
Adoption of artificial intelligence (AI) is increasingly imperative for any organization that hopes to remain competitive in the future. However, the benefits of AI are not as straightforward as they might first appear.
While off-the-shelf models assist many organizations in initiating their journeys with generative AI (GenAI), scaling AI for enterprise use presents formidable challenges. It requires specialized talent, a new technology stack for managing and deploying models, an ample budget for rising compute costs, and end-to-end security. Many organizations haven’t even considered which use cases will bring them the biggest return on AI investment.
This blog post explores how AI observability enables organizations to predict and control costs, performance, and data reliability. It also shows how data observability relates to business outcomes as organizations embrace generative AI.
Challenges of deploying AI applications in the enterprise
There are several reasons for organizations to consider AI observability as they adopt AI.
Unpredictable costs. Many organizations face significant challenges in pursuing their cloud migration initiatives, which often accompany or precede AI initiatives. Insufficient consideration of total lifecycle costs during the strategic planning phase is a critical issue that forces some organizations that initially pioneer AI to retreat from the cloud due to the pressures of unforeseen costs. Worse, the costs associated with GenAI aren’t straightforward, are often multi-layered, and can be five times higher than traditional cloud services.
Service reliability. GenAI represents a radical shift from command-based interaction models and graphic user interfaces, which have dominated computing for the past 50 years. While GenAI tools have catalyzed more conversational and natural interactions between humans and machines, service reliability is an issue. GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues. Failure to provide timely and accurate answers erodes user trust, hinders adoption, and harms retention. Research by VC firm Sequoia indicates that the use of large language model (LLM) applications lags behind traditional consumer applications, with only 14% of users active daily.
Service quality. The quality and accuracy of information are crucial. However, correct answers might not be immediately apparent. LLMs are prone to “hallucinations” that exacerbate human bias and struggle to produce highly personalized outputs. AI hallucination is a phenomenon where an LLM perceives patterns that are nonexistent or imperceptible to human observers, creating outputs that are nonsensical or altogether inaccurate.
Consequently, AI model drift and hallucinations emerge as primary concerns. For example, a Stanford University and UC Berkeley team noted in a research study that ChatGPT behavior deteriorates over time. The team found that the behavior of the same LLM service devolved in a relatively short time, highlighting the need for continuous observability of LLM quality.
Retrieval-augmented generation emerges as the standard architecture for LLM-based applications
Given that LLMs can generate factually incorrect or nonsensical responses, retrieval-augmented generation (RAG) has emerged as an industry standard for building GenAI applications. RAG augments user prompts with relevant data retrieved from outside the LLM. Augmenting LLM input in this way reduces apparent knowledge gaps in the training data and limits AI hallucinations.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Retrieved data is then submitted to the LLM along with the prompt to provide complete context for the LLM to create its response.
Using the example of a chatbot, once the user submits a natural language prompt, RAG summarizes that prompt using semantic data. The converted data is transmitted to a search platform that searches for relevant data related to the query. Related data is sorted based on a relevance score—for example, semantic distances (a quantitative measure of the relatedness between two or more data points). The most relevant data is submitted to the LLM along with the prompt. The LLM then synthesizes the retrieved data with the augmented prompt and its internal training data to create a response that can be sent back to the user.
While this approach significantly improves the response quality of GenAI applications, it also introduces new challenges. Data dependencies and framework intricacies require observing the lifecycle of an AI-powered application end to end, from infrastructure and model performance to semantic caches and workflow orchestration.
Dynatrace provides end-to-end observability of AI applications
As AI systems grow in complexity, a holistic approach to the observability of AI-powered applications becomes even more crucial. Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications.

Dynatrace AI observability allows Dynatrace to observe the complete AI stack of modern applications, from foundational models and vector database metrics to orchestration frameworks covering modern RAG architectures, providing you with visibility into the entire lifecycle of modern applications across various layers:
- Infrastructure: Utilization, saturation, and errors
- Models: Accuracy, precision/recall, and explainability
- Semantic caches and vector databases: Volume and distribution
- Orchestration: Performance, versions, and degradation
- Application health: Availability, latency, and reliability
Observe AI infrastructure and the environmental impact of machine learning
Though the cost of training LLMs and operating GenAI applications is significant, it’s not the sole factor companies should consider in their AI strategies. Development and demand for AI tools come with a growing concern about their environmental cost. Building LLMs consumes vast amounts of electricity and generates substantial heat. Researchers estimate it took 1,287 megawatt hours to create ChatGPT, releasing 552 tons of CO2. This is equivalent to driving 123 gas-powered cars for a whole year. But energy consumption isn’t limited to training models—their usage contributes significantly more. For example, generating an image requires as much power as fully charging your smartphone.
Estimates show that NVIDIA, a semiconductor manufacturer, could release 1.5 million AI server units annually by 2027, consuming 75.4+ terawatt hours yearly—more than the annual consumption of some countries.
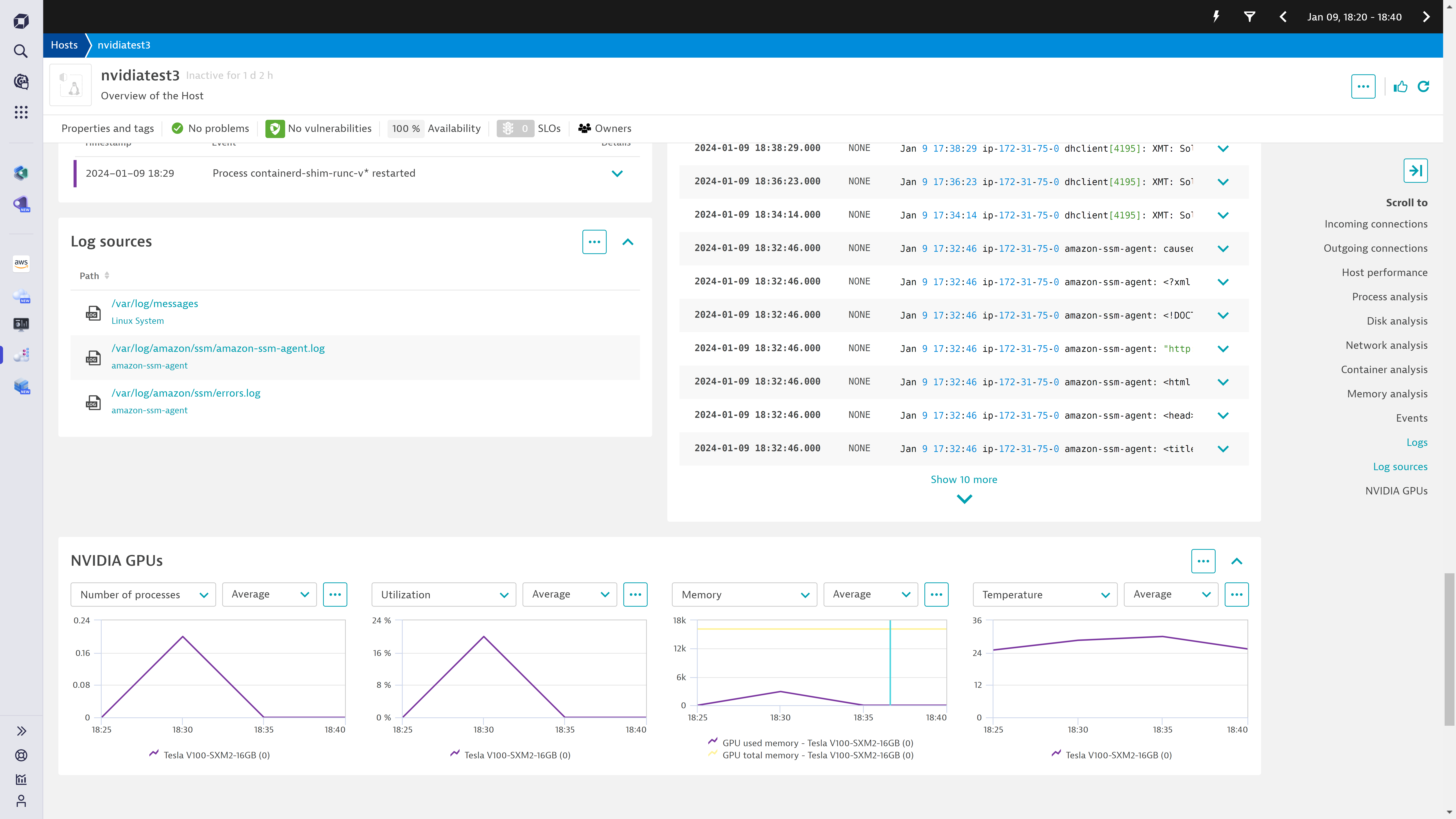
To help companies build more sustainable products, Dynatrace seamlessly integrates with AI infrastructure such as Amazon Elastic Inference, Google Tensor Processing Unit, and NVIDIA GPU, enabling monitoring of infrastructure data, including temperature, memory utilization, and process usage to ultimately support carbon-reduction carbon-reduction initiatives.
