
Software reliability and resiliency don’t just happen by simply moving your software to a modern stack, or by moving your workloads to the cloud. There is no “Resiliency as a Service” you can connect to via an API that makes your service withstand chaotic situations. The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The path to “Architected for Resiliency” is long, but it clearly pays off in the long run, especially when outages occur, as I want to show you in this blog post.
This article was inspired by an email I received from Thomas Reisenbichler, Director of Autonomous Cloud Enablement on Friday, June 11th. The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. This meant there was no negative impact on our end-users, Service Level Objectives (SLOs), or Service Level Agreements (SLAs). And the last sentence of the email was what made me want to share this story publicly, as it’s a testimonial to how modern software engineering and operations should make you feel. It read: “Observing this issue, it was an honor to have the possibility to ‘just’ sit next to it and do a little bit of babysitting knowing that we are coping very well with this failure!”
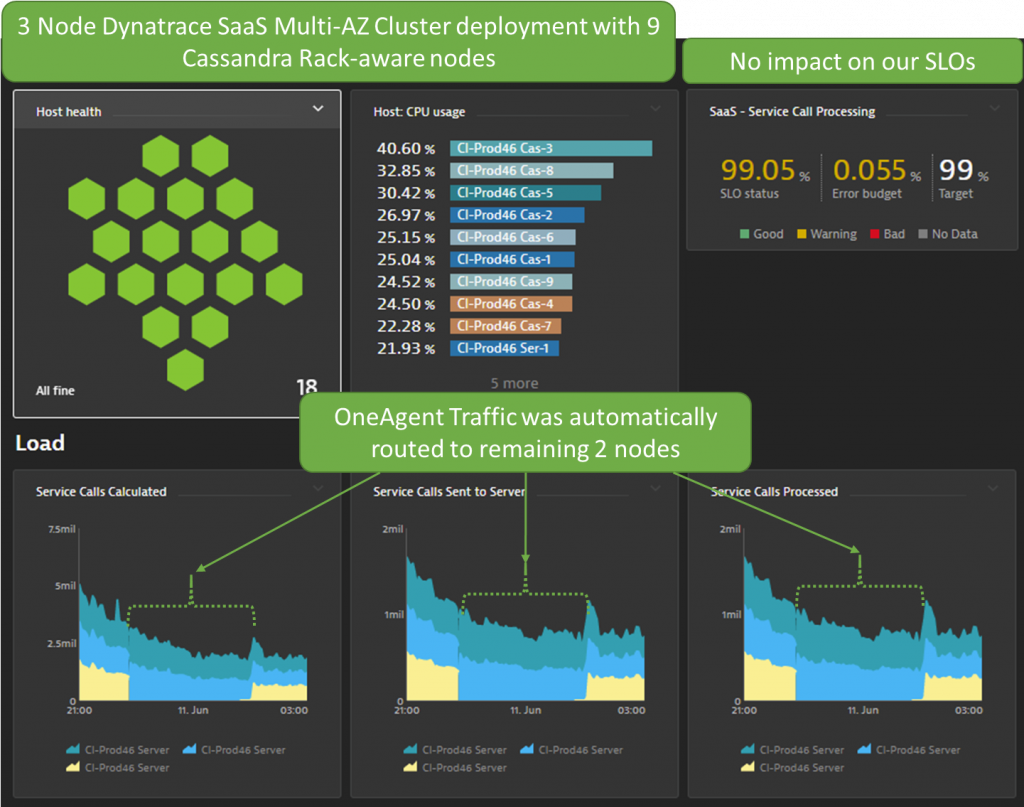
What Thomas meant by saying this, was the dashboard showed how well the Dynatrace architecture automatically redirected traffic to the remaining nodes that were not impacted by the issue – thanks to our multi-availability zone deployment – as you can see below:
Ready to learn more? Then read on!
