
Dynatrace enables configuration-as-code for logs, making data acquisition, filtering, masking, and anonymizing scalable in enterprise environments. Orchestrating a fleet of OneAgents from a central configuration point removes error-prone manual work for DevOps and SRE teams across dynamic IT landscapes.

Log data provides a unique source of truth for debugging applications, optimizing infrastructure, and investigating security incidents. To further enrich log data for automated observability, it’s necessary to dynamically tie logs to distributed traces on the code level, user sessions in the app front-end, and the topology of your IT landscape. This contextualization of log data enables AI-powered problem detection and root cause analysis at scale.
The key to 360-degree observability is acquiring the right data at the right time from the right places. Achieving this from a typical enterprise’s various apps, systems, and configurations is the beginning of the observability journey and, therefore, critical to get right.
Dynamic landscape and data handling requirements result in manual work
All this is easier said than done because:
- Kubernetes-based dynamic architecture is becoming the norm. Many Dynatrace customers complain that typical sources for logs are ephemeral and short-lived pods or microservices, which brings new challenges in scaling up observability efforts. Such ever-changing log-source landscapes bring pain and hinder teams in scaling their observability efforts.
- A typical enterprise environment includes multiple teams with varying requirements that can be conflicting. So, setting the same configuration rules for all teams is hardly a satisfying solution as it slows down more agile teams and reduces competitiveness. A customer recently told us, “We monitor hosts in our enterprise from more than 50 countries. Some monitoring requirements are the same for all teams; some country teams need to create a subset of rules.”
- Data sovereignty and governance establish compliance standards that regulate or prohibit the collection of certain data in logs. To remain compliant, such logs are typically subject to pseudonymization or anonymization procedures (masking), which makes sensitive data inaccessible while preserving the contextual information of the event, service, or host.
- As data volumes explode, teams have different prioritization for the data they want to acquire for observability. Collecting logs that aren’t relevant to their business case creates noise, overloads congested networks, and slows down teams.
- Every manual step in growing enterprise environments becomes a hurdle. As the number of services or hosts reaches tens or hundreds of thousands, automation becomes the only way to tame the complexity.
- Basic automation and out-of-the-box solutions might not cover all the edge cases within enterprise-scale installations. A customer recently shared their pain with manual configuration files, stating, “We must set up custom logging rules for some hosts, which requires logging into that host to create a configuration file. But in our case, the number of hosts with custom rules goes to four figures.”
The new configuration empowers log acquisition at scale
Dynatrace now provides a log acquisition toolkit that guarantees maximum value from your log data on the Dynatrace observability platform. By enabling configuration-as-code for central orchestration of your deployed OneAgents, automation can observe tens of thousands of hosts, services, or short-lived Kubernetes pods. With complete identity and access management support, scaling log management across your enterprise is more manageable.
Relevant log sources are automatically discovered as OneAgents are deployed across your IT landscape. Dynatrace offers an easy and powerful configuration flow for determining which auto-discovered logs are relevant to which teams and need to be ingested into Dynatrace. The central management of this configuration offers default setups and blanket rules, with granular rules supporting each team’s needs.
To control local network data volume and potential congestion, Dynatrace also allows filtering of log data on-source—by specific host, service, or even log content—before data is sent to the cloud.
Such filtering allows pseudonymizing or anonymizing (masking) sensitive data at the OneAgent level. This way, it‘s possible to flexibly select what confidential or sensitive information (for example, PII) is hashed or completely removed before it leaves the enterprise premises. This helps you stay compliant while working with sanitized logs without losing the event context, which provides valuable insights into DevOps, SRE, or business teams’ observability goals.
Even if a team has unique requirements for a specific edge case, the new custom log source capability eliminates the need for time-consuming manual work at the host level. By configuring custom log sources in Dynatrace, it’s possible to direct OneAgents to find and ingest log data relevant to a specific use case.
Flexible rules cover default and edge-case business needs
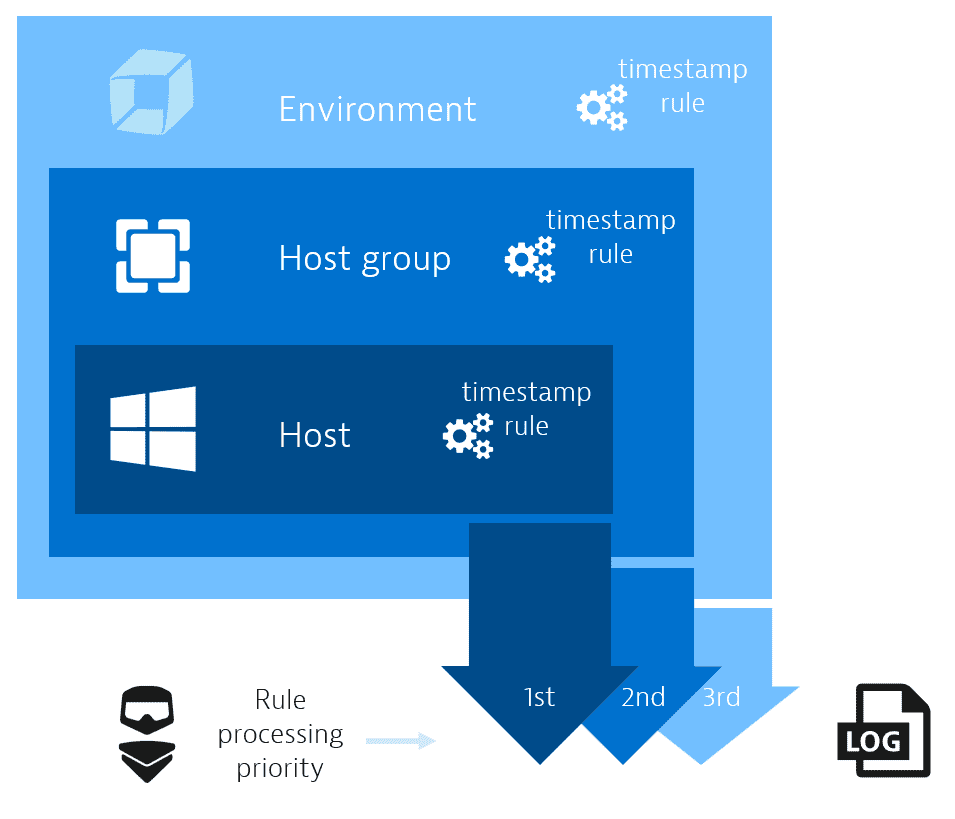
The new log acquisition configuration works by setting up rules on three levels:
- Host
- Host group
- Tenant
OneAgent processes rules precisely in this order, with host scope rules processed before host group and tenant scope rules. If a more granular rule is present on the host level, that rule will precede any blanket rule on, for example, the tenant level.
Setting up rules on each scope can require creating matches for logs across specific paths or process groups, instructions for masking sensitive data, or picking up custom log sources.
For example, consider that you need to monitor all NGINX logs across all hosts and Kubernetes nodes for pod logs. This involves setting up a rule on the tenant scope: telling OneAgents to upload all logs discovered in the /var/log/nginx path.
If the Kubernetes nodes belong to a EKS host group, then a second rule can be created for the host group. All new hosts appearing in that group would fall under that rule, and logs outside the EKS host group will not be stored.
This allows you to create flexible and powerful log storage configurations on any level by utilizing the unique autodiscovery capabilities of Dynatrace OneAgent or a custom setup. Sensitive data masking enables you to comply with applicable standards and data protection laws in a simple way, as the selected data never leaves your enterprise premises. By creating or modifying the log storage configuration through an API, teams can enable software intelligence as code, automate manual tasks, and achieve higher efficiency with a lower error rate.
Try it out yourself
The new power of log acquisition, masking and custom log sources in Dynatrace is supported for both SaaS and Managed deployments. It’s delivered in three parts:
- New log storage configuration is available in Dynatrace version 1.252 and requires OneAgent 1.243+.
- Sensitive data masking will be available in Dynatrace version 1.253 and require OneAgent 1.243+.
- Support for custom log sources will be available in Dynatrace version 1.254 and require OneAgent 1.251+.
- Visit our trial page for a free 15-day Dynatrace trial.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum