
Dynatrace is announcing the launch of Grail, our new data lakehouse technology for boundless observability, security, and business analytics. Grail is fundamentally enhancing the technical core of the Dynatrace Software Intelligence Platform. With multicloud and cloud-native architectures the volume of data and the complexity of application environments and dependencies between their components are exploding. Our customers need an effective way to store, contextualize, and query data to get immediate insights and drive automation.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company.
Existing observability and monitoring solutions have built-in limitations when it comes to storing, retaining, querying, and analyzing massive amounts of data. These technologies are poorly suited to address the needs of modern enterprises—getting useful insights and real value from data beyond isolated metrics. So, there was a need to do something revolutionary. Thus, Grail was born.
 From these humble beginnings, Grail was purpose-built with one fundamental goal: making all data accessible—and thus valuable—to provide precise answers in real-time, boost insights gathered by Davis AI and drive automation. This goal isn’t limited to observability efforts. Grail needs to support security data as well as business analytics data and use cases. With that in mind, Grail needs to achieve three main goals with minimal impact to cost:
From these humble beginnings, Grail was purpose-built with one fundamental goal: making all data accessible—and thus valuable—to provide precise answers in real-time, boost insights gathered by Davis AI and drive automation. This goal isn’t limited to observability efforts. Grail needs to support security data as well as business analytics data and use cases. With that in mind, Grail needs to achieve three main goals with minimal impact to cost:
- Cope with and manage an enormous amount of data—both on ingest and analytics
- Work with different and independent data types
- Put data in context and enrich it with topology metadata
Grail architectural basics
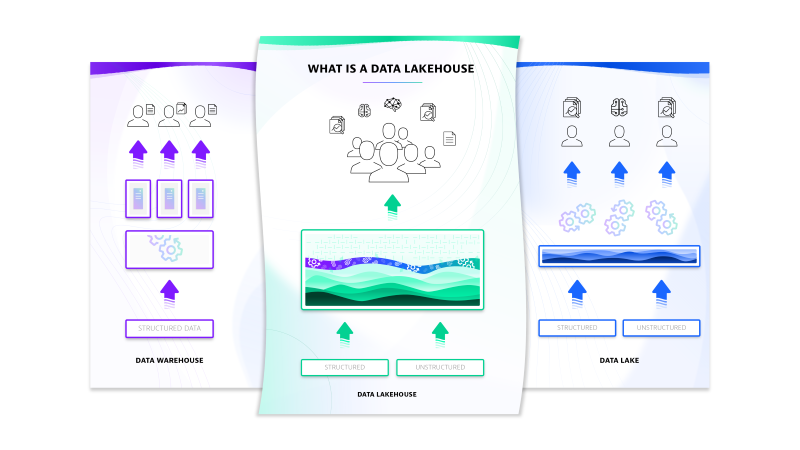
The aforementioned principles have, of course, a major impact on the overall architecture. In its essence, Grail is a data lakehouse. But what does that mean? A data lakehouse combines the benefits of data warehouses with those of data lakes. A data warehouse is purpose-built and optimized for specific use cases, providing valuable insights on structured data and able to handle large data sizes. In contrast, data lakes can handle different types of unstructured and semi-structured data in unknown extent, thus introducing openness and flexibility. This openness is accompanied by reduced data quality which limits the value of analyses run on data lakes.
A data lakehouse addresses these limitations and introduces an entirely new architectural design. This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes).
For Dynatrace this is the start of a new journey – with more powerful offerings to come. To enable this architecture and build a data lakehouse, we had to decouple storage from analytics and compute. This decoupling ensures the openness of data and storage formats, while also preserving data in context. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed.
As a result, we created Grail with three different building blocks, each serving a special duty:
- Ingest and process: High performance, automated data collection and processing
- Retain: A storage solution built specifically for observability and security data
- Analytics: Query petabytes in real time and start getting real value out of your data
Ingest and process with Grail
From the beginning, Grail was built to be fast and scalable to manage massive volumes of data. It’s based on cloud-native architecture and built for the cloud. Thus, it can scale massively. This starts with a highly efficient ingestion pipeline that is architectured to support adding hundreds of petabytes daily. To add data to the ingest pipeline, customers can choose between Dynatrace® OneAgent or open source observability frameworks, such as OpenTelemetry, Prometheus, Micrometer, and others.