Observing AI models
Running AI models at scale can be resource-intensive. Model observability provides visibility into resource consumption and operation costs, aiding in optimization and ensuring the most efficient use of available resources.
Integrations with cloud services and custom models such as OpenAI, Amazon Translate, Amazon Textract, Azure Computer Vision, and Azure Custom Vision provide a robust framework for model monitoring. For production models, this provides observability of service-level agreement (SLA) performance metrics, such as token consumption, latency, availability, response time, and error count.
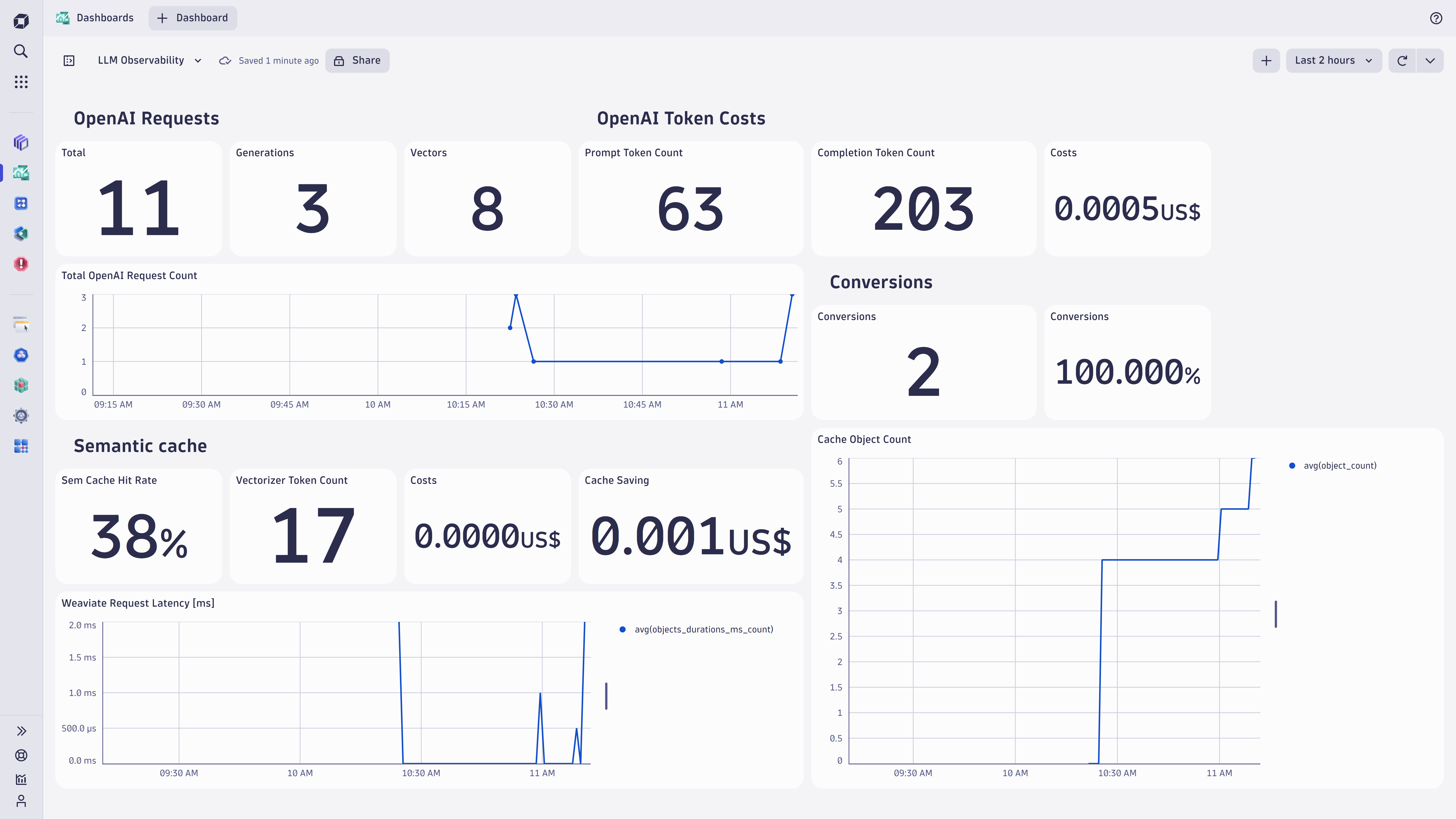
Beyond SLAs, the emergence of machine learning technical debt poses an additional challenge for model observability. Managing regressions and model drift is crucial when deploying and monitoring machine learning models in operation, especially as new data comes in.
To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data. For model explainability, they can implement custom regression tests, providing indicators of model reputation and behavior over time.
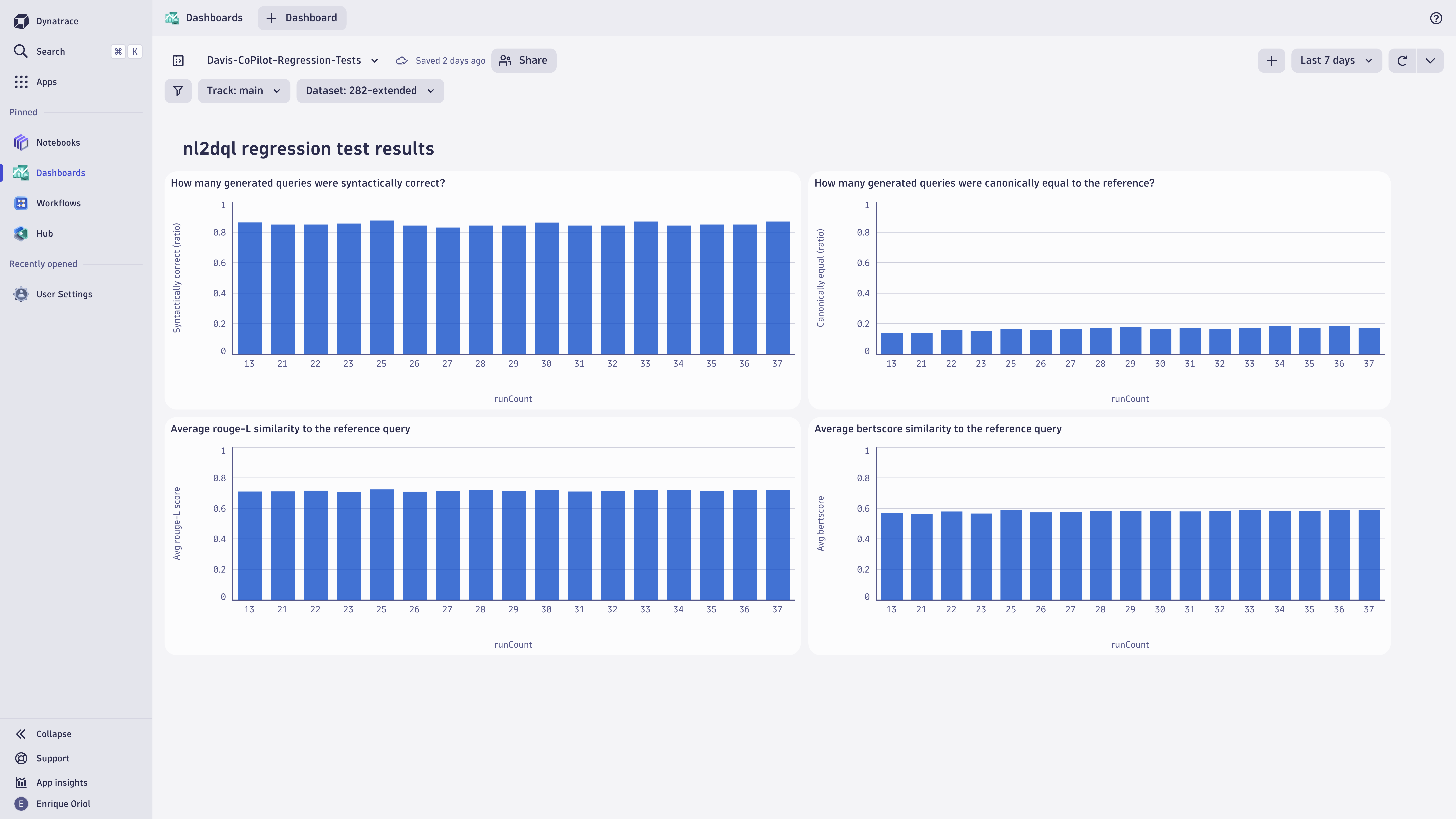
Observing semantic caches and vector databases
The RAG framework has proven to be a cost-effective and easy-to-implement approach to enhancing the performance of LLM-powered apps by feeding LLMs with contextually relevant information, eliminating the need to constantly retrain and update models while mitigating the risk of hallucination.
However, RAG is not perfect and raises various challenges, particularly concerning the use of vector databases and semantic caches. To address the challenge of these retrieval and generation aspects, Dynatrace provides monitoring capabilities to semantic caches and vector databases such as Milvus, Weaviate, and Chroma.
This empowers customers to capture the effectiveness of retrieval-augmented generation systems, giving them the tools to optimize prompt engineering, search and retrieval, and overall resource utilization.
Observing orchestration frameworks
The knowledge utilized by LLMs and other models is limited to the data on which these models are trained. Building AI applications that can integrate private data or data introduced after a model’s training cutoff date requires augmenting the model with the specific information it needs using prompt engineering and retrieval-augmented generation.
Orchestration frameworks such as LangChain provide application developers with several components designed to help build RAG applications—first by providing a pipeline for ingesting data from external data sources and indexing it.
Second, they support the actual RAG chain, taking user queries at runtime and retrieving relevant data from the index, then passing that to the model.
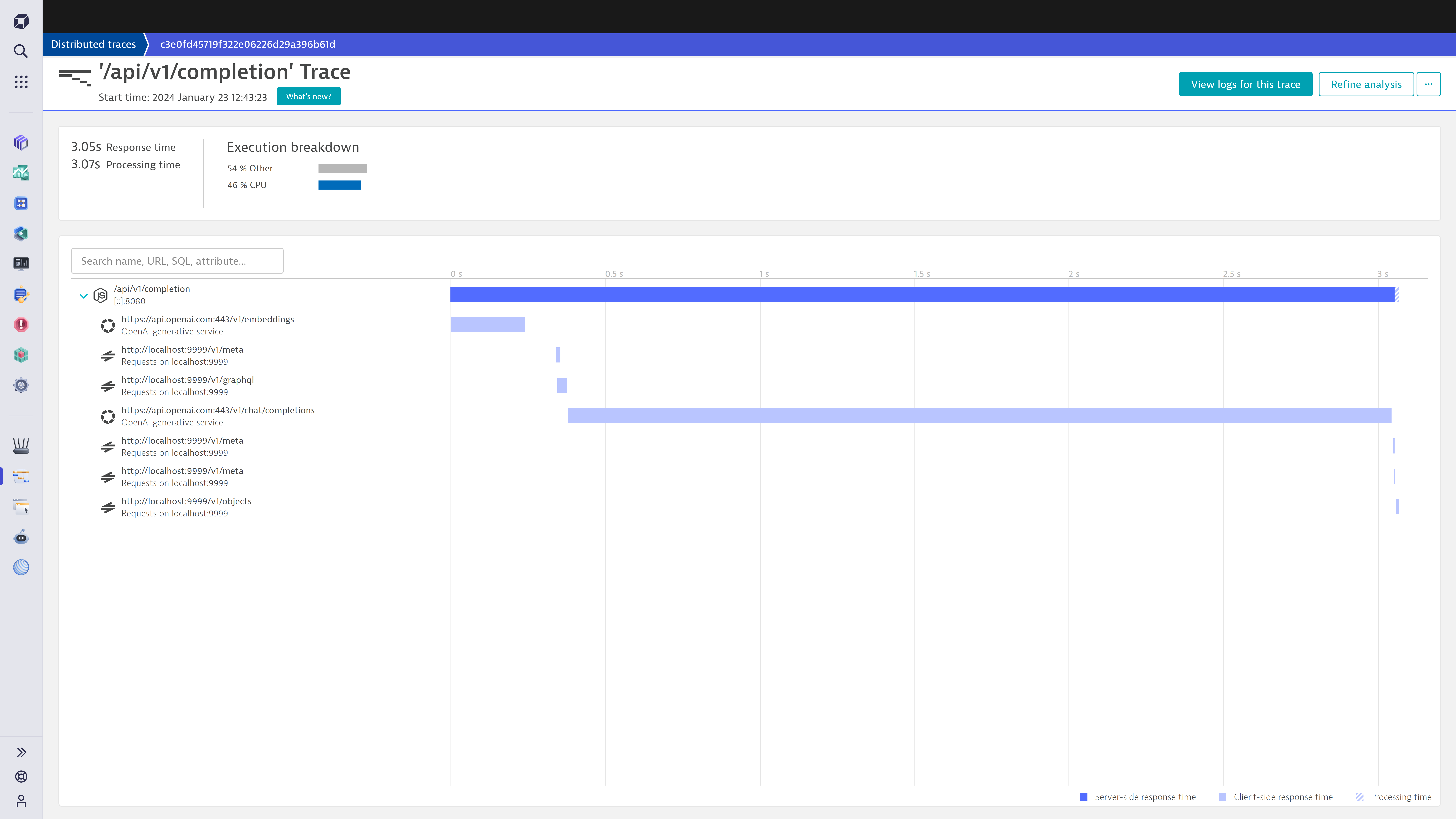
Integrating with frameworks such as LangChain makes the tracing of distributed requests seamless. This capability enables early detection of emerging system issues, thereby preventing performance degradation before outages occur. Organizations benefit from detailed workflow analysis, resource allocation insights, and execution insights, end to end from prompt to response.
Dynatrace provides insights into costs, prompt and completion sampling, error tracking, and performance metrics using the logs, metrics, and traces of each specific LangChain task, as shown below.
AI observability helps you get the most out of AI for business success
The required initial investment in GenAI is high, and organizations often only see a return on investment (ROI) through increased efficiency and reduced costs. However, organizations must consider which use cases will bring them the biggest ROI. Finding a balance between complexity and impact must be a priority for organizations that adopt AI strategies.
Organizations need to stay on top of AI developments, and AI adoption is not a one-time event for which they can plan. AI adoption requires an ongoing mindset shift where organizations examine and observe all processes of building and enhancing services beyond the technical stack of their AI applications. Dynatrace helps to optimize customer experiences end to end, tying AI cost to business cases and sustainability, enabling organizations to deliver reliable, new AI-backed services with the help of predictive orchestrations. Dynatrace Real User Monitoring (RUM) capabilities identify performance bottlenecks and root causes automatically, fulfilling the demand for a holistic approach that includes an understanding of intricate system designs and nuanced hidden costs.
Our commitment to customer success is exemplified by how we utilize AI observability for our own benefit, delivering successful AI-based applications at Dynatrace. For instance, based on token counts, we derived a development strategy that not only enhanced reliability but also paved the way for investigating prompt engineering possibilities, as well as deriving measures to better design RAG pipelines to reduce response times. Observing cache hit rates also allowed us to detect model drift in the embedding computations of the AzureOpenAI endpoints, helping Microsoft identify and resolve a bug.
The future of generative AI observability
From facilitating growth to increasing efficiency and reducing costs, GenAI adoption represents a paradigm shift in the industry—a trend consistent with the historical pattern where core technological innovations disrupt prevailing business paradigms. Throughout business history, the advent of pivotal technologies has consistently led to disruptive shifts. Enterprises that fail to adapt to these innovations face extinction. Despite 93% of companies acknowledging the risks of integrating GenAI, the risk mitigation gap hinders companies from progressing at their desired pace.
With GenAI set to become a $1.3 trillion market by 2032, Dynatrace fills this critical risk mitigation gap with AI observability today. Our technologies are evolving quickly from the feedback we receive from clients and partners, helping us to assist them in building successful GenAI applications at scale. Dynatrace offers an expansive suite of nearly 700 integrations to provide unparalleled insights into every facet of your AI stack. From monitoring infrastructure and models to dissecting service chains, Dynatrace provides a comprehensive observability and security solution.
To leverage these integrations and embark on a journey toward optimized AI performance, explore the AI/ML Observability documentation for seamless onboarding. Join us in redefining the standards of AI service quality and reliability.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum