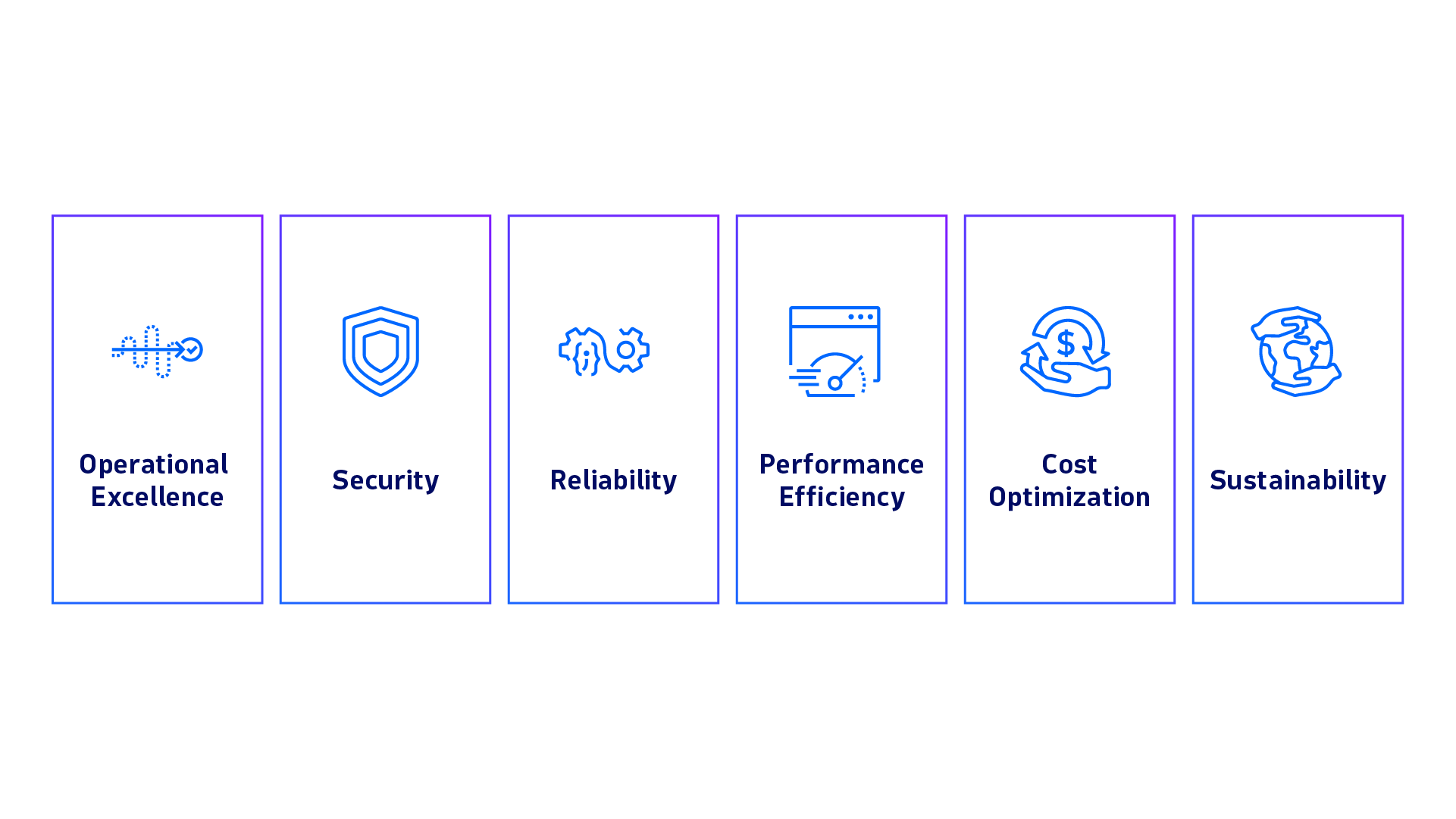
If you use AWS cloud services to build and run your applications, you may be familiar with the AWS Well-Architected Framework. This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
But how can you ensure that your applications meet these pillars and deliver the best outcomes for your business? And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? Because Google offers its own Google Cloud Architecture Framework and Microsoft its Azure Well-Architected Framework, organizations that use a combination of these platforms triple the challenge of integrating their performance frameworks into a cohesive strategy.
