
Kelsey Hightower and Andreas Grabner talk Kubernetes, simplifying complexity, and the future of cloud-native technologies at Dynatrace Perform 2022.
Kelsey Hightower is no stranger to Kubernetes complexity. Principal engineer at Google and co-founder of KubeCon, Hightower advocates simplicity and automation.
These are two values he shares with DevOps activist Andreas Grabner, who sat down with Hightower at Dynatrace Perform to talk about taming Kubernetes and the future of cloud-native technologies.
The art—and science—of simplicity
“Making complex things simple is important,” Grabner says, noting that simplicity is a guiding principle in Dynatrace’s own evolution. “For anyone who works in an organization and wants to be a game-changer, you need to convince people about something new by breaking it down in simple terms.”
For Hightower, the ability to explain things in simple terms is a journey to his own understanding. “I’m one of those people who takes a while to get some of these complex topics, so I attempt to learn in public,” he says. “I’ll make some assumptions, read multiple blog posts, and I need to run it myself a couple of times. I try to make sure I understand things completely in simple terms. So when people hear me explain things, it’s this process of convincing myself I completely understand it.”
How does Kubernetes work?
To explain Kubernetes, Kelsey Hightower turns to the familiar. “Let’s invent the post office.”
In a clip from the Honeypot documentary, Kubernetes: The Documentary (Part 1), Hightower explains that managing containerized environments is like sending a package through the post office. You supply the box, address, and postage—the post office does the rest and guarantees accurate on-time delivery. The touchpoints in between are abstracted, and you can trust the outcome.
But Kubernetes does not exist in a vacuum; it’s part of a larger ecosystem that’s always evolving.
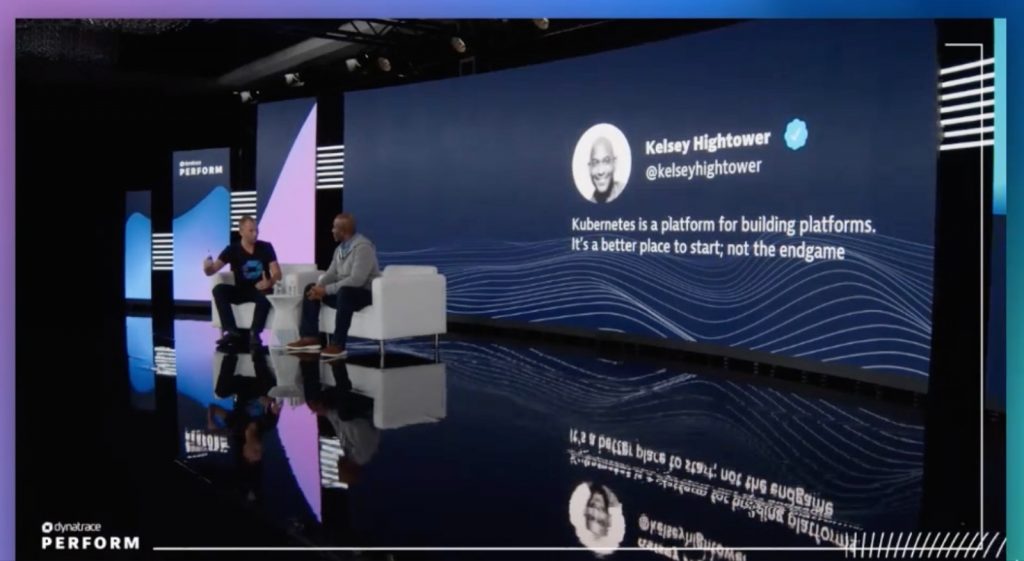
Kubernetes: A place to start, not the endgame
Grabner was struck by a tweet Hightower made three or four years ago: “Kubernetes is a platform for building platforms. It’s a better place to start, and not the endgame.” While Kubernetes has transformed how organizations build and deliver software, it is part of a larger context.
“When we think about Kubernetes, it’s really just one piece of the puzzle,” Hightower says. For example, there are stakeholders, dependencies, and end-users throughout the process. “There’s a big picture and given that Kubernetes is just one part of it, you have to think about what’s missing.”
What’s missing is observability. “You have to have some type of signal you can use to make adjustments,” says Hightower. “For the end-user, I’m thinking, is my workload running? Kubernetes is not something you just install and you’re done. It’s a good base layer, but you’re going to need to bring in other tools to make it usable.”
To clarify, Grabner notes that Kubernetes already provides some data of its own. And if you have other tools, like the open-source systems monitoring toolkit, Prometheus, you need a solution to make sense of all the data in context.
Achieving observability in a Kubernetes ecosystem at scale
Here’s where the Dynatrace platform, with Dynatrace OneAgent, Smartscape topology mapping, and PurePath distributed tracing provides the advantage, especially at scale.
To illustrate, Grabner cited one Dynatrace customer that’s deployed 200,000 OneAgents to monitor four hyperscalers and their own datacenter. At this massive scale, Dynatrace provides real-time awareness of their Kubernetes, multicloud, and on-premises environments. With automatic and intelligent observability of all their infrastructure, apps, services, and workloads and their dependencies, Dynatrace pinpoints exactly where something is going wrong.
What’s at stake: the real people behind the dots on dashboards
Earlier in his career, Kelsey Hightower recalled how his teams met in war rooms to troubleshoot broken systems. “People were taking their sweet time,” Hightower recalls. “We didn’t have any automation tools. People were checking the logs and doing ad-hoc debugging, but we didn’t have a sense of urgency.”
Then, their CTO walked in and made it real. “He explained that one of our customers was in the grocery store with his family and a cart full of groceries,” he remembered. The customer received government assistance through their electronic benefits transfer (EBT) card, but the card system was down. Most often, EBT customers don’t have another way to pay. “There are other people in line looking at someone who can’t afford to pay for their groceries,” he says. “One of those dots on the graph might represent one of our customers unable to buy food.”

“When we talk about SLOs and SLAs, those are the promises we make to our customers, and it’s on us to keep them,” continues Hightower. “If you’re going to have an SLO, you should have a story in mind of why you’re setting up all these alerts and collecting all these metrics. They should tell you why it’s important to do what you’re doing.”
Infrastructure as code vs infrastructure as data
Grabner noted that Dynatrace just announced the release of software intelligence as code, an enhancement of API endpoints. This enhancement enables developers to easily incorporate software intelligence capabilities, such as observability, AIOps, and application security data, into their applications. As a result, teams can automate more processes in their software development lifecycle.
Hightower likes to think of it as infrastructure as data. “Not everyone knows how to write code,” he says. “As a developer, I can say these are the metrics I care about and just give them to you. When we say ‘declarative’, we want to boil it down to ‘tell us what you want, and we’ll take care of the rest.’”



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum