
As organizations embrace automation instead of time-consuming, manual processes, many turn to artificial intelligence for IT operations, or AIOps.
AIOps uses machine learning and artificial intelligence, or AI, to cut through the noise in IT operations — specifically incident management. But what is AIOps, exactly? Are all AI and AIOps approaches the same? And how can it support your organization?
What is AIOps?
According to Gartner, “AIOps combines big data and machine learning to automate IT operations processes, including event correlation, anomaly detection and causality determination.” A modern approach to AIOps serves the full software delivery lifecycle. It addresses the volume, velocity, and variety of data in complex multicloud environments with advanced AI techniques to provide precise answers and intelligent automation.
Most AIOps tools ingest pre-aggregated data from various technologies across the IT management landscape — including disparate observability tools — and conclude what is relevant for an analyst to focus on. But there are a few caveats to consider. We’ll discuss the current AIOps landscape and an alternative approach that truly integrates AI into the DevOps process.
How does AIOps work?
AIOps is distinct from other IT data collection solutions that process and make inferences from data. While most large organizations already have comprehensive data collection tools, they don’t provide the whole picture. Modern collection and monitoring tools often generate too much data for a human to parse and use, which is where AIOps can help.
AIOps uses AI methods to ingest, sort, and make inferences from data. A full AIOps pipeline often includes several algorithmic processes with different jobs:
- One handles data ingestion and sorting.
- One recognizes patterns.
- One makes inferences from the patterns.
When combined, they significantly reduce alert fatigue and the data-sorting burden.
Equally important is AIOps’ ability to communicate information directly to the right teams. Additionally, AIOps often accompanies an increased focus on incident response automation. AI for IT operations aims to increase efficiency and observability throughout an organization. The building blocks of AIOps — machine learning algorithms and other AI processes — all help to accomplish that goal.
Two approaches to AIOps
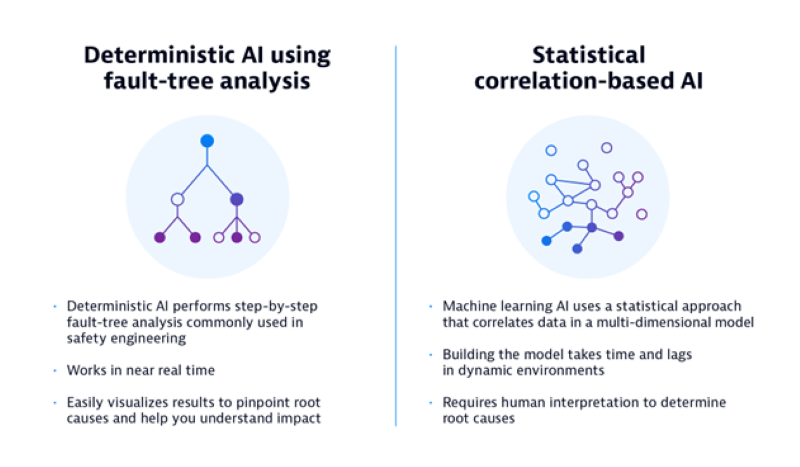
There are two overarching AIOps approaches: traditional correlation-based AIOps and modern deterministic AIOps. This modern approach is also referred to as causal AI and uses fault-tree analysis.
Traditional AIOps
Traditional AIOps approaches are designed to reduce alerts and use machine learning models to deliver correlation-focused dashboards. These systems are often difficult to scale because the underlying machine-learning engine doesn’t provide continuous, real-time insight into an issue’s precise root cause. They require extensive training, and analysts must spend valuable time manually tuning the model and filtering out false positives.
Modern AIOps using deterministic, causal AI
A modern AIOps solution, on the other hand, is built for dynamic clouds and software delivery lifecycle automation. It combines full stack observability with a deterministic, or causal, AI engine that can yield precise, continuous, and actionable insights in real-time. This contrasts stochastic (or randomly determined) AIOps approaches that use probability models to infer the state of systems. Only deterministic, causal AIOps technology enables fully automated cloud operations across the entire enterprise development lifecycle.
Is AIOps necessary?
Modern applications are built from hundreds or thousands of interdependent microservices distributed across multiple clouds, creating incredibly complex software environments. This complexity makes it difficult for IT pros to understand the state of these systems, especially when something goes wrong. While AIOps is often presented as a means to reduce the noise of countless alerts, it can do much more. A full-featured, deterministic AIOps solution fosters faster, higher-quality innovation; increased IT staff efficiency; and vastly improved business outcomes.
Humans can’t manually review and analyze the massive amount of data that a modern observability solution processes automatically. Typically, any approach that adds more visualizations, dashboards, and slice-and-dice query tools is more of an unwieldy bandage than a solution to the problem. Disparate interfaces still require manual intervention and analysis. In this way, traditional AIOps solutions have essentially become event monitoring tools.
Modern IT strives for more capable automation, and AI is critical to achieving this goal. Continuous integration and continuous delivery processes provide smart pipelines for rolling out new features and services. Orchestration platforms, such as Kubernetes, are relieving operations teams from error-prone and mundane tasks related to keeping services up and running. This automation enables developers and operations teams to focus on innovation, rather than endless administrative tasks.
The challenges of traditional AIOps
Despite the AIOps benefits, such as improved time management and event prioritization, increased business innovation, enhanced automation, and accelerated digital transformation, correlation-based AIOps solutions have limitations.
AIOps based on correlation does not scale
With a machine learning approach, traditional AIOps solutions must collect a substantial amount of data before they can create a data set — i.e., training data — from which the algorithm can learn. Administrators can reinforce learning through rating and similar means, but it can take weeks or even months until this AI is calibrated to deliver insights into business-critical applications in production.
This approach is hardly “set and forget.” Modern applications undergo frequent changes, and their deployments are highly volatile, which implies an ever-changing data set. Traditional AIOps can’t scale up with frequent changes that occur within complex distributed applications.
Lost and rebuilt context
The second challenge with traditional AIOps centers on the data processing cycle. Traditional AIOps solutions are built for vendor-agnostic data ingestion. This means data sources typically come from disparate infrastructure monitoring tools and older-generation application performance monitoring solutions.
These tool sets first acquire one or more raw data types — such as metrics, logs, traces, events, and code-level details — at different levels of granularity. Then, they process them before finally creating alerts based on a predetermined rule — for example, a threshold, learned baseline, or certain log pattern.
Typically, machine learning can access only the aggregated events, which often exclude additional details. Now, the AI learns similar reoccurring clusters of incoming events for later classification of new events. With that data, it builds and rebuilds context — time- and metadata-based correlation — but has no evidence of actual dependencies. Integrations allow for the system to process more data, such as metrics. But those add more data sets without solving the cause-and-effect problem with certainty.
What are the key capabilities of a modern AIOps solution?
An AIOps solution should be comprehensive to save teams time and manual effort. Here are key capabilities an AIOps solution should provide.
Unified platform. A comprehensive, modern approach to AIOps is a unified platform that encompasses observability, AI, and analytics. This all-in-one approach addresses the complexity of identifying problems in systems, analyzing their context and broader business impact, and automating a response. The best solutions provide real-time, continuous insights into the state of systems and services that are critical to business operations. That way, businesses can focus on innovation rather than responding to inevitable problems with complex systems.
Topology mapping and distributed tracing. A truly modern AIOps solution should include topology-mapping capabilities, perform distributed tracing, and have strong integration capabilities. With strong topology mapping, users immediately gain a comprehensive visualization of all infrastructure, process, and service dependencies. A similarly important visibility requirement is distributed tracing, which should provide DevOps with fine-grained topology and telemetry data and metadata.
Full observability of Kubernetes environments. Kubernetes has abstracted resource management to such a high degree that the platform can be adopted across industries for a wide range of applications. But that adaptability brings complexity. AIOps is an increasingly essential part of DevOps in Kubernetes environments where reliability, scalability, and flexibility are key considerations.
Comprehensive integrations. Finally, integration is critical for the success of any modern IT solution. In addition to supporting fine-grained observability, AIOps solutions should support integration with existing security systems. Most often, the problem with existing security systems is not that they fail to work properly. Rather, it’s that they cannot be used properly due to alert fatigue and false-positive frequency.
Deterministic AI is key to AIOps success
Traditional AIOps is limited in the types of inferences it can make because it depends on metrics, logs, and trace data without a model of how systems’ components are structured. AIOps should instead use deterministic AI to fully map the topology of complex, distributed architectures to reach resolutions significantly faster.
By applying real-world AIOps use cases, businesses can harness the power of advanced analytics, machine learning, and automation to enhance monitoring, detect anomalies, and optimize performance. This transformative approach enables proactive problem resolution, improves efficiency, and empowers IT teams to deliver exceptional user experiences. Learn how AIOps can revolutionize your business by driving efficiency, reliability, and proactive decision-making.
In part two, “Applying real-world AIOps use cases to your operation,” discover how to achieve autonomous operations, and explore AIOps use cases, like applying AIOps to multicloud operations, development environments, and secure applications in real-time.
To learn more about how deterministic AI and observability can take your AIOps strategy to the next level, register for our on-demand webinar series, “AIOps with Dynatrace software intelligence” today.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum