
Dynatrace Log Management and Analytics enables any analysis at any time with Grail technology, the world’s first data lakehouse with massively parallel processing for context-rich observability, business, and security analytics. Get precise answers by querying your log data anytime — thanks to schema-on-read — without indexing or archive management.
Log management and analytics enables any analysis at any time with Grail, the world’s first data lakehouse with massively parallel processing for context-rich observability, business, and security analytics. Get precise answers by querying your log data anytime — thanks to schema-on-read — without indexing or archive management.
Log management and analytics is an essential part of any of any organization’s observability and security strategy , and it’s no secret the industry has suffered from a shortage of innovation for several years. Several pain points have made it difficult for organizations to manage their data efficiently, even more to analyze and make sense out of it to create actual value. Dynatrace has recognized this problem for some time, and we’ve been working hard to build a radically new approach to addressing it.
Limited data availability constrains value creation
Modern IT environments — whether multicloud, on-premises, or hybrid-cloud architectures — generate exponentially increasing data volumes. The number and variety of applications, network devices, serverless functions, and ephemeral containers grows continuously. And this expansion shows no sign of slowing down. Still, it is critical to collect, store, and make easily accessible these massive amounts of log data for analysis. Full access to all relevant observability, security, and business data is essential to address unforeseen issues and enable proactive efforts to optimize and secure applications and cloud-native environments as well as to prevent service degradation and outages.
Current market standards are insufficient for modern large-scale environments
Traditional solutions and approaches are inefficient given the number of manual tasks that are required for effective log data ingest. Typically, IT Ops, DevOps, SRE, and security teams must invest significant time into creating one-off scripts, tags, and indexes. This approach is cumbersome and challenging to operate efficiently at scale. Teams have introduced workarounds to reduce storage costs. Additionally, efforts such as lowered data retention times, two-tiered storage systems, shaky index management, sampled data, and data pipelines reduce the overall amount of stored data.
While all these measures address the mounting economic pressure to reduce the costs of data storage, they have two major shortcomings: they restrict data availability, and they don’t create value. Additionally, they induce data anxiety for IT teams — how can teams ensure they have all the required data when it comes to resolving incidents, ensuring compliance, ongoing optimizations, and investigating suspicious events?
Even in cases where all data is available, new challenges can arise. Current analytics tools are fragmented and lack context for meaningful analysis. When one tool monitors logs, but traces, metrics, security, audit, observability, and business data sources are siloed elsewhere or monitored using other tools, teams can struggle to align or deliver a single source of the truth. Simply put, current solutions struggle with identifying dependencies, relationships, or correlations across diverse data sources.
As a result, teams often miss critical insights, incidents take longer to resolve, and deployment cycles can’t benefit from automation.
Stop worrying about log data ingest and storage — start creating value instead
Dynatrace® Grail, an additional core technology for the Dynatrace® Software Intelligence platform, is the world’s first data lakehouse with massive parallel processing (MPP) for context-rich observability, business, and security analytics. And with this release, Dynatrace is poised to introduce an entirely new approach to log management and analytics that will shatter all log data ingest and storage constraints.
Grail, the hassle-free, boundless, and indexless data lakehouse built specifically for observability
Dynatrace supports automatic log data collection of entire application stacks in context of all observability signals with OneAgent and an Open API with native multicloud support for Kubernetes, Red Hat OpenShift and AWS, Azure and GCP environments. With Grail, the platform can now ingest log data without manually built indexes or index maintenance. Additionally, Grail delivers unrivaled performance without losing the precision of unsampled data. Dynatrace built and optimized it for Davis® AI, the game changing Dynatrace artificial intelligence engine that processes billions of dependencies in the blink of an eye.
Grail addresses today’s challenges of big data and cloud everywhere: Grail is highly scalable, cost-effective, and super-fast.
- Store petabytes without schemas, indexing, or rehydration
- Analyze all your de-siloed data sources in full context
- Easily turn logs to metrics to dashboards
- Explore logs in context of your auto-discovered topologies and entities
- Broad ingest support with full control
Impactful analytics with the Dynatrace Query Language
Not only is your log data available at all times, it can also be queried using the Dynatrace Query Language (DQL) to turn data into valuable insights and actions. Thanks to schema-on-read architecture, you can query precise information stored in Grail without determining your analytics use cases beforehand.
For example, with just one query, your teams can achieve the following:
- Retrieve logs with historical business data, extract relevant business metrics, and aggregate the metrics into reports.
- Find time- or entity-bound anomalies or patterns in your infrastructure monitoring logs.
- Pinpoint specific tokens, like IP addresses or user identifiers, and create reports of the occurrences.
- Query audit logs and aggregate top user accounts with specific actions, such as data deletion.
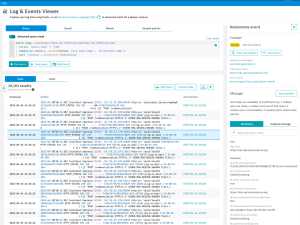
Queries are easy to create and include a wide range of possibilities:
- Create lookups across all available sources.
- Use conditional statements.
- Create filters.
- Run statistical queries.
Best-in-class performance is no longer limited to optimized use cases. Rather, it is available for every query.
Turn log data into value and activate Grail
Grail with Dynatrace Query Language (DQL) is a unique tool set that saves time, effort, and costs by providing all necessary functionality — from ingest to extracted value — for the complete log data lifecycle within a single platform specifically built for observability with AI in mind. Grail is built to eliminate data silos, provide a single source of truth for multiple teams, and alleviate data anxiety with indexless, hassle-free data ingest, 100% data availability, and powerful analytics capabilities.
Grail and the Dynatrace Query Language will be available for Dynatrace SaaS on AWS starting with selected regions within 30 days and Dynatrace SaaS on Azure in early 2024.
If you’re interested in participating in a new era of log management and analytics, please contact your Dynatrace representative.
What’s next for Grail?
There’s still much to come, as Grail, in combination with DQL, will serve as an enabling technology for many other exciting use cases beyond log management and analytics.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum