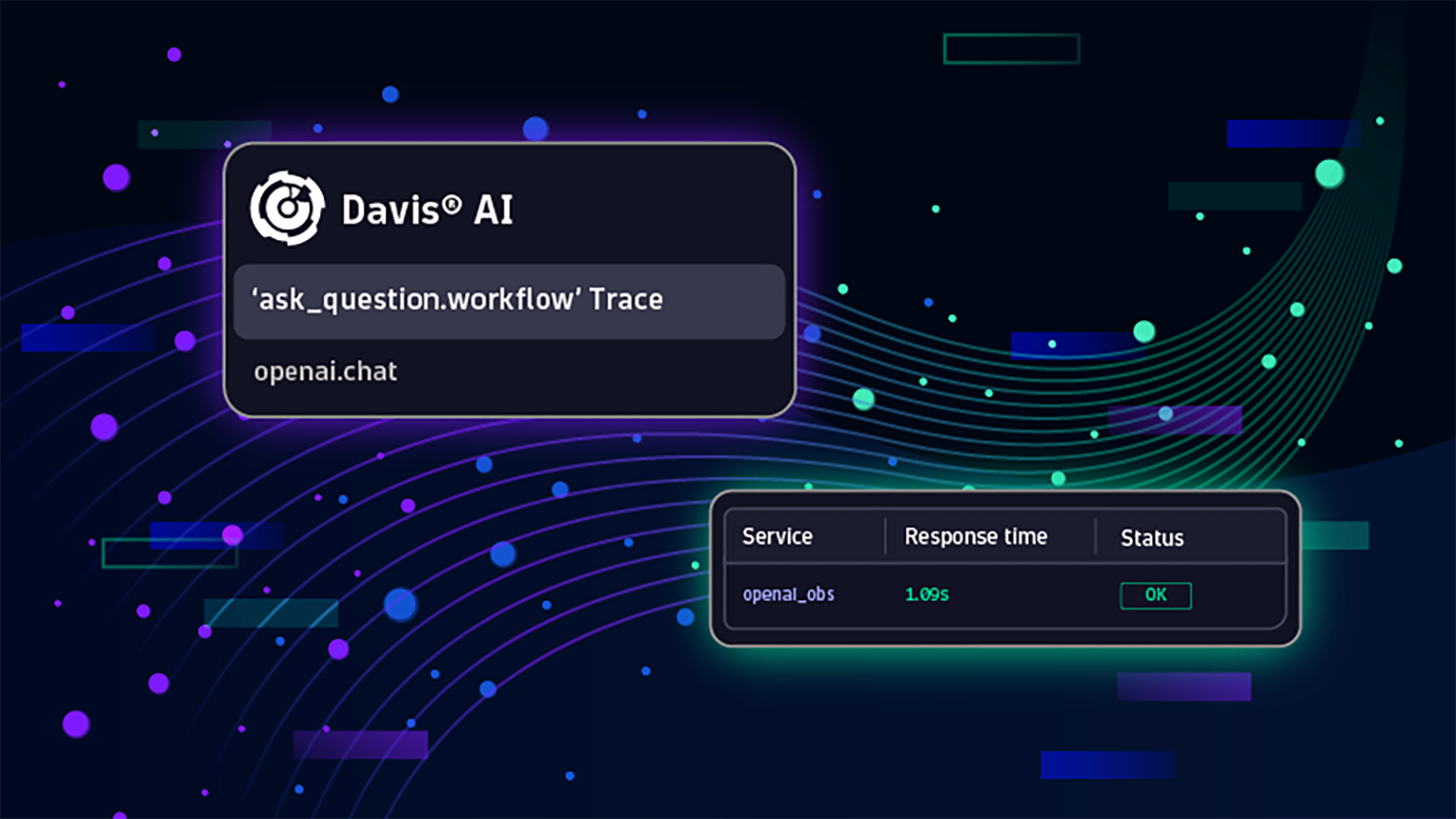
Dynatrace monitors OpenAI for reliable services.
Dynatrace tracks OpenAI/GPT requests, spotting issues in service behavior, aiding in pinpointing slowdowns as a platform feature for years, enduring customer demands.
Read more


Monitoring specific platform metrics and logs, such as memory, accelerator and CPU utilization

Get insights into Google AI Platform service metrics collected from the Google Operations API to ensure health of your cloud infrastructure.

Build, train, and deploy machine learning (ML) models quickly.

Robust, cloud-based service that makes it easy for developers of all skill levels to use machine learning technology.
coming soon
Observe the training progress of TensorFlow Keras AI models

Collection of services and tools intended to help developers train and deploy machine learning models.
Get insights about costs, prompt and completion sampling, error tracking, and performance metrics using logs, metrics, and traces of each specific workflow action
Monitor semantic caches and vector databases to optimize prompt engineering, search and retrieval, and overall resource utilization

Gain insights about vector database resource utilization and cache behavior

Observe your semantic cache efficiency to reduce cost and latency for LLM apps

Gain insights about your Qdrant semantic vector collections

Monitor Elasticsearch Clusters, Nodes, Indexes, remotely or locally, via API.
Observe service-level performance (SLA) metrics such as token consumption, latency, availability, response time, and error count

Start monitoring your OpenAI services such as GPT-3, Codex, DALL-E or ChatGPT.

Makes it easy to add document text detection and analysis to your applications.

Text translation service using machine learning to provide high-quality translation on demand.

AI service to boost content discoverability, automate text extraction, analyze video in real time, and more.
Monitor infrastructure data, including temperature, memory utilization, and process usage to ultimately support carbon-reduction initiatives
Are you looking for something different?
We have hundreds of apps, extensions, and other technologies to customize your environment