This is where unified observability and Dynatrace Automations can help by leveraging causal AI and analytics to drive intelligent automation across your multicloud ecosystem. The Dynatrace platform approach to managing your cloud initiatives provides insights and answers to not just see what could go wrong but what could go right. For example, optimizing resource utilization for greater scale and lower cost and driving insights to increase adoption of cloud-native serverless services.
In this blog post, we’ll demonstrate how Dynatrace automation and the Dynatrace Site Reliability Guardian app can help you implement your applications according to all six AWS Well-Architected pillars by integrating them into your software development lifecycle (SDLC).
Dynatrace AutomationEngine workflows automate release validation using AWS Well-Architected pillars
With Dynatrace, you can create workflows that automate various tasks based on events, schedules or Davis problem triggers. Workflows are powered by a core platform technology of Dynatrace called the AutomationEngine. Using an interactive no/low code editor, you can create workflows or configure them as code. These workflows also utilize Davis®, the Dynatrace causal AI engine, and all your observability and security data across all platforms, in context, at scale, and in real-time.
One of the powerful workflows to leverage is continuous release validation. This process enables you to continuously evaluate software against predefined quality criteria and service level objectives (SLOs) in pre-production environments. You can also automate progressive delivery techniques such as canary releases, blue/green deployments, feature flags, and trigger rollbacks when necessary.
This workflow uses the Dynatrace Site Reliability Guardian application. The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. The Site Reliability Guardian also helps keep your production environment safe and secure through automated change impact analysis.
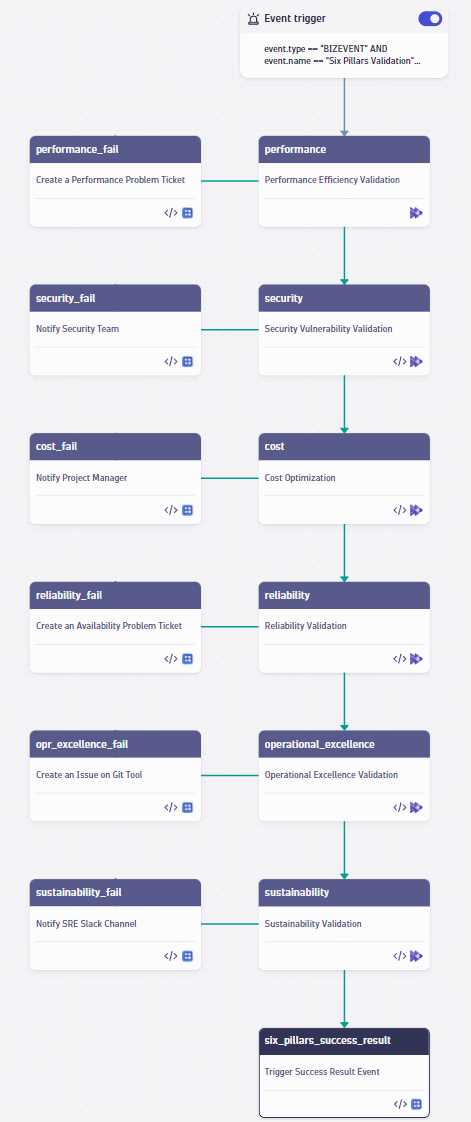
But this workflow can also help you implement your applications according to each of the AWS Well-Architected pillars. Here’s an overview of how the Site Reliability Guardian can help you implement the six pillars of AWS Well-Architected.
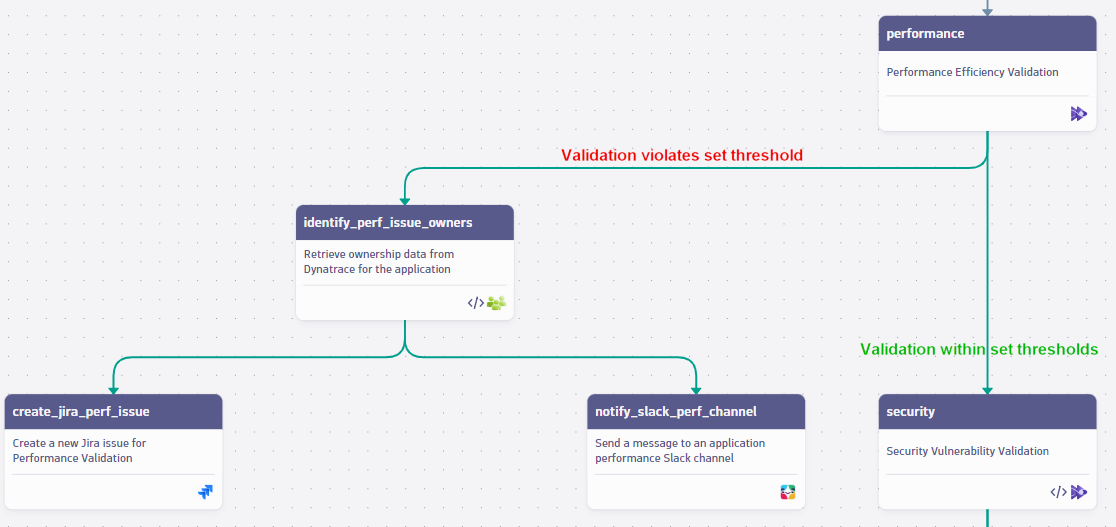
AWS Well-Architected pillar #1: Performance efficiency
The performance efficiency pillar focuses on using computing resources efficiently to meet system requirements, maintaining efficiency as demand changes, and evolving technologies.
A study by Amazon found that increasing page load time by just 100 milliseconds costs 1% in sales. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond efficiency, validating performance thresholds is also crucial for revenues.
Once configured, the continuous release validation workflow powered by the Site Reliability Guardian can automatically do the following:
- Validate if service response time, process CPU/memory usage, and so on, are satisfying SLOs
- Stop promoting the release into production if the error rate in the logs is too high
- Notify the SRE team using communication channels
- Create a Jira ticket or an issue on your preferred Git repository if the release is violating the set thresholds for the performance SLOs
SLO examples for performance efficiency
The following examples show how to define an SLO for performance efficiency in the Site Reliability Guardian using Dynatrace Query Language (DQL).
Validate if response time is increasing under high load utilizing OpenTelemetry spans
fetch spans
| filter endpoint.name == "/api/getProducts"
| filter k8s.namespace.name == "catalog"
| filter k8s.container.name == "product-service"
| filter http.status_code == 200
| summarize avg(duration) // in milliseconds
Check if process CPU usage is in a valid range
timeseries val = avg(dt.process.cpu.usage)
,filter in(dt.entity.process_group_instance, "PROCESS_GROUP_INSTANCE-ID")
