
Load Testing in the Era of Web 2.0
Chapter: Performance Engineering

We begin this section with a kind parable for young or inexperienced load testers. When I was learning how to design and execute load tests, an experienced load tester taught me the gospel of test-execution effectiveness: If something doesn't go wrong with some part of the application and/or the infrastructure during the test, then there is most likely something wrong with the test itself. Our testing techniques may change as our applications become more sophisticated, but we should remain ever mindful of this rule.
Testing Modern Web Applications
Your company has spent months building a new application and it is ready for testing. You are assigned to lead the testing team. You have enabled enhanced logging and monitoring for all parts of the application stack, the network, the outside perspective, and your third-party providers. Time is scheduled, a conference bridge is opened, and final approval is given. You generate the load and cross your fingers.
Success! The test goes off without a hitch! You are given final approval for release, but you have a nagging worry. Was the test valid? When your site reaches peak load, can you be sure that the customer experience will remain unaffected? More specifically, was the test configured properly to stress the application and all of your third-party content in a way that accurately models customer use? (See Figure 3.27.)
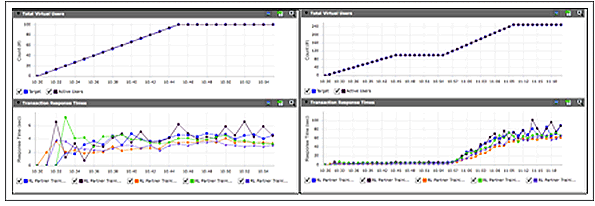
It is worth noting that the easiest aspect of load testing is the execution. The harder, and far more important, part is designing tests that validate the test criteria. And to do this, we must be able to answer these five essential questions:
- What and why are we testing?
- How do we determine the correct load?
- How do we best simulate customer behavior?
- Who will be involved in the test executions?
- What's next?
Regardless of technology, designing load tests that answer these questions has generated far more meaningful results than any other approach I've tried.
What and Why Are We Testing?
The goal of a load test is to learn something about the complex interactivity and behavior of the application environment under load. But what will be tested will vary greatly. The team could be
- Ensuring that a new datacenter for load-balancing traffic geographically performs as well as the existing datacenter under a full system load in case it has to absorb all traffic in a failure situation
- Validating that the entire end-to-end application can withstand projected holiday-season traffic volumes based on the previous year's analytics
- Gathering data on the integration of a new tag-aggregation and -management system to support the traffic volumes of the post-holiday sale period
Each of these statements seems to only declare what will be tested. But looking closely allows a load-test team to quickly understand the importance of each test scenario. Taking each of the scenarios above one step further shows the why of the testing:
- If we don't validate the ability of a single datacenter to handle our entire load during peak or, at a bare minimum, normal traffic conditions, our company's revenue could be at risk if such a failover ever occurs.
- Last year, we were lucky to survive the load we saw on peak days. The 10% increase that business and marketing projects for this year could cause some serious capacity issues on our two to three busiest days, which are also the highest online-revenue days of the year.
- Last year our development team deployed third-party content to the site without fully testing the potential effects this could have, and we encountered performance degradations on peak days. To prevent this for the current year, we have selected a tag-management solution to help us centralize management and automate deployment of third-party content. We have recently read in industry articles that at the absolute highest volumes, customers using this solution last year saw unusual behavior on their busiest days. We need to validate that the solution is able to handle our projected traffic before it happens in real life.
Each scenario starts with a supposition, theory, or something that the team believes to be true. The goal of the load-test process is to put the system into a simulated scenario that has the potential to prove one or more of the performance beliefs incorrect while providing the data necessary to resolve the issue. Not having the right data after a test may require another round of testing; finding an issue and discovering that the instrumentation in place for the testing was the culprit causes the same issue. But turning on too much logging, and leaving it on by accident after testing is complete, might have a negative effect on application performance.
How Do We Determine the Correct Load?
With the team knowing what they are testing and why, the next question is how much load to use. When talking to customers, we initially get statements that describe the required load in very vague terms, like these:
- We need to support 55,000 users.
- Our average hourly usage is 200,000 transactions.
- Our system can currently support 2,000 distinct user sessions.
- Customers average 5 minutes per session on our site
Statements like these do not give us enough information to design a complete load-test traffic profile. Taking the example of a test that requires 55,000 users, we can build out an approach that puts some meat on the bones of the customer's request.
While this statement makes it seem like the testing team will need to spin up 55,000 virtual users to successfully load-test the system, we don't have quite enough information to make that decision yet. Load-test teams should always ask a few more questions to make sure that everyone is on the same page before testing begins.
Where did this number come from? If the application already exists and all that the load test does is test some changes or revisions, then there must be analytics data to support the 55,000-user number. If the application is brand-new but there are similar applications in existence, then the marketing team should be able to extrapolate potential figures from public information—and then share that data with you! If it is a new creation entirely, then some estimating may be required, based on type of launch, marketing, and business expectations.
When does this system see 55,000 users? In an hour? A day? A minute? This question is a follow-up to the first question, as it helps the load-test team determines the time period the application should be tested for. If the application sees 55,000 users over an hour, then a much lower level of virtual users is required for testing than if the application supports 55,000 users every second of every peak hour.
Were these users concurrent? If the site requires you to test a total of 55,000 users over the span of an hour, then you may need far fewer virtual users than if the requirements state that 55,000 users simultaneously or concurrently perform actions on the system over the span of an hour.
Is this a flash crowd or increasing volume? Some applications can encounter flash crowds (Figure 3.24), where usage leaps from very low to well beyond maximum in an incredibly short period of time, usually due to some marketing event—holiday sale, ticket on-sale, Super Bowl advertising, etc. The event may last only 15 minutes, but a failure during this time will cost the company millions in lost revenue, wasted marketing spend, and public brand damage.
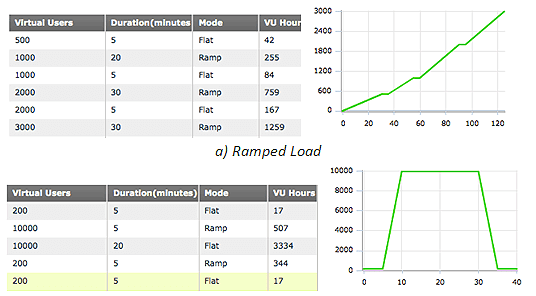
With a few targeted questions, the picture of the customer's requested 55,000-user load test becomes much more clear. Taking this approach provides a map for the load test—the volume of traffic is the destination, but it is critical for everyone involved in the load test to understand how they will get there.
How Do We Best Simulate Customer Behavior?
Getting the amount of load right is important. Creating a load that emulates what customers do when they're on the site is just as important as determining how many customers need to be tested. Not all visitors perform the same actions, view the same search results, or buy the same product when they are interacting with the application.
The testing team may test every dark nook and cranny when performing internal testing prior to release. But as the application creeps closer to public release, the test plan needs to become more customer-focused, highlighting the performance of two types of key customer paths:
- High-value paths in terms of volume. These are the paths that see the most customer traffic and have the highest exposure to the outside world.
- High-value paths in terms of revenue. These are the customer paths that may not get a high percentage of the total traffic, but that are most important for the company's bottom line.
Using the filter of highest-value transactions, regardless of volume or revenue, most application-testing plans can be boiled down to a relatively small number of key business paths. For a retail application, some the typical paths are as follows:
- Homepage
- Search results to product page
- Browse through random category and product pages
- Add to cart
- Checkout and abandon (guest and registered customer)
- Checkout and pay (when applicable and appropriate)
Additional paths may be required for each individual retailer, but for the majority of testing, these paths cover a substantial percentage of customer traffic and touch on key technical and revenue components that affect the entire business, such as in the example seen in Figure 3.25.
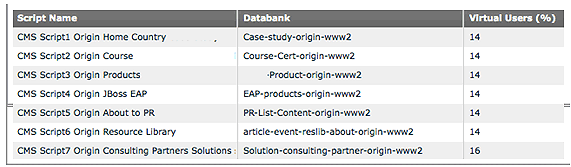
This set of paths touches on the majority of third-party tools: search and catalog indexing systems; advertising; analytics tags; external shopping-cart systems; payment-processing vendors; and, of course, CDNs. For other types of firms—banking, insurance, media, B2B services, etc.—the revenue and traffic filters can also be applied to design a load test to most closely represent the vast majority of customer traffic. Understanding the transactions that are of most value to the organization helps shape the way that the load you designed interacts with the application being tested.
Who Will Be Involved in the Test Executions?
The group that performs the load test is the most critical in the process. When you are running traditional load tests (inside the firewall, with internal application infrastructure and network components), assembling the team is fairly straightforward—all appropriate systems and network teams, with some involvement from vendor teams to support specific hardware or software components if needed.
When the focus moves to outside-in or web load testing, the number of people begins to grow. Now testing teams have to include not just people from the internal application and network teams, but also from connectivity providers, hosting providers, third-party services, and CDNs. This often makes load tests more chaotic, as the amount of data collected begins to balloon in size, with no centralized platform to collect, process, and report on telemetry. While this customer-focused approach delivers new insights that helps companies avoid potential performance disasters, some critical results may not be immediately found in the large and wildly varied datasets collected during a load test.
With organizations integrating a new generation of application-management tools into their systems alongside the outside-in load-testing tools, the number of people on a load-test call may, for the first time in many years, start to go down. These tools integrate metrics across a number of application layers in to a single interface, highlighting specific network, application, and code information more quickly. These systems can also integrate data from external monitoring systems, such as web performance monitoring services, to further correlate performance issues that appear during load testing to specific points on the end-to-end path of an application.
The key is to identify all of the systems and services your application touches before a load test begins. Even with these new systems, people still need to know that a load test is occurring. If a third-party service begins demonstrating performance issues or an internal system needs to be more deeply analyzed due to a problem identified during the test, key members of the affected teams will need to be brought in to help troubleshoot and resolve the issues.
What's Next?
No matter the approach your team takes, the goal of load testing is to simulate the visitor traffic that is expected under peak conditions as accurately as possible. If there is a problem with the load or with the business-process distribution used during the test, the results could create a misleading picture of how the application and its various components will behave under load.
The rule with load testing is assume nothing! Just because the responsible team states that the application, web-server farm, load balancer, database, or firewall should behave in a certain way during the test, doesn't mean it will behave that way. It is better to find out that there is a gap between assumption and reality under intense and complex load scenarios before customers find out for you.
And if a test is successful, dig a little deeper. You and your team can be truly secure about a load test only when everyone can answer this question: Was the test actually successful, or did it just validate that one (or more!) of the test configuration parameters was incorrect?
Resources
Steve Bennett. House MD: Solving Complex IT Issues Using Differential Diagnosis
Table of Contents
Application Performance Concepts
Memory Management
How Java Garbage Collection Works
The Impact of Garbage Collection on application performance
Reducing Garbage Collection Pause time
Making Garbage Collection faster
Not all JVMS are created equal
Analyzing the Performance impact of Memory Utilization and Garbage Collection
The different kinds of Java memory leaks and how to analyze them
High Memory utilization and their root causes
Classloader-releated Memory Issues
Performance Engineering
Virtualization and Cloud Performance
Try it free