Fact #1: AWS EC2 outage properly documented
Let’s start with some facts. There really was an outage and AWS did a great job notifying their users about any service disruptions via their AWS Service Health Dashboard. The following screenshot shows the problem reported on June 10th for the EC2 Services in one of their Availability Zones in Frankfurt, Germany:
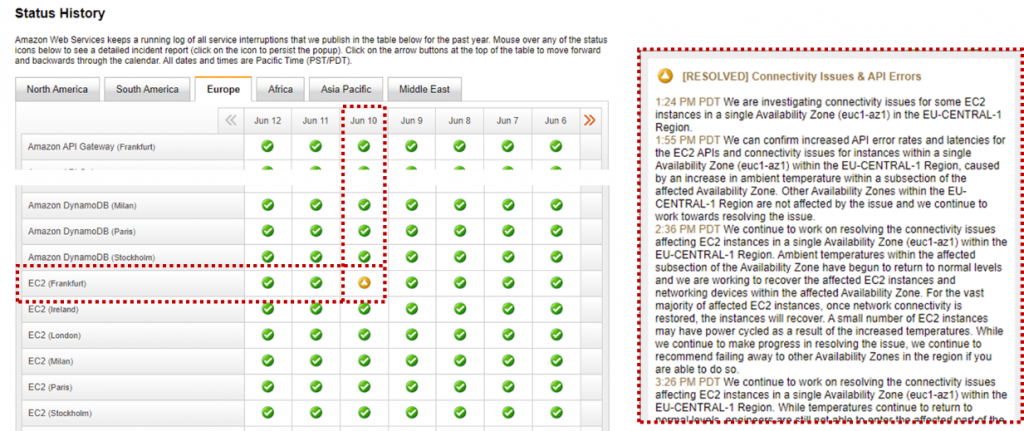
The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. The final status update was at 6:54PM PDT with a very detailed description of the temperature rise that caused the shutdown initially, followed by the fire suppression system dispersing some chemicals which prolonged the full recovery process.
Fact #2: No significant impact on Dynatrace Users
There are several ways Dynatrace monitors and alerts on the impact of service disruption. Let me start with the end-user impact.
Dynatrace provides both Real User Monitoring (RUM) as well as Synthetic Monitoring as part of our Digital Experience Solution. Through the RUM data, Dynatrace’s AI engine, Davis, detected seven users were impacted by the outage when they tried to access the Web Interface. This number was so low because the automatic traffic redirect was so fast it kept the impact so low. The screenshot below shows the opened problem ticket and the root cause information:
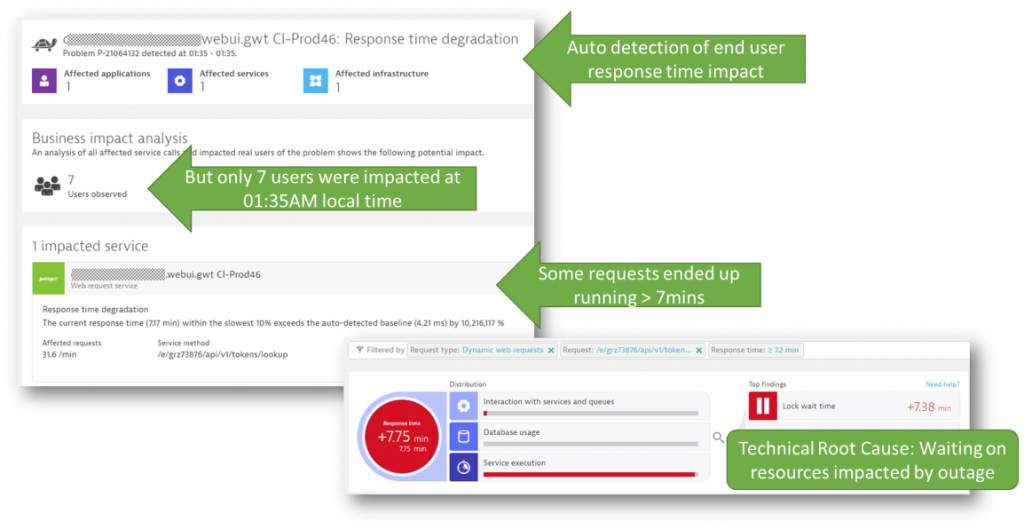
Note to our Dynatrace users: This story triggered a feature request that will benefit every Dynatrace user in the future. The team wants to enrich root-cause information in the Dynatrace problem ticket with external or third-party status details such as the AWS Service Health Status. This will eliminate the need to cross-check whether an existing outage of your third-party providers is going on right now.
Fact #3: Minimum impact detected through synthetics
Besides real user analytics, we also use Dynatrace Synthetic Monitoring, which continuously validates successful logins to our SaaS tenants on each cluster. Those tests get executed from two locations (Paris and London) hosted by different cloud vendors (Azure & AWS).
For the outage, Dynatrace Synthetic detected a very short one-time connection timeout, as you can see below:
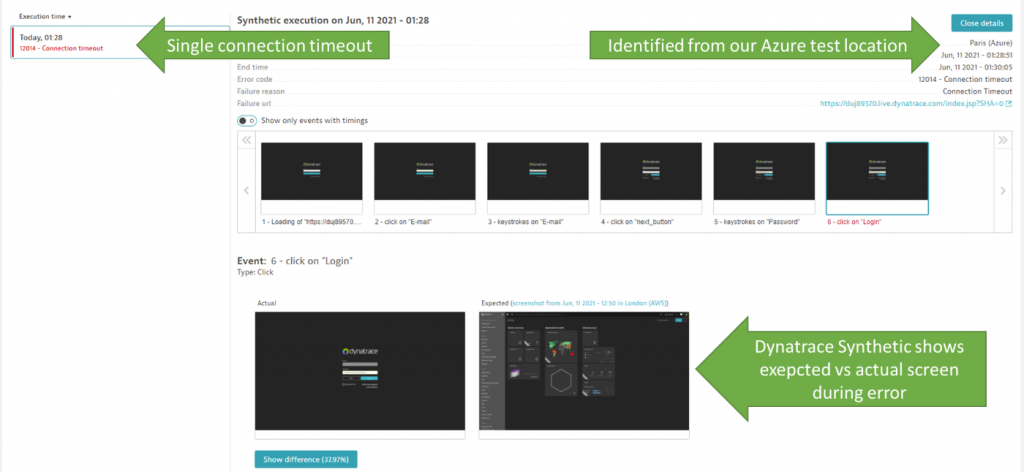
As a general best practice, Synthetic Tests are great to validate your core use cases are always working as expected. In our case that includes the login to our SaaS tenants and exploring captured data. If those use cases don’t work as expected, we want to get alerted.
Tip: We see more of our users started to Shift-Left and GitOps-ify Dynatrace Synthetic. This means that Synthetic Tests are not just used in production but also in pre-production environments to validate environment stability, e.g., do I have a stable build in a QA or Test environment or not? Thanks to our Automation APIs and our open-source project Monaco (Monitoring as Code) the creation and updates of those synthetic tests are fully embedded into their GitOps automation. Dynatrace Synthetic Test definitions are version control in Git, as YAML gets automatically rolled out as part of their delivery automation, e.g.: via Jenkins, GitLab, Azure DevOps, Keptn
Fact #4: Multi-node, multi-availability zone deployment architecture
I already mentioned at the beginning of this blog that resiliency and reliability do not come for free – they must be part of your architecture. And that’s true for Dynatrace as well. You can find a lot of information about the Dynatrace architecture online, both for our SaaS and Managed deployments.
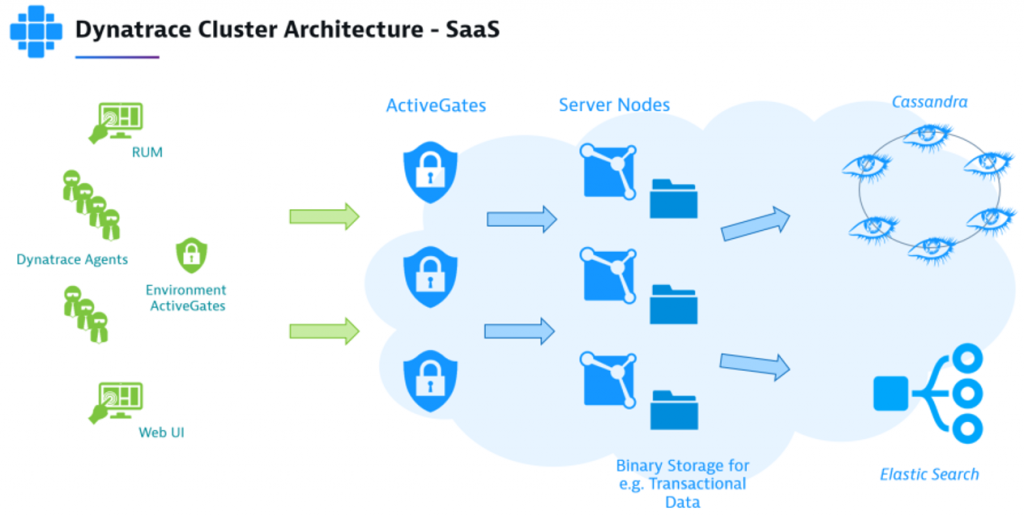
I wanted to highlight a couple of essential elements that are key for Dynatrace’s resilience against a data center (=AWS Availability Zone) outage:
- High availability due to multi-AZ Dynatrace cluster node deployments
- Rack-aware Cassandra deployments
Let’s have a quick look at Dynatrace Smartscape to see how our cluster node services are truly distributed across multiple EC2 hosts in different Availability Zones:
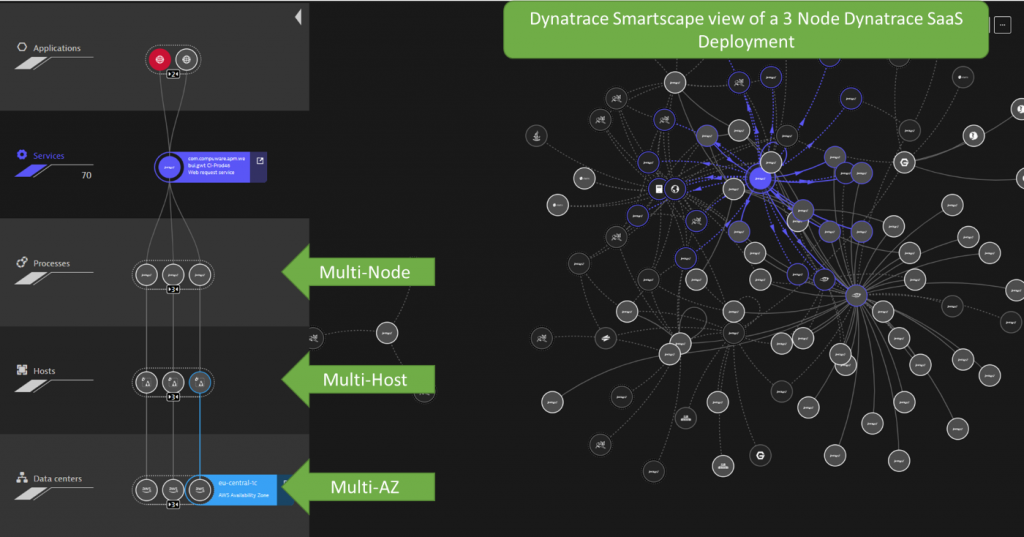
The health-based load balancing of incoming traffic automatically redirects traffic to healthy nodes. In case of host unavailability, consumers of Dynatrace services (via Web UI or API) never experience any issues. This deployment is also super resilient to full data center (e.g., Availability Zone) outages.
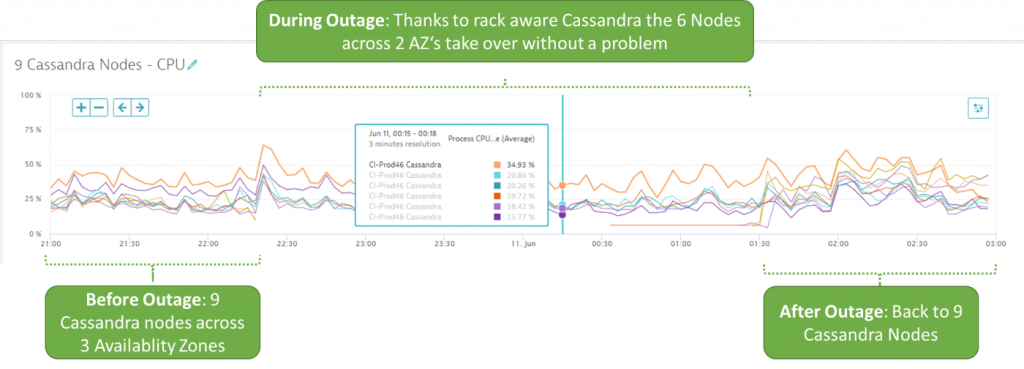
As for Cassandra, a 3-node Dynatrace SaaS deployment, we deploy 9 Cassandra nodes with a rack-aware deployment. The rack is linked to the AWS Availability Zone. In case one zone goes down, the traffic gets redirected to the remaining Cassandra nodes. The following chart shows the distribution of nodes before, during, and after the outage:
The Dynatrace deployment also contains our Active Gates. But – thanks to our multi-node and multi-datacenter deployments, all these components provide the same high availability and resiliency. That’s why the complete Dynatrace Software Intelligence Platform is “Architected for Resiliency”
Tip: Our managed customers have the same high availability and resiliency features. For more information check out our documentation on fault domain awareness such as rack aware managed deployments.
Conclusion: Investing in resilient architecture is CONTINUOUS
This story proves that high availability and resiliency must be features and considerations you plan from the start when designing a distributed system. Built-in monitoring is the only way to validate these systems work as designed, and alerting is the insurance that you get notified in corner cases to reduce the risk of negative end-user impact.
I was also reminded that resilient architecture is not a “one-time investment”. It needs continuous attention and focus. At Dynatrace we built our current architecture years ago, and to ensure it still withstands challenging situations every new feature gets evaluated against non-functional requirements such as resiliency or performance. Our dynamic growth in engineering also made us invest in continuous training for new and existing hires. And to give them feedback on the potential impact of code changes we have an automated continuous performance environment that battle tests new versions before admitting them to production.
Before saying goodbye, let me say thanks to our Dynatrace Engineering and everyone involved in designing and building such a resilient system architecture. I also want to say thank you to Thomas Reisenbichler for bringing this story to my attention, to Thomas Steinmaurer for giving me additional background information, and to Giulia Di Pietro for helping me finalize the blog post.
For more on Chaos Engineering & Observability be sure to register for my upcoming webinar with Gremlin.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum