
Powered by Grail™
Log management and analytics
Make smarter, faster decisions when troubleshooting and measuring the health of your application environments—all while reducing the cost and operational overhead of telemetry ingestion, management, and analysis.



Actionable insights for all your critical use cases
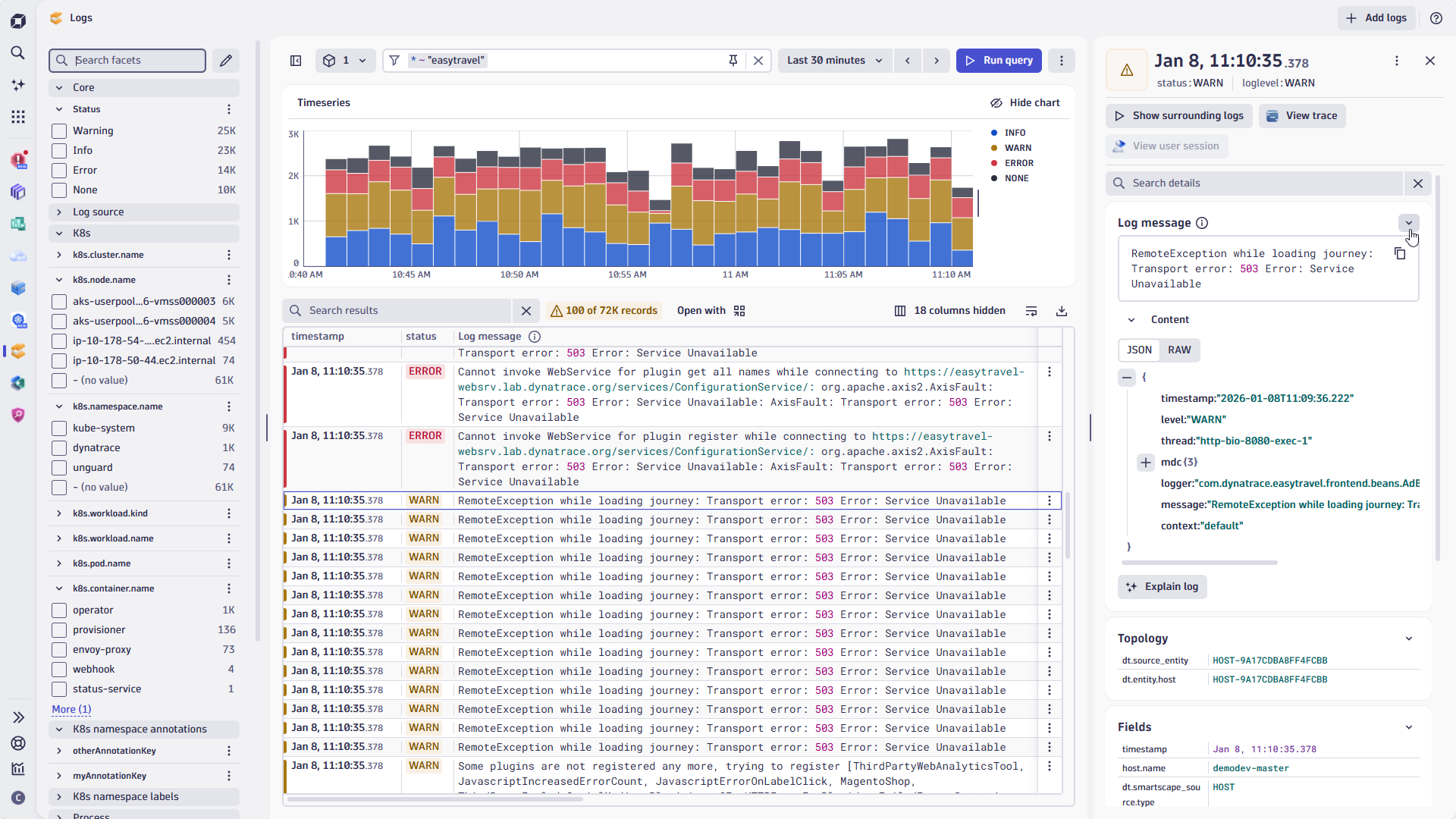
Unified observability includes Logs
Discover and resolve issues immediately with logs, traces, and metrics automatically in context
- Dynatrace Intelligence provides automated problem detection and root cause analysis with complete accuracy across all observability signals
- Accelerate mean time to identify (MTTI) and mean time to repair (MTTR) reduction through problem cards, which automatically correlate traces, events, metrics, and logs across multiple tools and data silos, eliminating manual analysis and streamlining issue resolution
- Immediate analysis without the need for reconfiguration, indexes or schemas

Business insights from unified observability
Gain critical business intelligence using logs
- Easily extract business data from log files, automatically enriched with IT context
- Automatically extract business events from log files during ingest to gain valuable business insights
- Alert on business anomalies with Dynatrace Intelligence
Automate log management and analysis with Dynatrace Intelligence
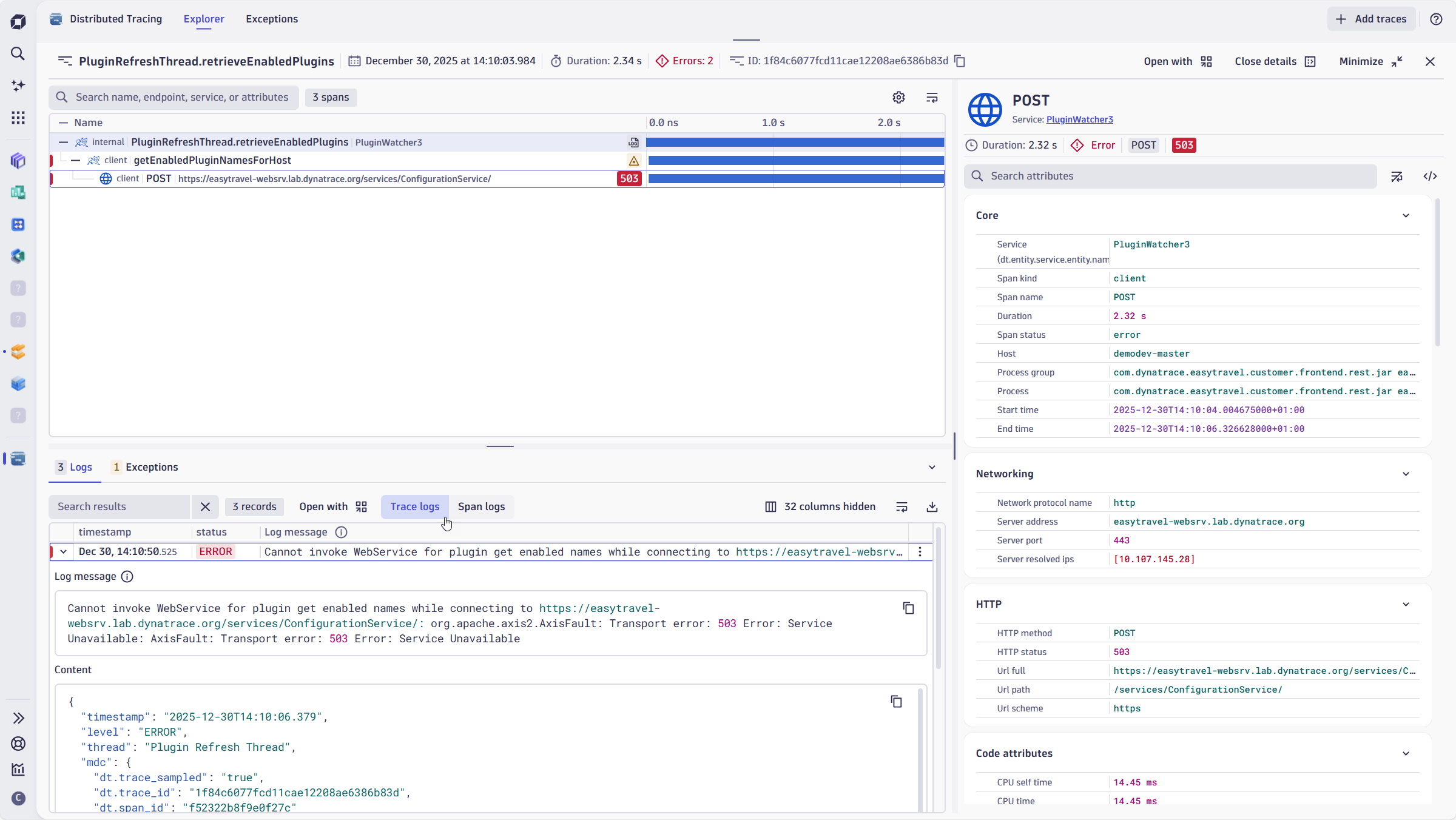
Get rid of manual correlation between different monitoring tools
- Powerful search and filtering capabilities without writing queries
- Out-of-box ingest and cost control dashboards
- Pre-processing of common log formats like JSON or OTel, with telemetry pipeline support for enhanced search and filtering
- Utilize Dynatrace Intelligence to write Dynatrace Query Language (DQL) and explain logs from natural language
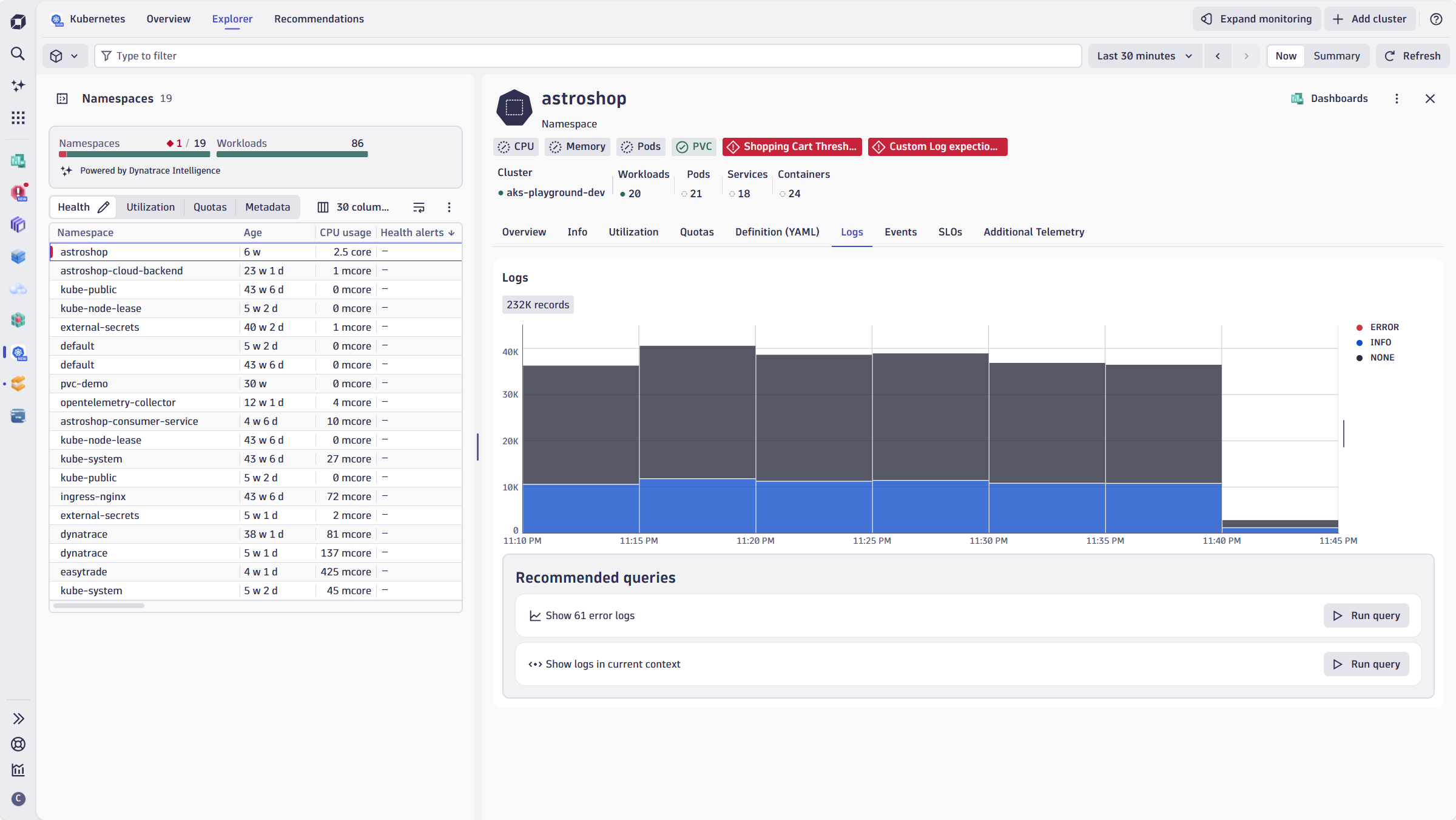
Kubernetes observability
Gain full-stack visibility across your entire Kubernetes environments
- Filter by namespace, workload, node, pod, and container to simplify analysis
- Easily implement log collection and data streaming integrations
- Diagnose cluster health and optimize resource usage across workloads with data in context and AI-assisted analytics
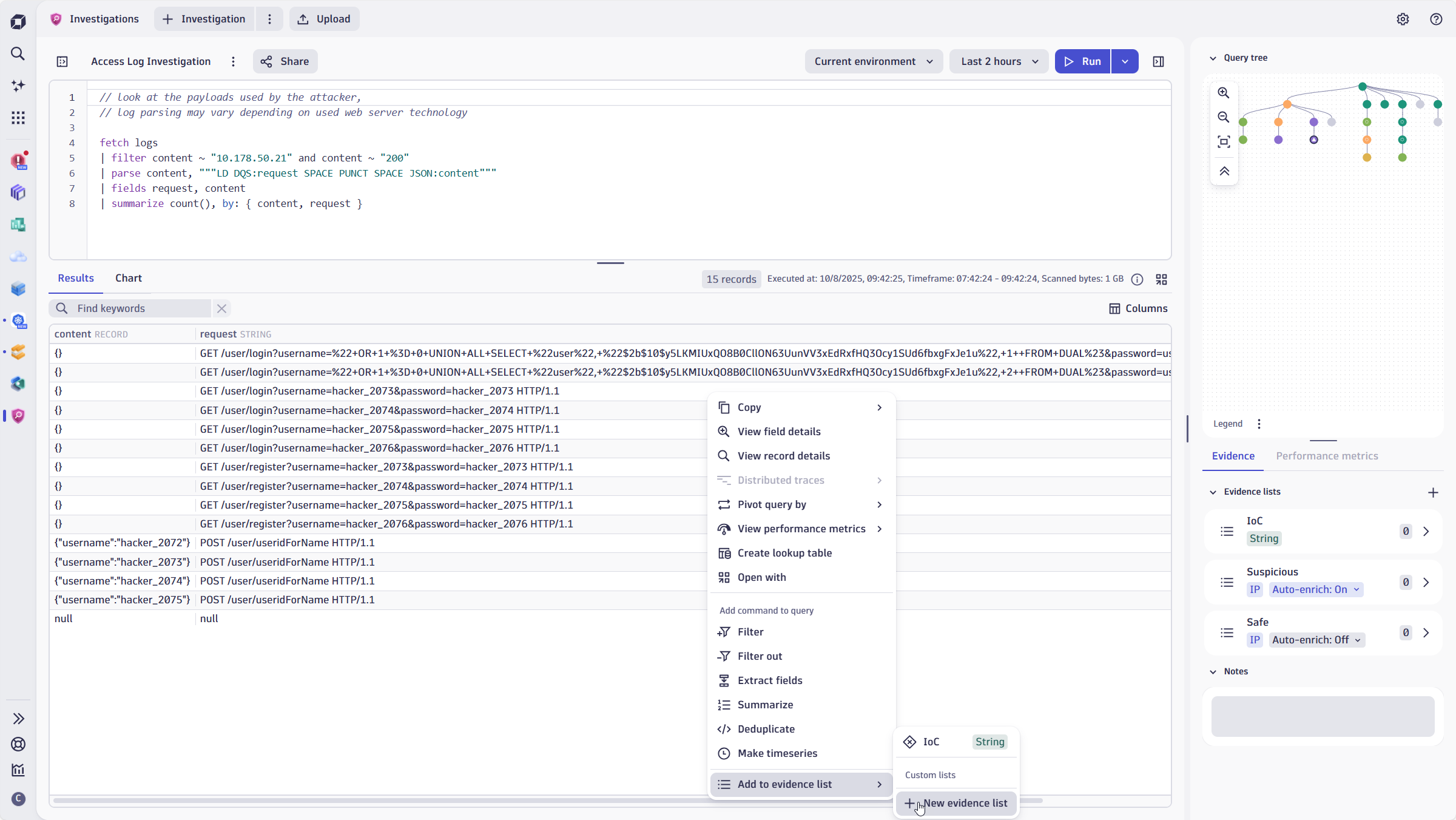
Threat Detection and incident response
Leverage unified observability signal as part of security investigations
- Faster MTTR with automated root cause analysis levering logs, traces, events together
- Threat detection and incident response with the Security Investigator app
- Efficiently find the “unknown unknowns” with queries that span metrics, events, logs, and traces
- Cost-effectively retain logs and security events from days to years with instant access
Do it all with the power of Grail
Dynatrace automatically and efficiently retains the context for petabytes of observability and security data in Grail, providing a single log management and analytics platform to bring your IT, security, and business teams together to meet your service level objectives.


See how BMO delivers better digital experiences with Dynatrace
Greater efficiency
Cut 60 hours of monthly log analytics toil per team
Faster innovation
Unlocked 40 hours of extra time for development
Higher availability
Issue analysis and resolution time slashed by 80%




Take on your biggest challenges

Silos
Event correlation and root cause analysis across teams and data pools

Scale
Teams and budgets cannot keep up the volume and variety of data

Speed
Tradeoffs between data cost, availability, and fidelity delay MTTR
Log resources
 DocumentationLog Management and Analytics best practices
DocumentationLog Management and Analytics best practices WhitepaperSplunk vs Dynatrace: four paradigm shifts when moving from Splunk to Dynatrace
WhitepaperSplunk vs Dynatrace: four paradigm shifts when moving from Splunk to Dynatrace BlogUnlock log analytics: Seamless insights without writing queries
BlogUnlock log analytics: Seamless insights without writing queries BlogCost allocation for logs: Precise, flexible, and non-disruptive
BlogCost allocation for logs: Precise, flexible, and non-disruptive- BlogLogs and traces: Why context is everything for seamless investigations
 BlogFull Kubernetes logging in context: Easily stream logs from Fluent Bit to Dynatrace
BlogFull Kubernetes logging in context: Easily stream logs from Fluent Bit to Dynatrace





