
将来の競争力を維持したいと考える組織にとって、人工知能(AI)の導入はますます不可欠となっています。しかし、AIのメリットは一見したほど単純ではありません。
汎用モデルは多くの組織が生成AI(GenAI)の導入を開始する上で役立ちますが、企業利用に向けたAIの拡張には大きな課題が伴います。専門的な人材、モデルの管理・展開のための新たな技術スタック、増加するコンピューティングコストに対応する十分な予算、そしてエンドツーエンドのセキュリティが必要となります。多くの組織は、どのユースケースがAI投資に対して最大の利益をもたらすかさえ検討していません。
本ブログ記事では、AIの可観測性が組織にコスト、パフォーマンス、データ信頼性の予測と制御を可能にする仕組みを考察します。また、組織が生成AIを導入する中で、データ可観測性がビジネス成果とどのように関連するかも示します。
企業におけるAIアプリケーション導入の課題
組織がAIを導入するにあたり、AI可観測性を検討すべき理由はいくつかあります。
予測不可能なコスト。多くの組織は、AIイニシアチブに先行または付随するクラウド移行計画の推進において、重大な課題に直面しています。戦略的計画段階でライフサイクルコスト全体を十分に考慮しないことは重大な問題であり、当初AIを先駆的に導入した組織の一部が、予期せぬコストの圧力によりクラウドから撤退する事態を招いています。さらに悪いことに、生成AIに関連するコストは単純ではなく、多くの場合多層的であり、従来のクラウドサービスの5倍に達する可能性があります。
サービスの信頼性。ジェネレーティブAIは、過去50年間コンピューティングを支配してきたコマンドベースのインタラクションモデルやグラフィカルユーザーインターフェースからの根本的な転換を意味します。ジェネレーティブAIツールは人間と機械のより会話的で自然な相互作用を促進しましたが、サービスの信頼性が課題となっています。ジェネレーティブAIは、予期せぬデータシナリオや基盤システムの課題により不安定な動作を起こしやすい性質があります。タイムリーかつ正確な回答を提供できないことは、ユーザーの信頼を損ない、導入を妨げ、継続利用率を低下させます。ベンチャーキャピタル企業セコイアの調査によれば、大規模言語モデル(LLM)アプリケーションの利用率は従来の消費者向けアプリケーションに遅れをとっており、日次アクティブユーザーはわずか14%に留まっています。
サービス品質。情報の質と正確性は極めて重要です。しかしながら、正しい回答が直ちに明らかになるとは限りません。LLMは「幻覚」を起こしやすく、人間のバイアスを増幅させ、高度にパーソナライズされた出力の生成に苦戦します。AI幻覚とは、LLMが存在しない、あるいは人間の観察者には感知できないパターンを認識し、意味不明または完全に不正確な出力を生成する現象です。
その結果、AIモデルのドリフトと幻覚が主要な懸念事項として浮上しています。例えば、スタンフォード大学とカリフォルニア大学バークレー校の研究チームは、研究論文においてChatGPTの挙動が時間とともに劣化することを指摘しました。同チームは、同一のLLMサービスの挙動が比較的短期間で退行することを発見し、LLMの品質を継続的に監視する必要性を強調しています。
検索拡張生成(RAG)は、LLMベースのアプリケーションにおける標準アーキテクチャとして台頭しています。
LLMが事実誤認や意味不明な応答を生成する可能性があることを踏まえ、検索強化生成(RAG)がGenAIアプリケーション構築の業界標準として台頭しています。RAGはユーザーのプロンプトを、LLM外部から検索された関連データで補完します。この方法でLLM入力を強化することで、トレーニングデータにおける明らかな知識の欠落を補い、AIの幻覚現象を抑制します。
RAGプロセスは、ユーザープロンプトを要約・変換し、検索プラットフォームへ送信するクエリを生成することから始まります。検索プラットフォームは、ベクトルデータベース、セマンティックキャッシュ、その他のオンラインデータソースから、意味的類似性に基づいて関連データを見つけ出します。検索されたデータは、LLMが応答を作成するための完全な文脈を提供するため、プロンプトと共にLLMへ送信されます。
チャットボットを例に挙げますと、ユーザーが自然言語プロンプトを送信すると、RAGはそのプロンプトをセマンティックデータを用いて要約します。変換されたデータは検索プラットフォームに送信され、クエリに関連するデータが検索されます。関連データは関連性スコア(例:セマンティック距離、つまり複数のデータポイント間の関連性を定量的に測定した値)に基づいてソートされます。最も関連性の高いデータがプロンプトと共にLLMに送信されます。LLMは取得したデータと拡張されたプロンプト、および内部のトレーニングデータを統合し、ユーザーに返送可能な応答を生成します。
このアプローチはGenAIアプリケーションの応答品質を大幅に向上させますが、新たな課題も生じます。データ依存関係やフレームワークの複雑性により、インフラストラクチャやモデル性能からセマンティックキャッシュ、ワークフローオーケストレーションに至るまで、AI搭載アプリケーションのライフサイクルをエンドツーエンドで監視する必要があります。
DynatraceはAIアプリケーションのエンドツーエンドの可観測性を提供します
AIシステムの複雑化が進む中、AI搭載アプリケーションの可観測性に対する包括的なアプローチはますます重要となります。Dynatraceは、メトリクス、ログ、トレース、問題分析、根本原因情報をダッシュボードやノートブックに統合し、クラウドアプリケーションのエンドツーエンドで統一された運用ビューを提供します。

DynatraceのAI可観測性により、基盤となるモデルやベクトルデータベースのメトリクスから、最新のRAGアーキテクチャをカバーするオーケストレーションフレームワークに至るまで、現代アプリケーションのAIスタック全体を可視化します。これにより、多様なレイヤーにわたる現代アプリケーションのライフサイクル全体を把握することが可能となります:
- インフラストラクチャ:利用率、飽和状態、エラー
- モデル:精度、精密度/再現率、説明可能性
- セマンティックキャッシュとベクトルデータベース: ボリュームと分布
- オーケストレーション:パフォーマンス、バージョン、劣化
- アプリケーションの健全性:可用性、レイテンシ、信頼性
AIインフラストラクチャと機械学習の環境への影響を可視化
大規模言語モデル(LLM)のトレーニングやジェネレーティブAIアプリケーションの運用コストは確かに大きいですが、企業がAI戦略において考慮すべき唯一の要素ではありません。AIツールの開発と需要の拡大に伴い、その環境コストに対する懸念も高まっています。LLMの構築には膨大な電力が消費され、多量の熱が発生します。研究者らの試算によれば、ChatGPTの開発には1,287メガワット時の電力が必要で、552トンのCO2を排出しました。これはガソリン車123台が1年間走行する排出量に相当します。しかしエネルギー消費はモデルトレーニングに留まらず、その運用段階でもさらに大きな影響を与えます。例えば画像生成には、スマートフォンをフル充電するのと同等の電力が必要です。
半導体メーカーのNVIDIA社は、2027年までに年間150万台のAIサーバーユニットをリリースする可能性があり、年間75.4テラワット時以上の電力を消費すると推定されています。これは一部の国々の年間消費量を上回る規模です。
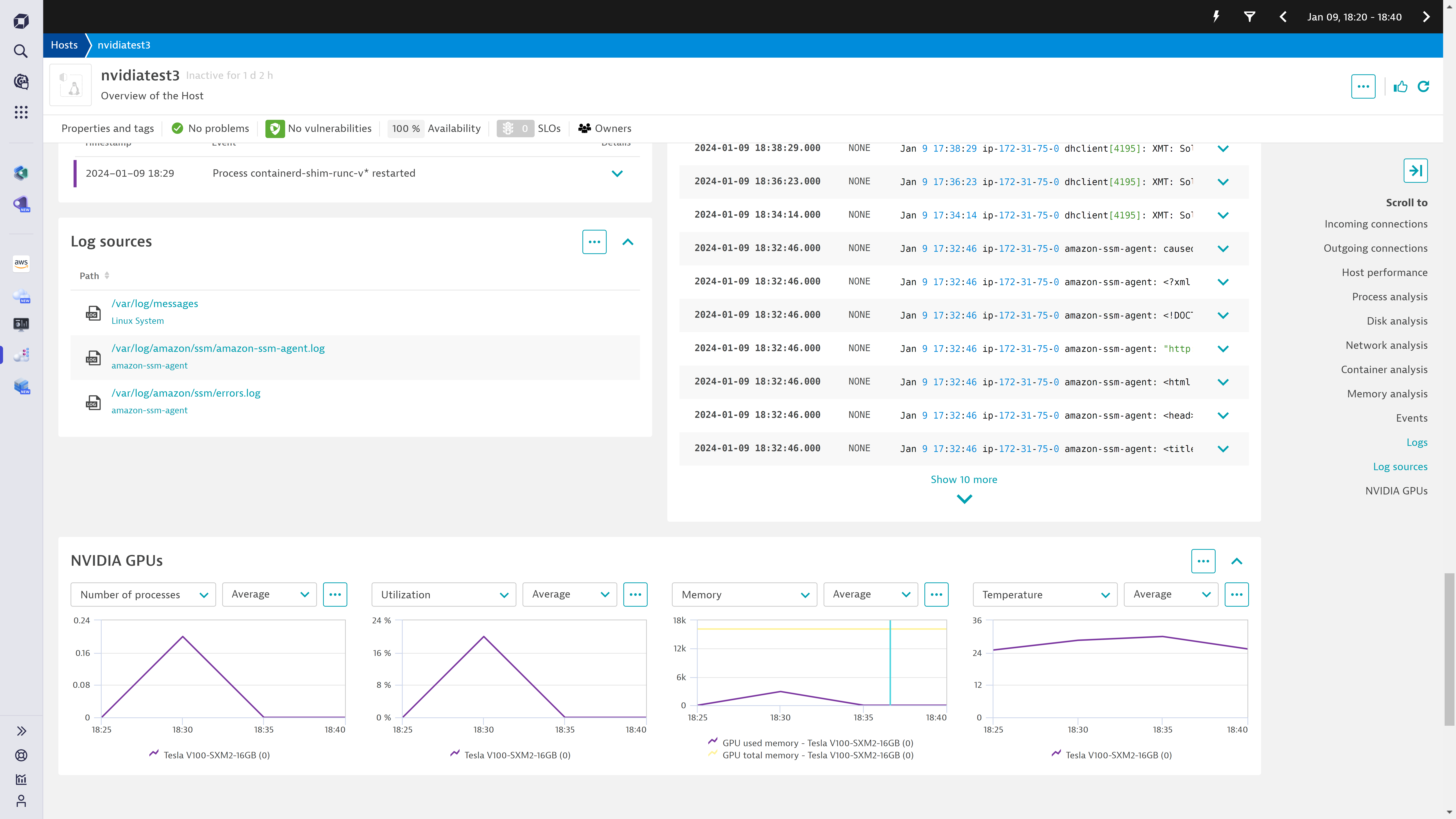
企業がより持続可能な製品を構築できるよう支援するため、DynatraceはAmazon Elastic Inference、Google Tensor Processing Unit、NVIDIA GPUなどのAIインフラとシームレスに連携し、温度、メモリ使用率、プロセス使用状況などのインフラデータを監視することで、最終的にカーボンリダクション(炭素削減)の取り組みを支援します。
AIモデルの可視化
大規模なAIモデルの実行は、リソースを大量に消費する可能性があります。モデルの可観測性により、リソース消費量や運用コストを可視化でき、最適化を支援し、利用可能なリソースを最も効率的に活用することを保証します。
OpenAI、Amazon Translate、Amazon Textract、Azure Computer Vision、Azure Custom Visionなどのクラウドサービスやカスタムモデルとの統合により、モデル監視のための堅牢なフレームワークを提供します。本番環境のモデルにおいては、トークン消費量、レイテンシ、可用性、応答時間、エラー発生件数といったサービスレベル契約(SLA)のパフォーマンス指標の可観測性を実現します。
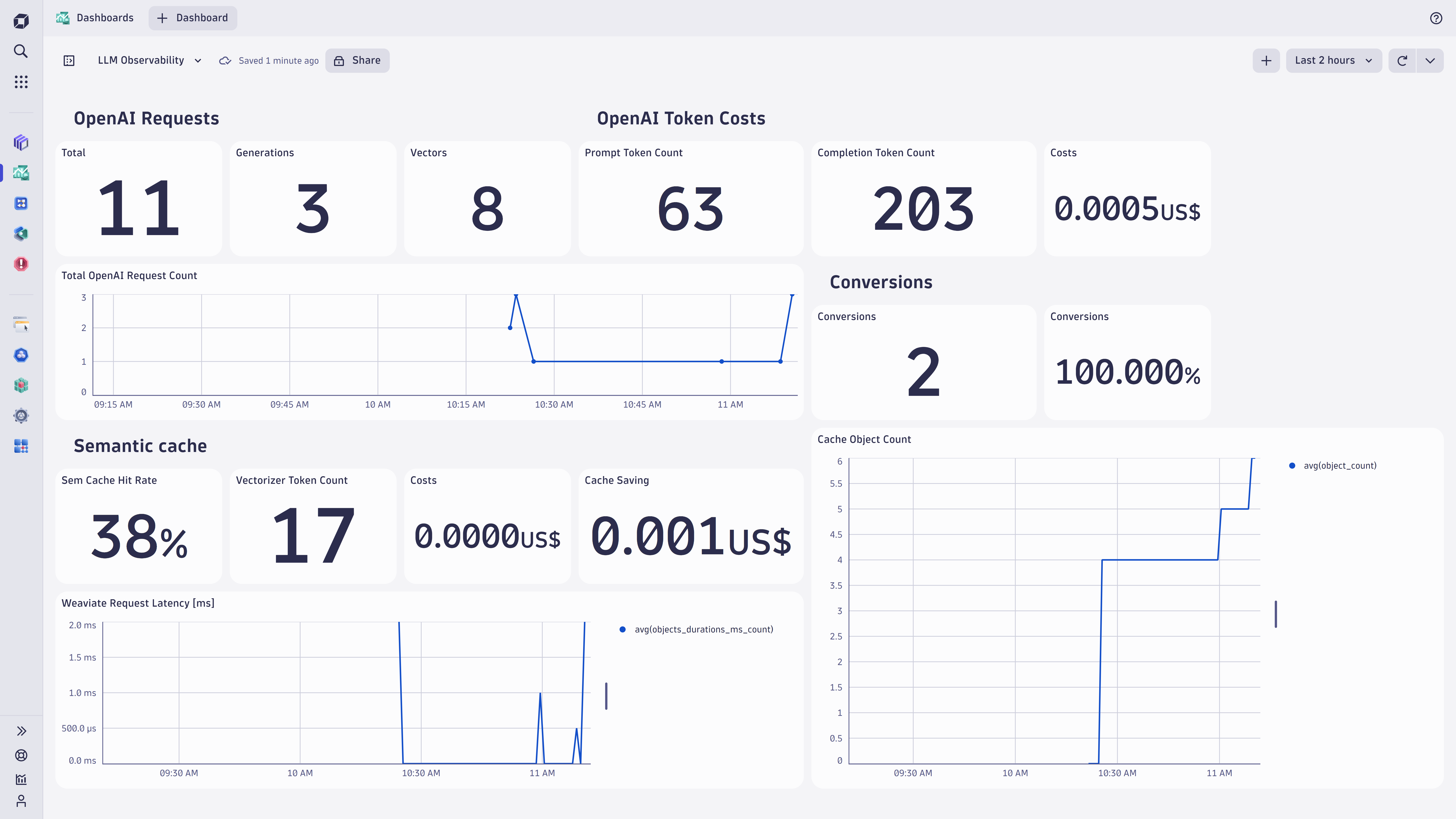
SLAを超えて、機械学習の技術的負債の出現は、モデルの可観測性にとってさらなる課題をもたらします。特に新しいデータが入ってくる中で、運用中の機械学習モデルを展開・監視する際には、回帰やモデルドリフトの管理が極めて重要です。
モデルドリフトと精度を観察するため、企業はモデルデータとの比較用にホールドアウト評価セットを利用できます。モデルの解釈可能性については、カスタム回帰テストを実装することで、時間の経過に伴うモデルの信頼性と挙動の指標を提供できます。
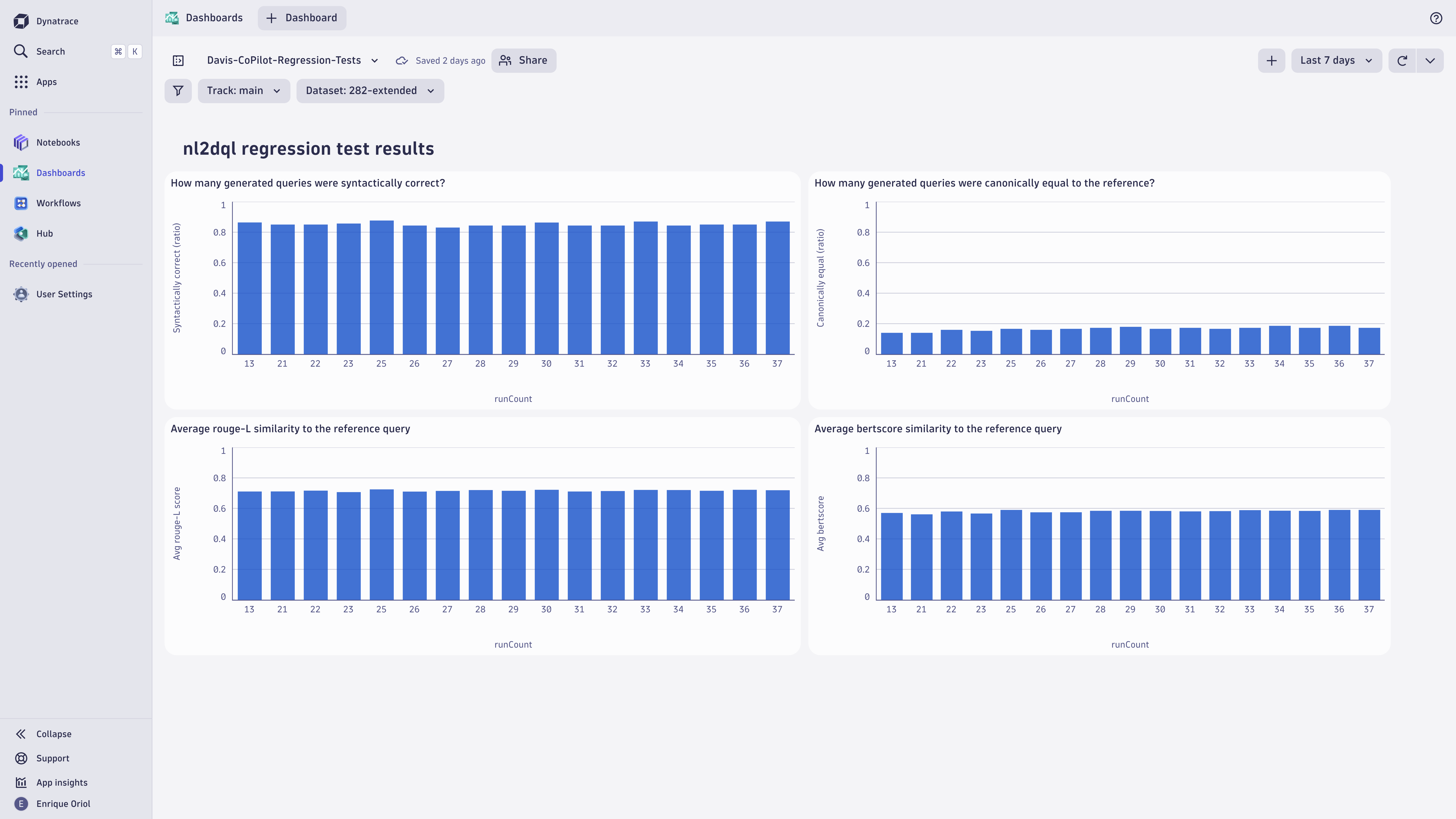
セマンティックキャッシュとベクトルデータベースの監視
RAGフレームワークは、LLMに文脈的に関連性の高い情報を提供することで、LLMを活用したアプリケーションのパフォーマンスを向上させる、費用対効果が高く実装が容易な手法であることが実証されています。これにより、モデルの継続的な再トレーニングや更新の必要性を排除しつつ、幻覚現象のリスクを軽減することが可能です。
しかしながら、RAGは完璧ではなく、特にベクトルデータベースやセマンティックキャッシュの使用に関して様々な課題が生じます。こうした検索と生成の側面における課題に対処するため、DynatraceはMilvus、Weaviate、Chromaなどのセマンティックキャッシュやベクトルデータベースに対する監視機能を提供します。
これにより、お客様は検索拡張生成システムの有効性を把握し、プロンプトエンジニアリング、検索・取得、および全体的なリソース利用の最適化を実現するツールを入手できます。
オーケストレーションフレームワークの監視
LLMやその他のモデルが利用する知識は、これらのモデルが学習に使用されたデータに限定されます。モデル学習の終了時点以降に追加されたデータやプライベートデータを統合できるAIアプリケーションを構築するには、プロンプトエンジニアリングと検索強化生成を用いて、モデルに必要な特定情報を補完する必要があります。
LangChainなどのオーケストレーションフレームワークは、アプリケーション開発者にRAGアプリケーション構築を支援する複数のコンポーネントを提供します。まず、外部データソースからデータを取得しインデックス化するパイプラインを提供します。
次に、実際のRAGチェーンをサポートし、実行時にユーザークエリを受け取り、インデックスから関連データを検索し、それをモデルに渡します。
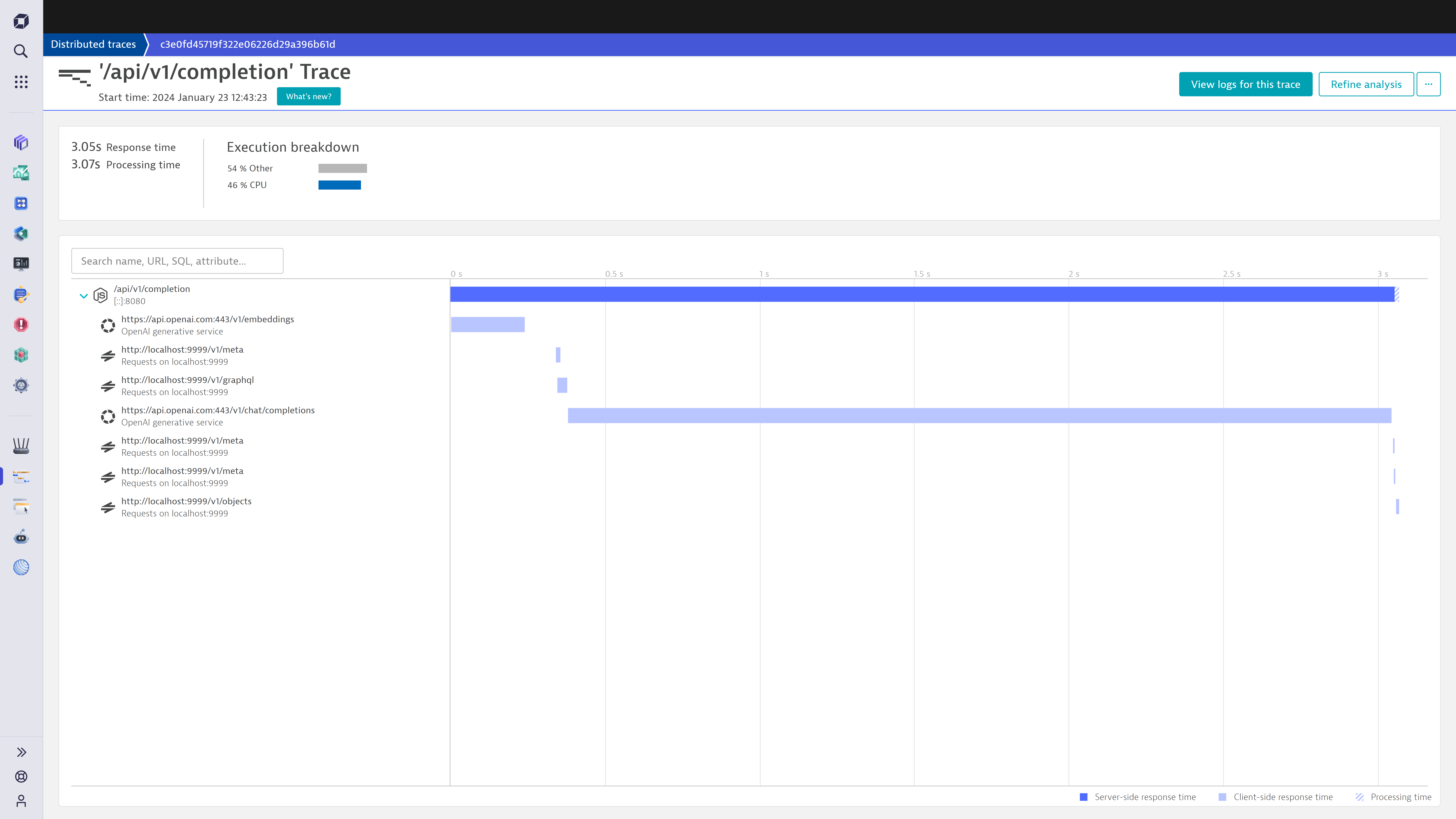
LangChainなどのフレームワークとの統合により、分散リクエストのトレースがシームレスになります。この機能により、システムの問題を早期に検出できるため、サービス停止が発生する前にパフォーマンスの低下を防ぐことが可能です。組織は、プロンプトから応答までのエンドツーエンドの詳細なワークフロー分析、リソース配分の洞察、実行の洞察から恩恵を受けます。
Dynatrace は、以下に示すように、各 LangChain タスクのログ、メトリクス、トレースを活用し、コスト、プロンプトおよび完了のサンプリング、エラー追跡、パフォーマンス指標に関する洞察を提供します。
AIの可観測性は、ビジネス成功に向けたAIの最大限の活用を支援します
ジェネレーティブAIへの初期投資は高額であり、組織は効率向上とコスト削減を通じてのみ投資利益率(ROI)を得られる場合が多くあります。しかし、組織はどのユースケースが最大のROIをもたらすかを検討する必要があります。複雑さと影響力のバランスを見極めることは、AI戦略を採用する組織にとって最優先事項でなければなりません。
組織はAIの進展を常に把握する必要があり、AI導入は計画可能な単発のイベントではありません。AI導入には継続的なマインドセットの転換が求められ、組織はAIアプリケーションの技術スタックを超えた、サービス構築・強化の全プロセスを検証・観察する必要があります。Dynatraceは、AIコストをビジネスケースと持続可能性に結びつけ、予測的なオーケストレーションの支援により、信頼性の高い新たなAI支援サービスを提供することを可能にし、エンドツーエンドでの顧客体験の最適化を支援します。Dynatraceのリアルユーザーモニタリング(RUM)機能は、パフォーマンスのボトルネックと根本原因を自動的に特定し、複雑なシステム設計の理解や微妙な隠れたコストを含む包括的なアプローチへの需要を満たします。
顧客の成功への取り組みは、自社においてもAI可観測性を活用し、Dynatrace内で成功したAIベースのアプリケーションを提供している点に顕著に表れています。例えば、トークンカウントに基づき、信頼性を向上させるだけでなく、プロンプトエンジニアリングの可能性を調査する道筋を拓き、応答時間を短縮するためのRAGパイプライン設計改善策を導き出す開発戦略を策定しました。また、キャッシュヒット率の監視により、AzureOpenAIエンドポイントの埋め込み計算におけるモデルドリフトを検出することができ、マイクロソフト社がバグを特定・解決する一助となりました。
生成AIの監視技術の未来
成長促進から効率化・コスト削減に至るまで、生成AIの導入は業界におけるパラダイムシフトを意味します。これは、中核的な技術革新が既存のビジネスモデルを破壊するという歴史的パターンと一致する傾向です。ビジネス史を通じて、画期的な技術の登場は常に破壊的変化をもたらしてきました。こうした革新に適応できない企業は淘汰の危機に直面します。93%の企業が生成AI統合のリスクを認識しているにもかかわらず、リスク軽減のギャップが企業の望ましいペースでの進展を妨げています。
ジェネレーティブAI市場は2032年までに1.3兆ドル規模に成長すると予測される中、DynatraceはAI可観測性ソリューションにより、この重要なリスク軽減のギャップを埋めてまいります。お客様のフィードバックを基に、当社の技術は急速に進化を続けております。これにより、大規模な成功を収めるGenAIアプリケーション構築を支援することが可能となっております。Dynatraceは、AIスタックのあらゆる側面に対する比類なき洞察を提供する、約700の統合機能を備えた広範なスイートを提供しております。インフラストラクチャやモデルの監視からサービスチェーンの分析まで、Dynatraceは包括的な可観測性とセキュリティソリューションを提供いたします。
これらの統合機能を活用し、最適化されたAIパフォーマンスへの道程を始めるには、シームレスな導入のためのAI/ML可観測性ドキュメントをご覧ください。AIサービスの品質と信頼性の基準を再定義する取り組みに、ぜひご参加ください。




ご質問がおありですか?
Q&Aフォーラムで新しいディスカッションを開始するか、お助けください。
フォーラムへ