| fields avg = arrayAvg(val) // in percentage![]()
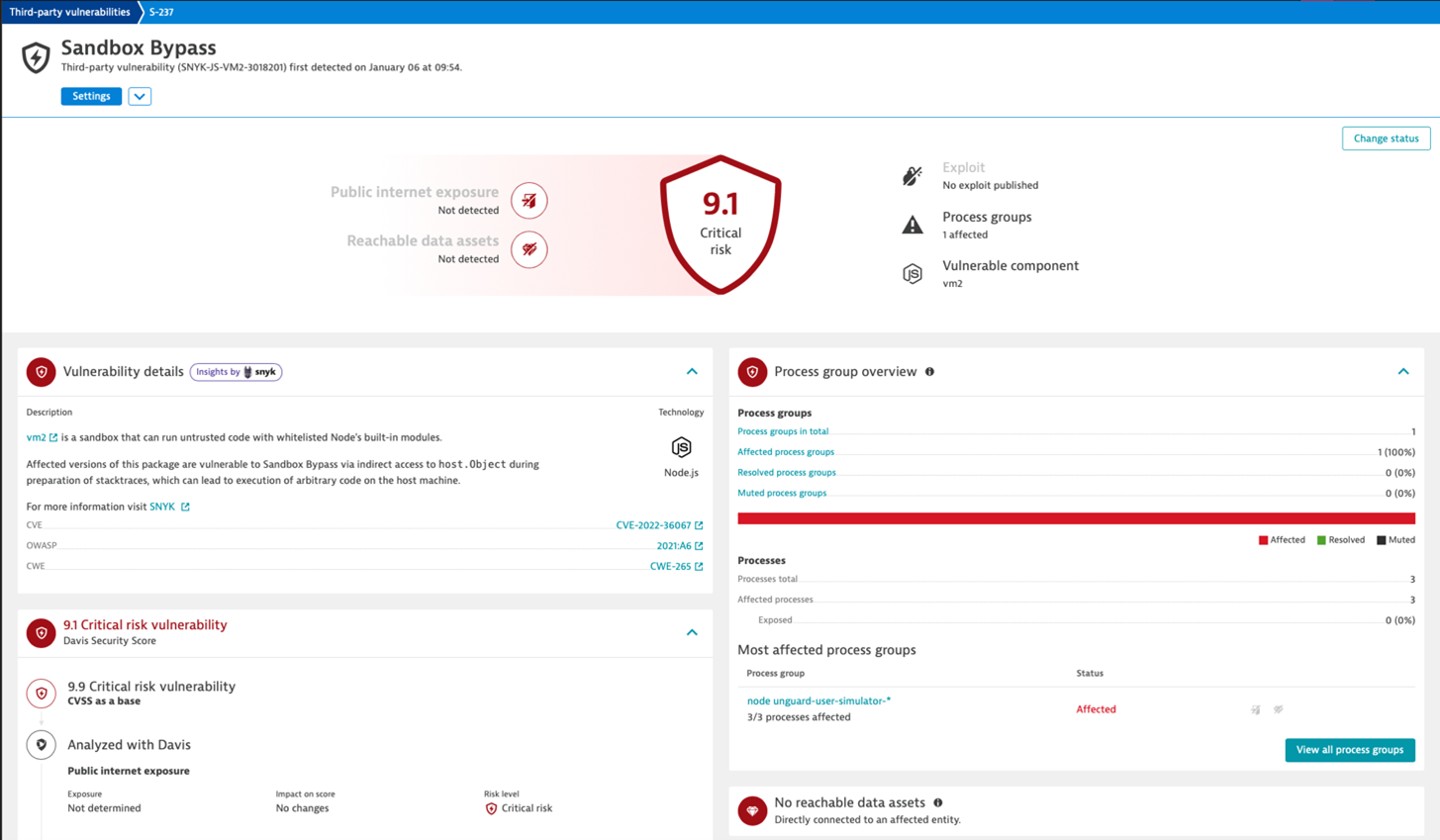
AWS Well-Architected pillar #2: Security
The security pillar focuses on protecting information system assets while delivering business value through risk assessment and mitigation strategies.
The continuous release validation workflow powered by Site Reliability Guardian can automatically do the following:
- Check for vulnerabilities across all layers of your application stack in real-time, getting help from Dynatrace Davis Security Score as a validation metric
- Block releases if they do not meet the security criteria
- Notify the security team of the vulnerabilities in your application and create an issue/ticket to track the progress
SLO examples for security
The following examples show how to define an SLO for security in the Site Reliability Guardian using DQL.
Runtime Vulnerability Analysis for a Process Group Instance – Davis Security Assessment Score
fetch events
| filter event.kind == "SECURITY_EVENT"
| filter event.type == "VULNERABILITY_STATE_REPORT_EVENT"
| filter event.level == "ENTITY"
| filter in("PROCESSGROUP_INSTANCE_ID",affected_entity.affected_processes.ids)
| sort timestamp, direction:"descending"
| summarize
{
status=takeFirst(vulnerability.resolution.status),
score=takeFirst(vulnerability.davis_assessment.score),
affected_processes=takeFirst(affected_entity.affected_processes.ids)
},
by: {vulnerability.id, affected_entity.id}
| filter status == "OPEN"
| summarize maxScore=takeMax(score)
AWS Well-Architected pillar #3: Cost optimization
The cost optimization pillar focuses on avoiding unnecessary costs and understanding managing tradeoffs between cost capacity performance.
The continuous release validation workflow powered by the Site Reliability Guardian can automatically do the following:
- Detect underutilized and/or overprovisioned resources in Kubernetes deployments considering the container limits and requests
- Determine the non-Kubernetes-based applications that underutilize CPU, memory, and disk
- Simultaneously validate if performance objectives are still in the acceptable range when you reduce the CPU, memory, and disk allocations
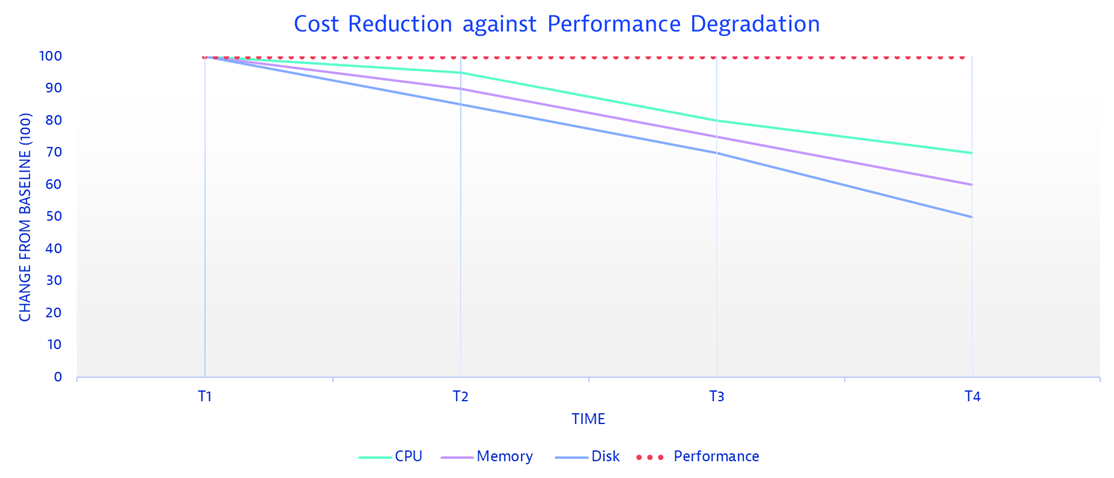
SLO examples for cost optimization
The following examples show how to define an SLO for cost optimization in the Site Reliability Guardian using DQL.
Reduce CPU size and cost by checking CPU usage
To reduce CPU size and cost, check if CPU usage is below the SLO threshold. If so, test against the response time objective under the same Site Reliability Guardian. If both objectives pass, you have achieved your cost reduction on CPU size.
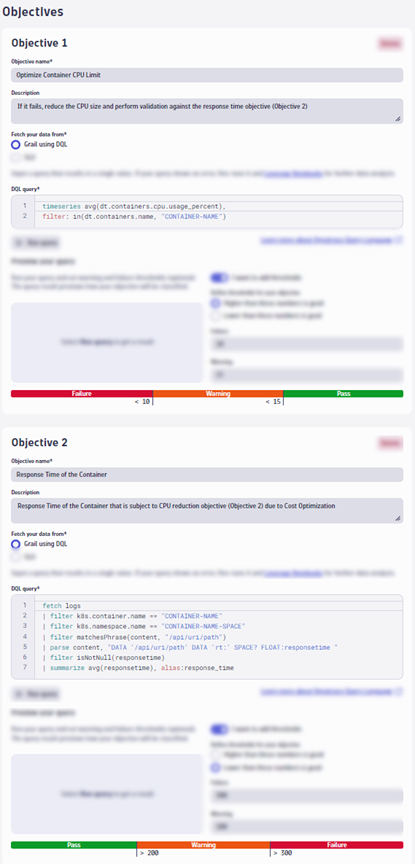
Here are the DQL queries from the image you can copy:
timeseries cpu = avg(dt.containers.cpu.usage_percent),
filter: in(dt.containers.name, "CONTAINER-NAME")
| fields avg = arrayAvg(cpu) // in percentagefetch logs
| filter k8s.container.name == "CONTAINER-NAME"
| filter k8s.namespace.name == "CONTAINER-NAMESPACE"
| filter matchesPhrase(content, "/api/uri/path")
| parse content, "DATA '/api/uri/path' DATA 'rt:' SPACE? FLOAT:responsetime "
| filter isNotNull(responsetime)
| summarize avg(responsetime) // in millisecondsReduce disk size and re-validate
If the SLO specified below is not met, you can try reducing the size of the disk and then validating the same objective under the performance efficiency validation pillar. If the objective under the performance efficiency pillar is achieved, it indicates successful cost reduction for the disk size.
timeseries disk_used = avg(dt.host.disk.used.percent),
filter: in(dt.entity.host,"HOST_ID")
| fields avg = arrayAvg(disk_used) // in percentage
AWS Well-Architected pillar #4: Reliability
The reliability pillar focuses on ensuring a system can recover from infrastructure or service disruptions and dynamically acquire computing resources to meet demand and mitigate disruptions such as misconfigurations or transient network issues.
The continuous release validation workflow powered by the Site Reliability Guardian can automatically do the following:
- Monitor the health of your applications across hybrid multicloud environments using Synthetic Monitoring and evaluate the results depending on your SLOs
- Proactively identify potential availability failures before they impact users on production
- Simulate failures in your AWS workloads using Fault Injection Simulator (FIS) and test how your applications handle scenarios such as instance termination, CPU stress, or network latency. SRG validates the status of the resiliency SLOs for the experiment period.
SLO examples for reliability
The following examples show how to define an SLO for reliability in the Site Reliability Guardian using DQL.
Success Rate – Availability Validation with Synthetic Monitoring
fetch logs
| filter log.source == "logs/requests"
| parse content,"JSON:request"
| fieldsAdd httpRequest = request[httpRequest]
| fieldsAdd httpStatus = httpRequest[status]
| fieldsAdd success = toLong(httpStatus < 400)
| summarize successRate = sum(success)/count() * 100 // in percentage
Number of Out of memory (OOM) kills of a container in the pod to be less than 5
timeseries oom_kills = avg(dt.kubernetes.container.oom_kills),
filter: in(k8s.cluster.name,"CLUSTER-NAME") and in(k8s.namespace.name,"NAMESPACE-NAME") and in(k8s.workload.kind,"statefulset") and in (k8s.workload.name,"cassandra-workload-1")
| fields sum = arraySum(oom_kills) // num of oom_kills![]()
AWS Well-Architected pillar #5: Operational excellence
The operational excellence pillar focuses on running and monitoring systems to deliver business value and continually improve supporting processes and procedures.
With continuous release validation workflow powered by the Site Reliability Guardian, you can:
- Automatically verify service or application changes against key business metrics such as customer satisfaction score, user experience score, and Apdex rating
- Enhance collaboration with targeted notifications of relevant teams using the Ownership feature
- Create an issue on your preferred Git repository to track and resolve the invalidated SLOs
- Trigger remediation workflows based on events such as service degradations, performance bottlenecks, security vulnerabilities
- Validate your CI/CD performance over time, considering the execution times, pipeline performance, failure rate, etc., which shows your operational efficiency in your software delivery pipeline.
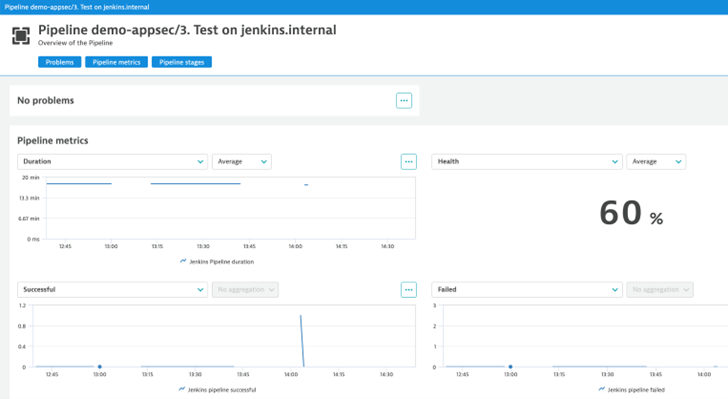
SLO examples for operational excellence
The following examples show how to define an SLO for operational excellence in the Site Reliability Guardian.
Apdex rating validation of a web application
- Navigate to “Service-level objectives” and click on “Add new SLO” button
- Select “User experience” as a template. It will auto-generate the metric expression as the following:
(100)*(builtin:apps.web.actionCount.category:filter(eq("Apdex category",SATISFIED)):splitBy())/(builtin:apps.web.actionCount.category:splitBy()) - Replace your application name in the entityName attribute:
type("APPLICATION"),entityName("APPLICATION-NAME") - Add a success criteria depending on your needs

- Reference this SLO in your Site Reliability Guardian objective
AWS Well-Architected pillar #6: Sustainability
The sustainability pillar focuses on minimizing environmental impact and maximizing the social benefits of cloud computing.
The continuous release validation workflow powered by the Site Reliability Guardian can automatically do the following:
- Measure and evaluate carbon footprint emissions associated with cloud usage
- Leverage observability metrics to identify underutilized resources for reducing energy consumption and waste emissions
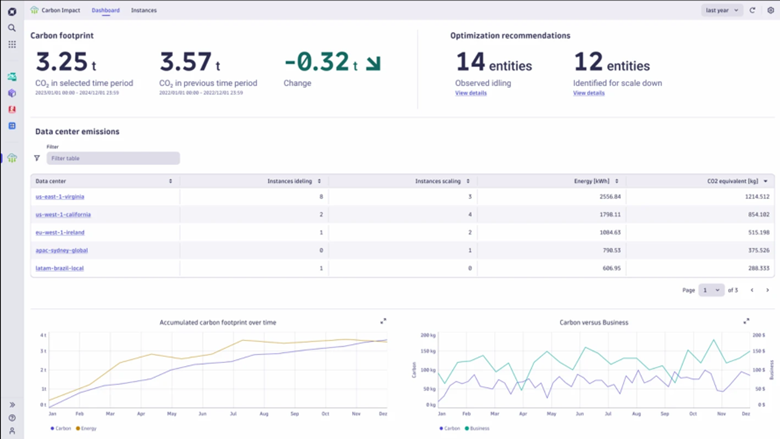
SLO examples for sustainability
The following examples show how to define an SLO for sustainability in the Site Reliability Guardian using DQL.
Carbon emission total of the host running the application for the last 2 hours
fetch bizevents, from: -2h
| filter event.type == "carbon.report"
| filter dt.entity.host == "HOST-ID"
| summarize toDouble(sum(emissions)), alias:total // total CO2e in grams![]()
Under-utilized memory resource validation
timeseries memory=avg(dt.containers.memory.usage_percent), by:dt.entity.host
| filter dt.entity.host == "HOST-ID"
| fields avg = arrayAvg(memory) // in percentage![]()
Implementing AWS Well-Architected Framework with Dynatrace: A practical guide
To help you get started with implementing the AWS Well-Architected Framework using Dynatrace, we’ve provided a sample workflow and SRGs in our official repository. This resource offers a step-by-step guide to quickly set up your validation tools and integrate them into your software development lifecycle.
Quick Implementation: Follow the instructions in our Dynatrace Configuration as Code Samples repository to deploy the sample workflow and SRGs. This will enable you to immediately begin validating your applications against the AWS Well-Architected pillars.
For more about how Site Reliability Guardian helps organizations automate change impact analysis, performance, and service level objectives, join us for the on-demand Observability Clinic, Site Reliability Guardian with DevSecOps activist Andreas Grabner.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum