
AI and LLM Observability
Monitor, optimize, and secure Generative AI applications, LLMs, and agentic workflows — improving performance, explainability, and compliance.
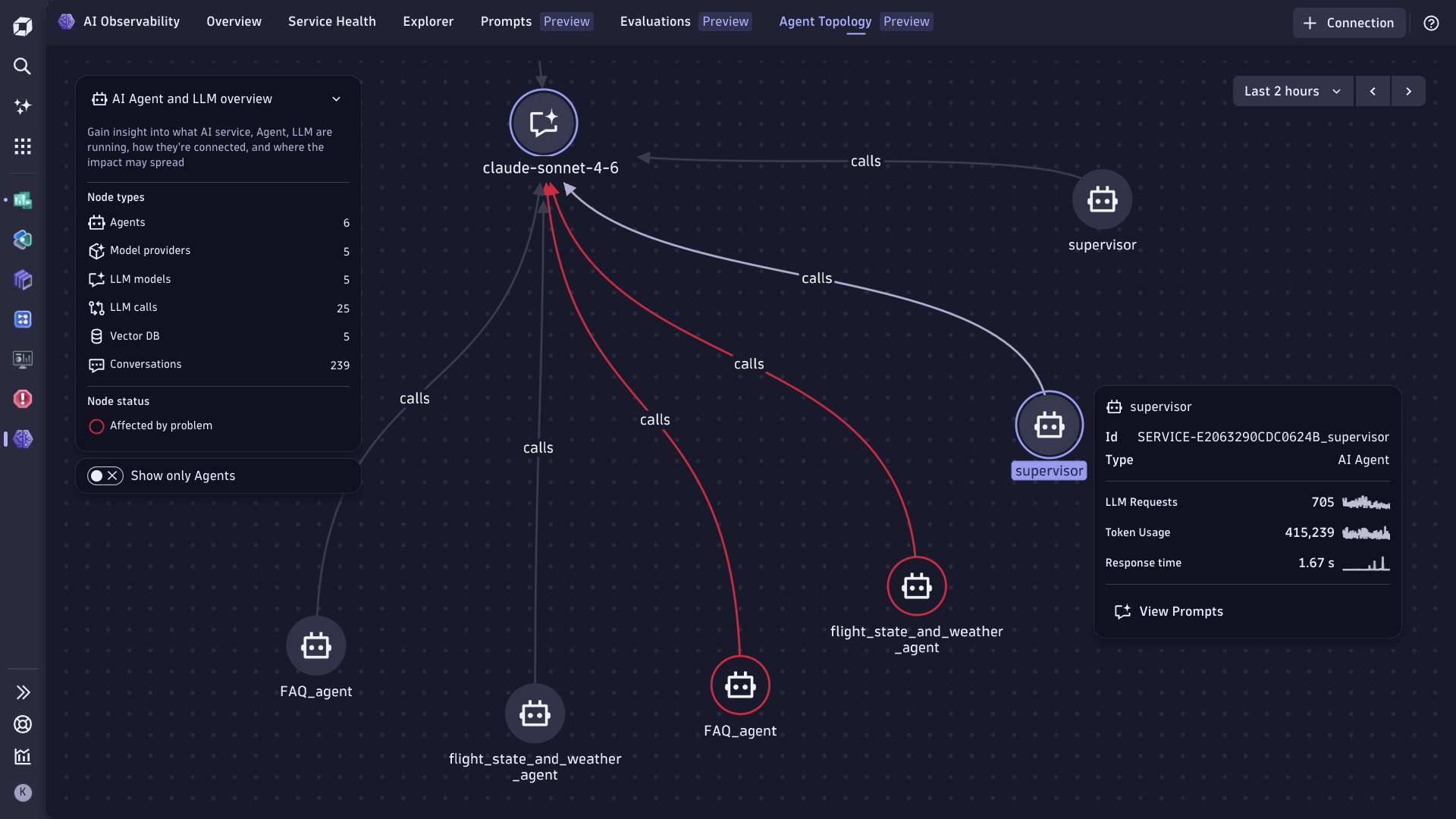


Integrate and observe
Integrate and observe every AI stack layer — from user applications to LLMs and infrastructure — with native support for top AI platforms.
Track how AI creates productivity gains, deflects support tickets, acts autonomously, and delivers return on investment.
Trace end-user experience, availability, and reliability of AI-powered applications.
Track chain performance, guardrails, and prompt caching across orchestration frameworks.
Observe agent protocols, command execution, tool usage, and multi-agent communications.
Assess token usage, cost, stability, latency, invocation errors, and resource utilization of model outputs.
Monitor RAG pipelines, data volume, distribution, and retrieval patterns.
Track utilization, saturation, and errors across GPUs, TPUs, and compute resources.


End-to-end observability for Agentic AI, Generative AI, and LLMs
Reduce cost and improve performance of your Agentic, AI, and LLM stack
- Monitor operational metrics for Gen AI applications like token cost, request duration, problems with unified and customizable dashboards that drive proactive action.
- Leverage intelligent detection to identify changes in user behavior, predict cost increases, and proactively make changes to manage costs.
- Reduce AI agent and LLM response times and improve reliability by analyzing traces for the slowest requests and errors.
- Compare different AI model performance with A/B testing insights to make informed decisions about which models to deploy in production.
- Monitor token costs, tool behavior and reliability across all your AI coding agents from a unified observability layer.
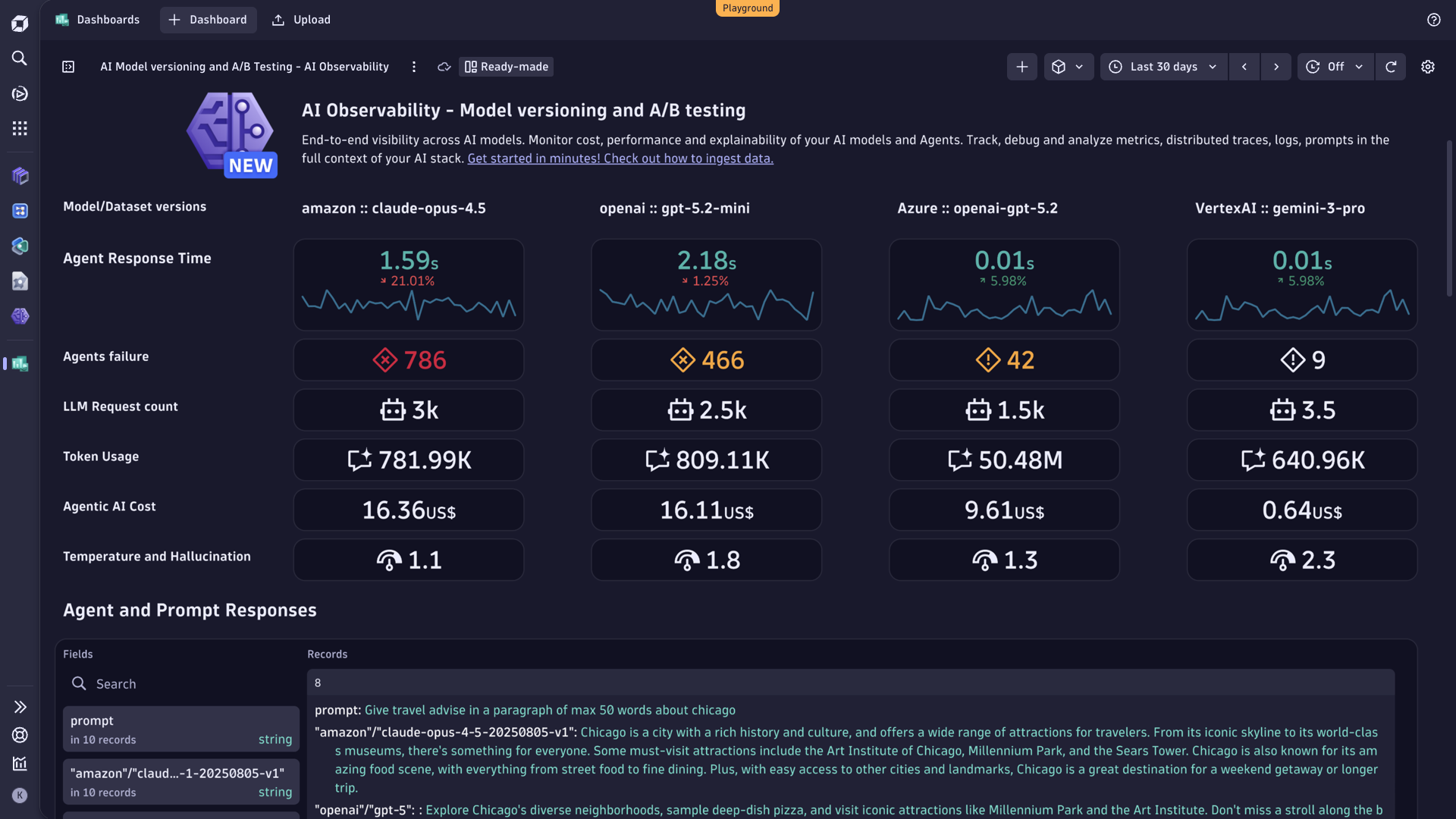
Build trust, monitor guardrails of LLM input and output
- Safeguard the quality of AI applications by monitoring and analyzing guardrail metrics to mitigate potential biases, errors, and misuse of AI systems.
- Recognize model hallucinations, identify attempts at LLM misuse such as malicious prompt injection.
- Prevent Personally Identifiable Information (PII) leakage, and detect toxic language.
- Analyze the effectiveness of LLM guardrails and make necessary adjustments to ensure optimal user experience and safety.
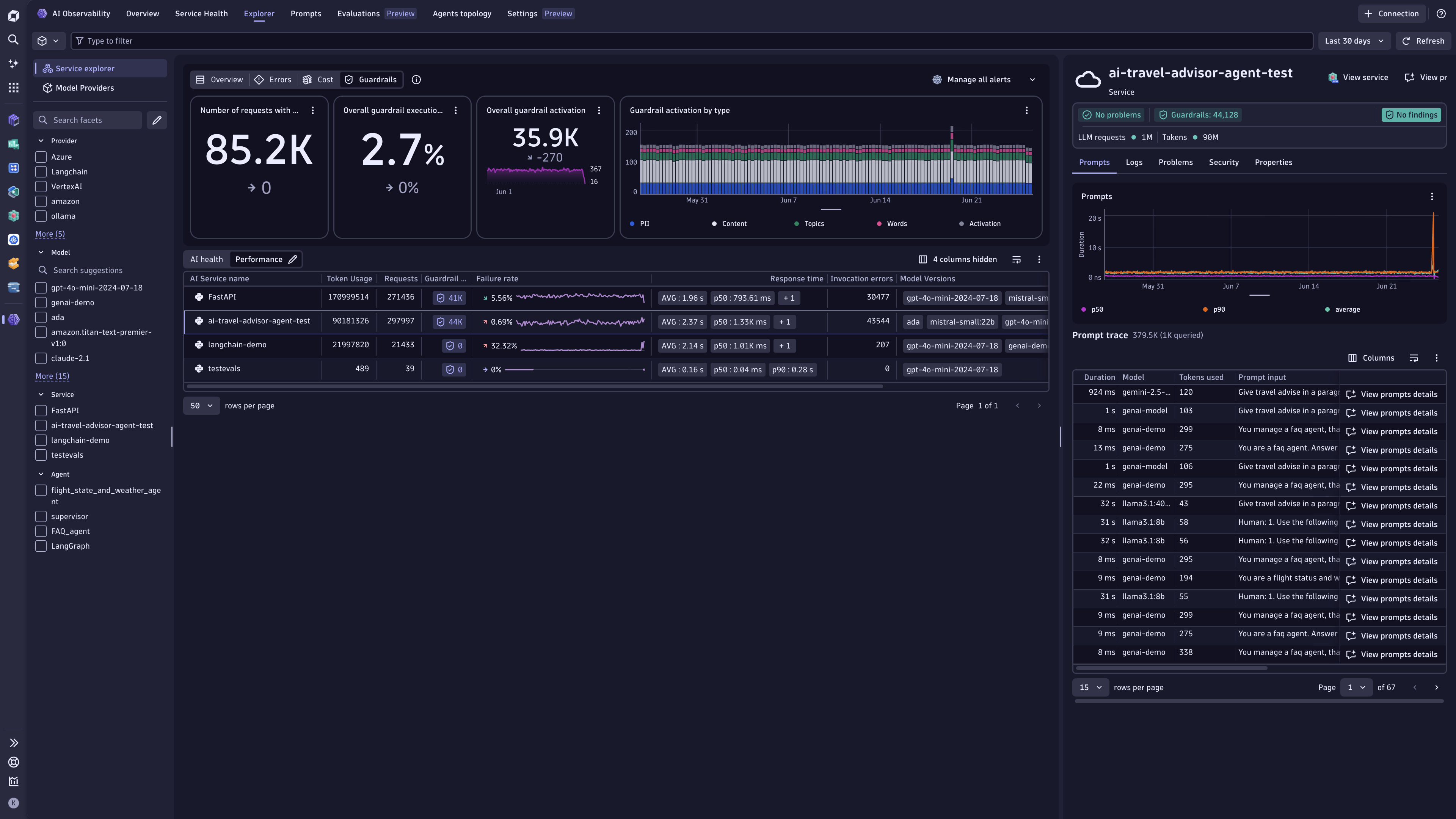
Explain, log, and trace back your AI service outputs
- Gain end-to-end visibility into the execution of each user request, with tracing, logs to cover the full application stack: frontend, backend, orchestrations, RAG, LLM and agentic layers.
- Log, trace, and map dependencies between your services, spanning across your architecture.
- Intelligent detection to automatically pinpoint the root cause of errors and failures in the LLM chain and proactively accelerate resolution before impacting customers.
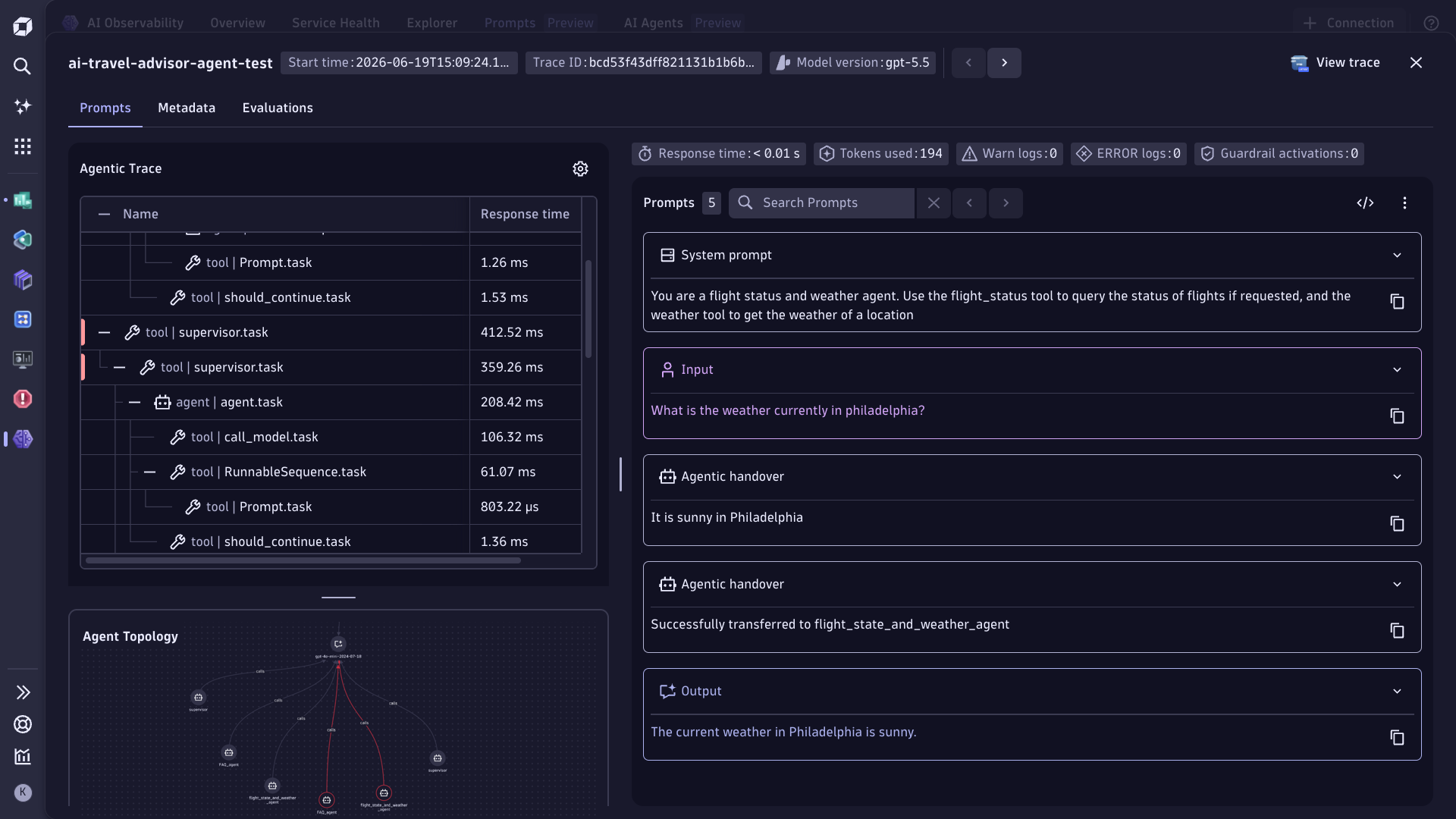
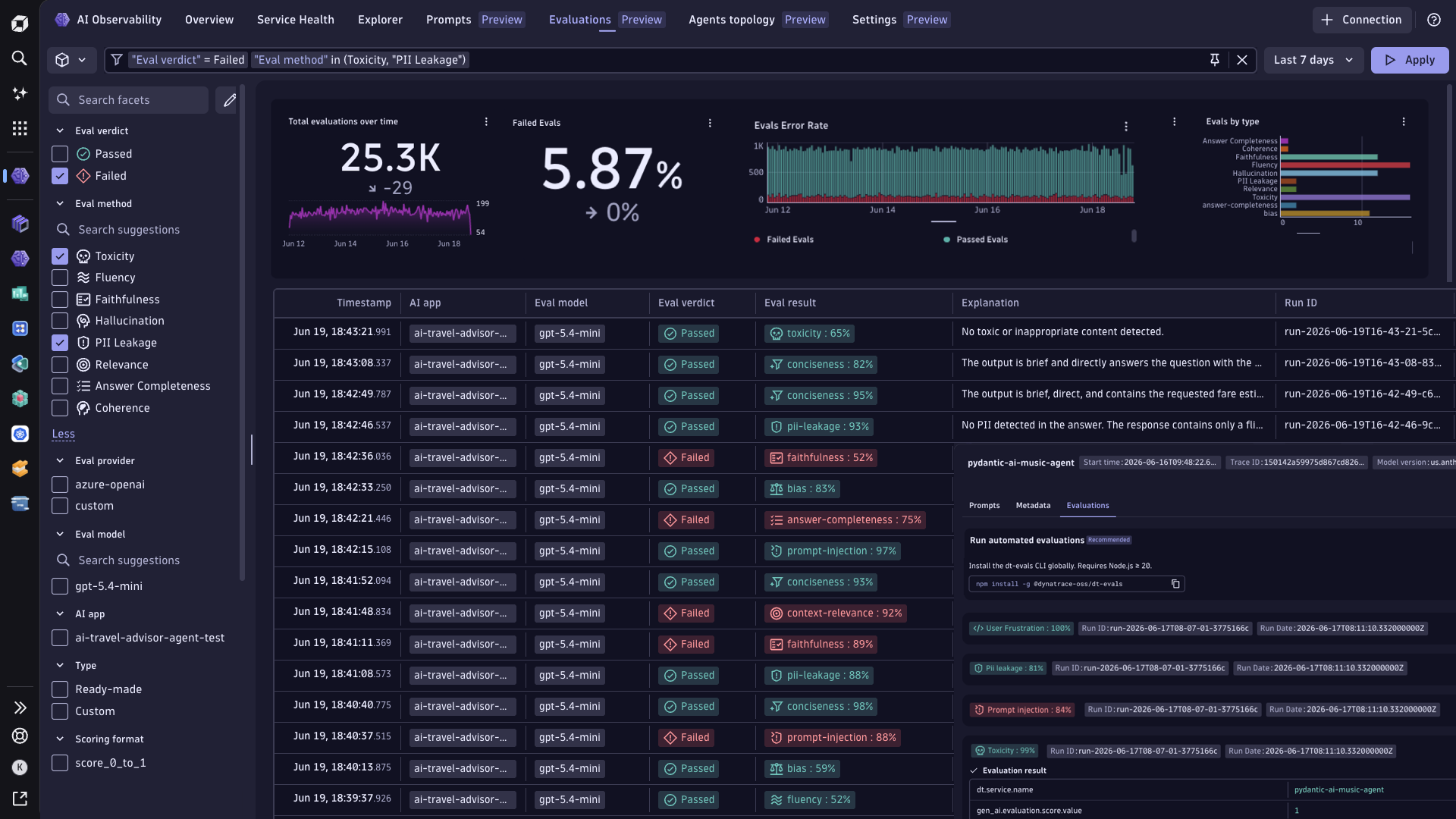
AI Evaluations / LLM-as-a-judge to safeguard AI answer quality across every stage of agentic lifecycle
- Continuously measure the accuracy, relevance, and grounding of your AI agent or LLM outputs against production traces, catching off topic responses and hallucination before they reach users.
- Detect model drift, safety and quality issues with evaluations - eval scores, LLM-as-judge, toxicity detection and more.
- Compare evaluation scores across prompt and model versions to catch silent quality drops early.
- Set alerts on evaluation scores to get notified the moment quality drifts, not when a customer complains. Measure user frustration signals before they become support tickets.
- Monitor answer quality across the agentic lifecycle, surfacing hallucinations, low relevance, and ungrounded responses so teams can fix issues at the source.
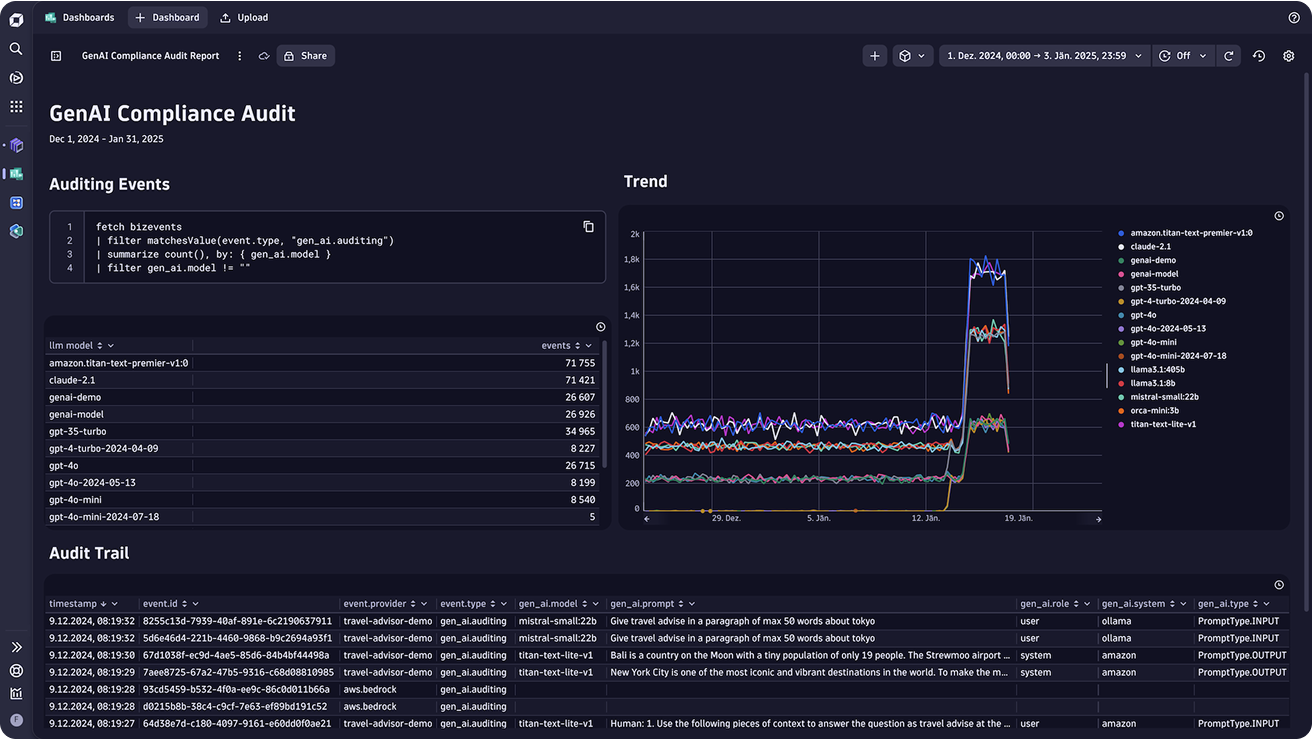
Reduce compliance risk and secure your GenAI applications
- Comprehensively and cost effectively document all inputs and outputs, maintaining full data lineage from prompt to response to build a clear audit trail to ensure compliance with regulatory standards.
- Store up to 10 years all of your prompts.
- Build dashboards to visualize the behavior and performance of AI systems to make their operation more transparent and prove compliance.
- Support carbon-reduction initiatives by monitoring infrastructure data, including temperature, memory utilization, and process usage.

Join the Dynatrace Partnership program

Resources
 WhitepaperFull-Stack AI Observability That Increases ROI and Decreases Business Risks
WhitepaperFull-Stack AI Observability That Increases ROI and Decreases Business Risks BlogEvaluate LLM and agent quality in Dynatrace AI Observability with dt-evals
BlogEvaluate LLM and agent quality in Dynatrace AI Observability with dt-evals- BlogDynatrace expands AI Coding Agent monitoring for Claude Code, Google Gemini CLI, Codex CLI, OpenCode, and GitHub Copilot SDK
- BlogAnnouncing agentic framework support and General Availability of the Dynatrace AI Observability app
 BlogAnnouncing Amazon Bedrock AgentCore Agent Observability
BlogAnnouncing Amazon Bedrock AgentCore Agent Observability BlogOptimizing AI ROI from DevOps and IT Operations: The rising need for AI/LLM observability
BlogOptimizing AI ROI from DevOps and IT Operations: The rising need for AI/LLM observability