 Dynatrace OneAgent is the only agent that automatically collects data from every tier of your application stack without requiring configuration. Just a few minutes after installation, you get all the performance metrics and log data you need to monitor IT infrastructure of any complexity—from front end to back end. This unique, end-to-end data collection, together with Smartscape® topology mapping, will ensure Grail is fueled with all available data—in context—and ready for manual or AI-driven analytics tasks.
Dynatrace OneAgent is the only agent that automatically collects data from every tier of your application stack without requiring configuration. Just a few minutes after installation, you get all the performance metrics and log data you need to monitor IT infrastructure of any complexity—from front end to back end. This unique, end-to-end data collection, together with Smartscape® topology mapping, will ensure Grail is fueled with all available data—in context—and ready for manual or AI-driven analytics tasks.
Alongside this data ingest, Grail enables highly efficient processing pipelines to enrich ingested data, extract metrics, or add a privacy filter. Check out this blog post and learn—based on the example of log data—how to derive even more value from data with simple pattern matching and powerful processing rules.
Retain data
Forget about having to choose which data to keep and which to drop and stop getting headaches when managing different storage tiers. Do you remember your organization’s last security breach, sitting in a war room and doing forensic research without effectively identifying the root cause because the data was either dropped at ingest or no longer available? Can you count the number of days you have lost because you have waited for data to get rehydrated?
This scenario is a thing of the past. You don’t need to find a needle in the haystack. Thanks to Grail’s unique architecture, you can afford to ingest and store all your data. Once ingested, Grail ensures that data is retained for up to three years – fully flexible, based on your needs and individual settings – while still being accessible by the analytics layer. Data is available in real time without requiring indexing by our powerful Dynatrace Query Language.
High-performance analytics—no indexing required
Traditional data management and observability solutions rely on schemas and indexes to ensure high-performance analytics. A schema is a fixed definition to organize data in certain fields.
 Consider a log event in which the event itself has fields such as error code, severity, or time stamp. An index is a high-performing structure that improves the speed of data retrieval operations. Usually, the index is created on the fields defined in the schema at ingest time. This technique is called schema-on-write.
Consider a log event in which the event itself has fields such as error code, severity, or time stamp. An index is a high-performing structure that improves the speed of data retrieval operations. Usually, the index is created on the fields defined in the schema at ingest time. This technique is called schema-on-write.
Schema-on-write worked well for some time, but it has reached its limits. The concept has major disadvantages that are significant when considering today’s ever-growing data complexity and quantity. Data is either not available at all, or you need to invest a lot of effort and wait for hours, or even days, until it is re-indexed.
Grail’s schema-on-read allows IT teams to store data in its native format. That means data preparation occurs when data is queried, not ingested. This provides greater flexibility, as teams can perform any query at any time—on data in its native structure—and are not limited to the fields defined in the schema when the ingest pipeline was set up.
In addition, Grail is also indexless. Whereas indexes promise high-query performance with indexed data, they’re limited in size due to high costs. As a result, data is generally stripped—or dropped—at ingest, to minimize the size of the index. Additionally, data is moved from index to cold storage once the data reaches a certain age. Consequently, teams can’t use cold data for analysis and need, instead, to re-index the data before adding it to a query. This process reduces flexibility as teams need to wait for indexing to finish before they can start a query.
Contrary to these concepts, Grail can query any data ingested and deliver answers in real time.
Thanks to its massively parallel processing (MPP) engine, you can perform any query and retrieve results instantly. Use the power of the Dynatrace Query Language (DQL) to search, parse, filter, sort and aggregate all data stored and available within Grail. Because of its familiar concepts it is easy to learn and master. Other than SQL you can understand the syntax and write your own complex queries, without being a data scientist. On-the-fly parsing is 5-10x times faster than similar approaches, like using regular expressions, and enable any query any time on any size of data. DQL is purpose-built for observability and security use cases. It gives teams maximum flexibility and control for any ad-hoc analysis while enabling AI-powered answers and automation.
What started in Boston finally comes to life in Grail
Dynatrace Grail truly enables modern enterprises. The continued exponential data growth is driven largely by the convergence of observability, security, and business data. Grail is built for such analytics, not storage. It’s your single source for all data, ready for any question, delivering precise and lightning-fast answers, empowering AI-driven decisions and intelligent automation in real time.
Start using Grail! You’ll love digging into your data in an ad-hoc manner while gaining new insights and value from your data. Grail for log management and analytics is available for customers using Dynatrace SaaS on AWS, and is expected to be available for Dynatrace SaaS on Azure or Azure Native Dynatrace customers in early 2024.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum