
クラウドコンピューティング、マイクロサービス、オープンソースツール、コンテナベースのデリバリーにより、アプリケーションはますます複雑化する環境において分散化が進んでいます。その結果、分散トレースは問題に迅速に対応するために不可欠なものとなりました。
では、分散トレースとは具体的にどのようなものなのでしょうか?本稿ではその疑問にお答えするとともに、高度に分散化されたクラウドネイティブアーキテクチャにおいて、チームが適切なオブザーバビリティを獲得し、トランザクションを効果的にトレースし、その重要性をリアルタイムで分析する方法について考察します。
分散トレースとは?
分散トレースとは、分散型クラウド環境を伝播するリクエストを観察する手法です。相互作用を追跡し、一意の識別子でタグ付けします。この識別子は、トランザクションがマイクロサービス、コンテナ、インフラストラクチャとやり取りする過程で保持されます。これにより、スタックの最上位からアプリケーション層、そして基盤となるインフラストラクチャに至るまで、ユーザー体験をリアルタイムで可視化することが可能となります。
モノリシックなアプリケーションがより機敏で移植性の高いサービスへと移行するにつれ、かつてそのパフォーマンス監視に使用されていたツールは、現在それらをホストする複雑なクラウドネイティブアーキテクチャに対応できなくなっています。この複雑性により、分散トレースは現代的な環境におけるオブザーバビリティを実現するために不可欠となっています。
1,303名のCIOを対象とした最近のグローバル調査では、90%の組織が過去12ヶ月間でデジタルトランスフォーメーションが加速したと回答しています。さらに、それらの組織の26%はデジタルトランスフォーメーションが今後も加速し続けると予想しています。この変化に伴い、ますます複雑化する現代環境において効果的なオブザーバビリティの必要性が高まっています。
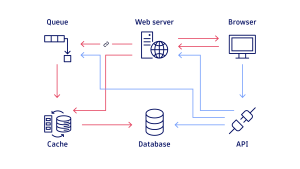
分散トレースの進化
従来、企業が主にモノリシックアプリケーションを構築していた時代には、アプリケーション内部で何が起きているかを把握することは比較的容易でした。しかし、サービス指向アーキテクチャの台頭により、特定のトランザクションがアプリケーションの様々な層をどのように通過するかを理解することが困難になりました。その結果、実行時間の遅延や遅延の根本原因を特定することが難しくなりました。
この複雑さは内部の連携にも課題をもたらしました。影響を受けたマイクロサービスを特定できない場合、どのチームが問題解決の責任を負うべきかを判断できません。環境内の活動に対する可視性が極端に低い状況では、トラブルシューティングのセッションが各チームが互いに非難し合う「戦場」と化すことも珍しくありませんでした。
組織はアプリケーション環境のオブザーバビリティ向上の必要性を認識していました。しかし、内部開発リソースを用いてゼロからソリューションを構築することは、コストと時間がかかりすぎ、イノベーションのペースを遅らせる恐れがありました。分散トレースはこのニーズに応え、企業がマイクロサービス環境に影響を与えるパフォーマンス問題をより深く理解することを可能にします。
トレースにはどのような種類がありますか?
組織では、以下のような異なるタイプの分散トレースを利用することがあります:
コードトレース。この手法では、開発者がアプリケーション内の各コード行の結果を手動で解釈します。コードトレースは、実行中に変化する変数値を追跡し、コードの出力を特定します。このプロセスは特に小規模なコードブロックで効果を発揮し、アプリケーション全体を実行せずに分析を可能にします。コードトレースは、より優れたコード記述につながる基礎的なスキルとみなされています。
データトレース。開発者はデータトレースを活用し、ビジネス上重要なデータ要素(CDE)の正確性と品質チェックを実施します。また、優先順位付けされたCDEをソースシステムまで遡ってトレースし、プロアクティブな監視を行うためにもこの手法を用います。
プログラムトレース。このコマンドは、アプリケーションの実行中に実行された命令と参照されたデータのインデックスを提供します。デバッガーやその他のコード分析ツールは、ソフトウェア開発プロセスの一環としてコードを改善するために、プログラムトレースを頻繁に利用します。
分散トレースのメリット
分散トレースは、チームや組織にアプリケーションパフォーマンスの向上、サービスレベル契約(SLA)への準拠強化、市場投入までの時間短縮など、複数のメリットをもたらします。分散トレースの最も価値ある利点には、以下のようなものがあります:
- 平均検出時間(MTTD)と平均修復時間(MTTR)の短縮。分散トレースにより、チームはアプリケーションのパフォーマンス問題をより迅速に、多くの場合ユーザーが異常を認識する前に特定できます。問題を発見すると、迅速に根本原因を特定し対処できます。また、オブザーバビリティはマイクロサービスの状態が不良な場合の早期警告を提供し、ソフトウェアスタック内のあらゆる場所のパフォーマンスボトルネックや最適化が必要なコードを特定します。
- SLA(サービスレベル契約)への準拠性向上。組織は高品質なユーザー体験を維持し、SLAへの準拠性を高めることも可能です。
- 収益基盤の成長保護。これにより収益への潜在的な影響を最小限に抑え、組織が安定した収益の流れを維持するのに役立ちます。
- 市場投入までの時間の短縮。その結果、組織は新製品やサービスをはるかに迅速に市場に投入でき、競争優位性を獲得できます。
- 内部連携の強化。分散トレースは問題の発生箇所を正確に特定するため、チーム間の連携とコミュニケーションの促進にも寄与します。これにより、タイムリーなトラブルシューティングとビジネス成長をもたらすイノベーション提供の両方に不可欠な業務上の関係性が向上します。
分散トレースの課題
分散トレースは組織に多くの利点をもたらしますが、同時にいくつかの課題や制限も生じます。具体的には以下の点が挙げられます:
- 手動での計測設定。分散トレースはチームの時間節約を目的としていますが、一部のツールでは分散トレースリクエストを設定する前に、開発者が手動でコードの計測設定や調整を行う必要があります。この作業は時間を要する上、意図せずコードエラーを引き起こす可能性があります。標準化されたプロセスを適用するチームでは、一部のトレースを見落とす恐れがあります。
- バックエンド限定の対応範囲。エンドツーエンドの分散トレースを採用していない一部のツールでは、リクエストが最初のバックエンドサービスに到達した時点でのみトレースIDが生成され、フロントエンドにおける対応するユーザーセッションが不明瞭になります。これにより、問題のあるリクエストの根本原因を特定し、バックエンドチームとフロントエンドチームのいずれが対応すべきかを判断することが不必要に困難になります。
- ヘッドベースサンプリング。トレーシングツールが各リクエストの開始時にトレースを単純にランダムサンプリングする場合、一部のトレースが漏れる可能性があります。その結果、特定のトレースが欠落または不完全となる恐れがあります。これにより、高価値なトランザクションや特定顧客からのリクエストなど、優先度の高いトレースを常にサンプリングできない状況が生じます。 高度なオブザーバビリティソリューションは、組織の全トレースを網羅し、ヘッドベースのサンプリング手法ではなくテールベースの意思決定を重視します。これにより、特定の優先度特性でタグ付けされた完全なトレースを捕捉することが可能となります。
分散トレースの仕組みとその必要性
分散トレースは、マイクロサービスなどの分散ソフトウェアアーキテクチャ、特に動的なマイクロサービスアーキテクチャの監視、デバッグ、最適化に不可欠です。これは、リクエストが関与するすべてのサービスとの相互作用に関するデータを収集・分析することで、単一のリクエストを追跡します。
リクエストによってトリガーされる各アクティビティ(セグメントまたはスパンと呼ばれる)は、サービス内およびサービス間を移動する過程で記録されます。収集される情報には、名前、開始および終了のタイムスタンプ、その他のメタデータが含まれます。あるアクティビティ(「親」スパン)が完了すると、次のアクティビティはその「子」スパンに引き継がれます。分散トレースはこれらのスパンを正しい順序で配置します。
企業は、現代的なアプリケーション環境の複雑さを効率化するために分散トレースを必要としています。分散アプリケーションでは、アプリケーションスタック全体にわたり潜在的な障害発生ポイントが増加します。これは、問題発生時に根本原因を特定するのに非常に長い時間を要する可能性があることを意味します。この複雑さは、企業がSLAを維持し、優れたユーザー体験を提供する能力に直接影響を及ぼします。
分散トレースは、各マイクロサービスのパフォーマンスをチームが迅速に把握する手助けとなります。この理解により、問題の迅速な解決、顧客満足度の向上、安定した収益の確保、そしてチームのイノベーションのための時間確保が可能になります。これにより、企業は現代的なアプリケーション環境が提供するメリットを最大限に活用しつつ、その複雑性から生じる課題を最小限に抑えることができるのです。
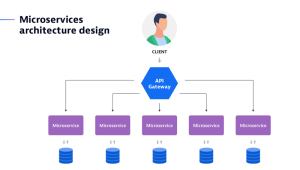
分散トレースはどのような場合に使用しますか?
複数のマイクロサービスがリクエストに関連付けられている場合、それらの間の関係性を理解し、リクエストを処理するためにどのように連携しているかを特定することはより困難になります。特にマイクロサービスやサーバーレスアーキテクチャにおいては、特定の疑問に迅速に答えを得るために分散トレースが不可欠です。
DevOps、運用チーム、サイトリライアビリティエンジニアリングは、以下の状況において分散トレースが有用であると考えています:
- 分散システム内のマイクロサービスの現在の健全性を把握すること;
- 同じ環境におけるエラーの根本原因を迅速に特定すること;
- 現在ユーザー体験に影響を与えている、あるいは潜在的に影響を及ぼす可能性のあるパフォーマンスのボトルネックを発見すること。
分散トレースは、特定のマイクロサービス内で問題のあるコードや非効率なコードを事前に最適化する戦略的資産ともなり得ます。
分散トレースとロギングの違いは何でしょうか?
ログファイルには分散トレースの重要な要素となる貴重な詳細情報が含まれますが、ロギングと分散トレースは同一ではありません。ログファイルの作成は科学であると同時に芸術でもあります。ログは適切なアクションをトリガーするのに十分な情報を含みつつ、システムリソースを圧迫しない軽量である必要があります。この違いを理解するには、まず2種類のロギングを認識することが役立ちます:
- 集中型ロギング
- 分散型ロギング
集中型ロギングとは何ですか?
集中型ロギングとは、サービスやコンポーネントが生成するログを単一の場所に集約・保存する活動記録手法です。これにより、チームはエラー報告や関連データを一元的に追跡することが可能となります。 マイクロサービス環境では、複数のマイクロサービスからのログを一元的な場所に集約することで、参照や分析を容易に行えるようにします。この種のロギングの焦点は、アプリケーション内で発生したエラーを特定し、その発生元となったマイクロサービスを特定することにあります。数千ものマイクロサービスがログデータを生成する分散環境では、この作業はより困難になります。
開発者にとっては便利ですが、集中型ロギングではシステムがログを発生元から単一ロケーションへ転送する必要があります。この手法はかなりのネットワークリソースを消費する可能性があります。その結果、他のアプリケーションやサービスに影響を与えるネットワークパフォーマンスの問題を引き起こす場合があります。
分散型ロギングとは何でしょうか?
これに対し、分散型ロギングとは、コンピューティング環境全体(多くの場合複数のクラウドにまたがる)に配置されたログに活動を記録する手法です。組織は、ログを常に単一ロケーションへ転送・保存する負担を軽減するため、集中型ロギングに代わるこのアプローチを選択することがあります。
一部のログストレージソリューションは、ログを生成するデバイスに近い場所に設置する必要があるなど、扱いが難しい場合もあります。複数のマイクロサービスで構成されるような大規模アプリケーションでは、継続的に大量のログが生成される傾向があります。このようなケースでは、チームは分散型ロギングアプローチを採用することを好むかもしれません。
チームは、ロギングと分散トレースを並行して利用することが可能です。組織はまずロギングから導入し、アプリケーション環境が複雑化するにつれて(例えばマイクロサービスを採用する場合など)、分散トレースを追加することが一般的です。
分散システムにおけるトレースの影響
分散トレースは、数百もの個別のシステムコンポーネントを経由するリクエストを容易に追跡できます。単なるリクエストのエンドツーエンドの経路記録にとどまらず、システムの健全性に関するリアルタイムの洞察も提供します。これにより、IT、DevSecOps、SREチームは以下のことが可能になります:
- アプリケーションおよびマイクロサービスの健全性に関するレポートを作成し、障害発生前に状態の悪化を特定します。
- 自動スケーリングに起因する予期せぬ動作を検知し、障害の予防と復旧を容易にします。
- 平均応答時間、エラー率、その他のデジタル体験指標の観点から、エンドユーザーがシステムをどのように体験しているかを分析します。
- インタラクティブなビジュアルダッシュボードで主要なパフォーマンス指標を監視します。
- システムのデバッグ、ボトルネックの特定、コードレベルのパフォーマンス問題の解決を行います。
- 目に見えない問題の根本原因を特定し、トラブルシューティングを行います。
従来の監視手法の限界
データに基づく意思決定を実現するという目的を達成するため、分散トレースはすべての環境から得られるオブザーバビリティデータに依存しています。従来のソフトウェア監視プラットフォームは、主に以下の3つの形式でオブザーバビリティデータを収集します。これらはしばしばオブザーバビリティの3本柱と呼ばれています:
- ログ。イベントまたは一連のイベントのタイムスタンプ付き記録。
- メトリクス。一定期間に測定されたデータを数値で表したものです。
- トレース。単一リクエストの経路に沿って発生したイベントの記録。
従来、プラットフォームはこのデータを効果的に活用してきました。例えば、単一アプリケーションドメイン内でのリクエスト追跡などが挙げられます。コンテナ、Kubernetes、マイクロサービスが登場する前は、モノリシックシステムの可視化は容易でした。しかし、今日の非常に複雑で分散化された環境においては、こうしたデータではシステム健全性の包括的な把握が困難です。
ログ集約、つまり多数の異なるサービスからのログを統合する手法は良い例です。個々のサービス群内の活動状況のスナップショットを提供することはできますが、ログには文脈メタデータが欠如しているため、数百万ものアプリケーション依存関係を通って下流へ伝播するリクエストの全体像を把握することはできません。この手法だけでは、分散システムにおけるトラブルシューティングには不十分です。ここで必要となるのがオブザーバビリティ、特に分散トレースです。
単純な監視とは異なり、オブザーバビリティとはアプリケーションやサービスを理解し可視化する基準です。事前に定義されていない環境内の特性やパターンを探索するのに役立ちます。分散トレースは、現代の企業が求めるオブザーバビリティを実現するために不可欠な複数の機能の一つです。
分散システムにおけるトレースの影響
分散トレースは、数百もの個別のシステムコンポーネントを横断するリクエストを容易に追跡でき、リクエストのエンドツーエンドの経路を記録するだけにとどまりません。システムの健全性に関するリアルタイムの洞察も提供します。これにより、IT、DevSecOps、SREチームは以下のことが可能になります:
- アプリケーションおよびマイクロサービスの健全性に関するレポートを作成し、障害発生前に状態の悪化を特定します。
- 自動スケーリングに起因する予期せぬ動作を検知し、障害の予防と復旧を容易にします。
- エンドユーザーがシステムをどのように体験しているかを、平均応答時間、エラー率、その他のデジタル体験指標の観点から分析します。
- インタラクティブなビジュアルダッシュボードで主要なパフォーマンス指標を監視します。
- システムのデバッグ、ボトルネックの特定、コードレベルのパフォーマンス問題の解決を行います。
- 目に見えない問題の根本原因を特定し、トラブルシューティングを行います。
分散環境のためのクラウドインテリジェンス
分散トレースは、アプリケーションスタック全体を移動するリクエストの完全な経路を明らかにすることで、組織にアプリケーションパフォーマンスに関する重要なインサイトを提供します。組織がより迅速な変革のためにモダンなクラウドネイティブアプリケーションへの依存度を高める中、アプリケーション環境に対する包括的なオブザーバビリティを獲得することが不可欠です。分散トレースにより、チームはアプリケーションパフォーマンス問題の根本原因を迅速に特定し(多くの場合、ユーザーが気付く前に)、高品質なユーザー体験を確保できます。




ご質問がございましたら
Q&Aフォーラムで新しいディスカッションを開始するか、ご支援をお求めください。
フォーラムへ