
At Dynatrace we host most of our Dynatrace SaaS clusters for paying customers as well as trial users in the Amazon Web Services (AWS) cloud. As of September 2020, we run 51 clusters on 1100 EC2 instances distributed across six AWS Regions ensuring that all our users can leverage the Dynatrace Software Intelligence Platform to monitor their hybrid-multi cloud environments.
The Autonomous Cloud Enablement (ACE) Team at Dynatrace has an important role to play in that offering. On one hand, they enable our engineers to get their latest enhancements deployed into production. On the other, they enable everyone at Dynatrace through self-service to do their part ensuring. Since we moved to AWS in May 2014 we have had an availability of 99.95%!
A critical component to this success was that the Dynatrace Team itself uses the Dynatrace Platform to monitor every single Dynatrace cluster in the cloud and trusts the Dynatrace Davis® AI to alert in case there are any issues, either with a new feature, a configuration change or with the infrastructure our servers are running on.
On most days Davis is quiet, but then there are times that lead to stories like the one I’m going to share with you today.
Sydney, we have a disk write latency problem!
It was on August 25th at 14:00 when Davis initially alerted on a disk write latency issues to Elastic File System (EFS) on one of our EC2 instances in AWS’s Sydney Data Center. The problem didn’t last long or have any impact on our services.
After two days of quiet Davis again detected a Slow Disk issue. This time however on a different EC2 machine, but again in Sydney. The problem – pushed to an internal ACE Slack channel – was picked up by one of our engineers in the ACE team, who followed the root cause information provided by Dynatrace which clearly pointed this to Disk Write Latency on EFS as can be seen in the following screenshot:
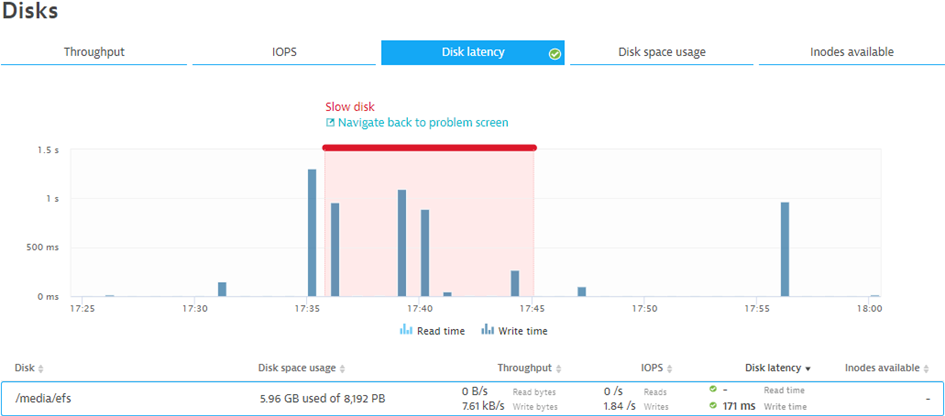
In the next few hours Davis kept detecting the same problem across multiple EC2 instances in Sydney, the team ruled out a software-related issue on our end as there was no specific deployment or configuration change made to just these EC2 instances that experienced the problem.
Thanks to the close collaboration our Dynatrace teams have with AWS, we reached out to their technical teams to confirm whether what Dynatrace detected on those EC2 instances was already a known issue on their end. To help the AWS team, our engineers shared all the details of the incoming issues that slightly worsened over that following weekend. You can see it in the following dashboard showing a longer time range of these disk slowness issues reported:
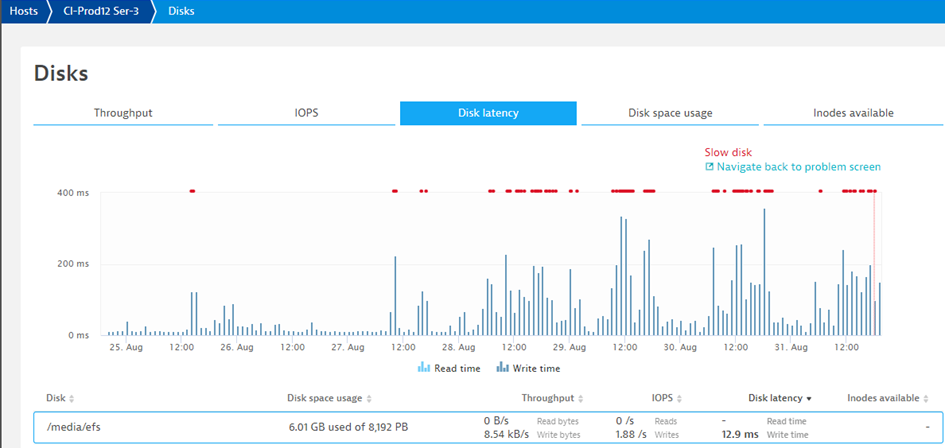
The information captured by our Dynatrace OneAgent, along with additional information gathered as requested by AWS, was exchanged with their teams. The AWS team confirmed a known hardware issue affecting a certain amount of EC2 machines in that region. The fast action by our ACE Team that followed up with AWS and the fast replacement of hardware by AWS brought the system back to its original state shortly after the investigation began.
We don’t know how many other EC2 instances of other AWS customers were potentially impacted by issues like this – but – hey – Davis helped us detect that hardware issues could potentially have an impact on any SLAs software organizations like us and other AWS users have to their customers.
Modern hybrid-multicloud monitoring needs more than just metrics
When running software on very elastic infrastructure – whether this is on-premises or in a data center of your trusted cloud provider – it is required that your monitoring not only gives you a lot of metrics. The key to fast remediation is to have a system that automatically detects anomalies in every layer of your stack, alerts on problems, and gives you the information about the potential impact before it’s too late!
Lucky for us we use Dynatrace to monitor Dynatrace. Lucky for us we have a great partner with AWS. Lucky for us we have an ACE Team with members like Gabriela who embrace the Dynatrace Davis AI and let it help her do her job even better!
Lucky for you – you can also do this by signing up for a Dynatrace Trial and start monitoring your hybrid enterprise cloud environments.
Lucky for me – I get these stories from our users so I can share them with you.
P.S: For this story, I am personally very happy as it is the first that comes from my wife – who is my hero: Love you, Gabi 😊




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum