
The benefits of AIOps include enhanced automation and accelerated digital transformation. But how can you apply AIOps use cases to address your real-world operations issues?
Artificial intelligence for IT operations, or AIOps, combines big data and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. While the benefits of AIOps are plentiful — including increased automation, improved event prioritization and incident response, and accelerated digital transformation — applying AIOps use cases to an organization’s real-world operations issues can be challenging.
So, before your organization can get the most out of an AIOps platform, it’s critical to understand its potential use cases. By understanding the advantages of deterministic AI, you can choose an AIOps platform that helps you transform faster and achieve autonomous operations.
AIOps use cases
The goal of AIOps is to automate operations across the enterprise. However, as organizations adopt more cloud-native technologies, such as containerized microservices and serverless platforms, operations have become exponentially more complex. This makes developing, operating, and securing modern applications and the environments they run on practically impossible without AI. Thus, modern AIOps solutions encompass observability, AI, and analytics to help teams automate use cases related to cloud operations (CloudOps), software development and operations (DevOps), and securing applications (SecOps).
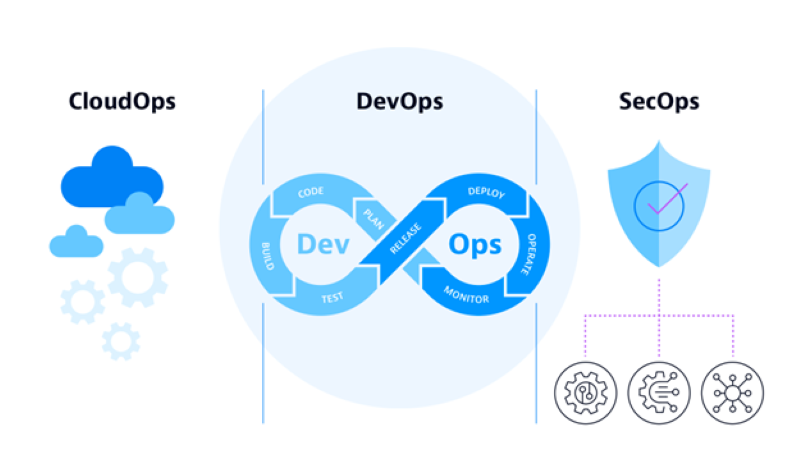
CloudOps: Applying AIOps to multicloud operations
CloudOps includes processes such as incident management and event management. AIOps reduces the time needed to resolve an incident by automating key steps in the incident response process. This includes identifying an issue’s root cause and automatically responding to those causes.
Logs are a valuable source of information, but that information is often difficult to identify. AIOps can identify events that require some response, but likely would not be detected and acted upon manually.
DevOps: Applying AIOps to development environments
DevOps can benefit from AIOps with support for more capable build-and-deploy pipelines. Teams can address testing and deployment issues automatically, which streamlines continuous integration and continuous delivery pipelines and increases innovation throughput. This increased automation, resilience, and efficiency helps DevOps teams speed up software delivery and accelerate the feedback loop — ultimately allowing them to innovate faster and more confidently.
SecOps: Applying AIOps to secure applications in real time
Organizations are constantly improving, revising, and updating applications with new features. But before that new code can be deployed, it needs to be tested and reviewed from a security perspective. SecOps is responsible for ensuring applications are secure. AIOps supports that with the ability to assess applications during development, delivery, and deployment.
Anomalous behavior in a newly deployed application can easily escape human detection, but AIOps systems complement SecOps engineers by identifying and reporting on potentially exploitable vulnerabilities.
The four stages of data processing
For a deeper understanding of how to effectively apply AIOps use cases, it helps to understand how it processes data to improve your operations. There are four stages of data processing:
- Collect raw data
- Aggregate it for alerts
- Analyze the data
- Execute an action plan
Teams often follow this approach to achieving AIOps because of its apparent convenience:
- Start with a second-generation application performance monitoring solution, which covers data collection and aggregation and prepares data for analysis.
- Introduce a machine-learning-based AIOps platform as a logical evolution in IT management tooling. This second solution picks up at data collection, aggregation, and analysis, preparing it for execution.
This approach introduces another layer that helps to manage a lot of events from different solutions and vendors, with machine learning assistance to reduce the alert flood and focus on the critical issues.
However, the price for that convenience is the potential loss of context when switching tools, which the machine learning needs to achieve automated root-cause analysis and, eventually, fully automated CloudOps.
Think of traditional AIOps solutions as an aid to the status quo. It can help you catch up, better manage incidents, and be more reactive. But this approach breaks down at the scale and complexity of today’s modern multicloud environments.
Ultimately, AIOps should encompass all four stages of data processing in a single product and UI, including the execution phase, by enabling greater automation throughout your IT organization. This includes CloudOps, with a focus on incident management, DevOps for improved application building and testing, and SecOps to ensure applications are secured. Only an approach that encompasses the entire data processing chain using deterministic AI and continuous automation can keep pace with the volume, velocity, and complexity of distributed microservices architectures.
Achieving autonomous operations
The great promise of AIOps is to automate IT operations — or achieve autonomous operations. However, organizations can only achieve autonomous operations when the flow through the four stages can happen without human intervention. While the collection, aggregation, and execution stages of the data processing chain have been solved to some extent, the toughest part is the analysis stage. This involves identifying the root cause of an issue and then, based on the insight, choosing the best remediation action.
Cracking the analysis stage requires a different approach to AI.
Deterministic AI
An alternative to the machine learning approach is deterministic AI, also known as fault-tree analysis.
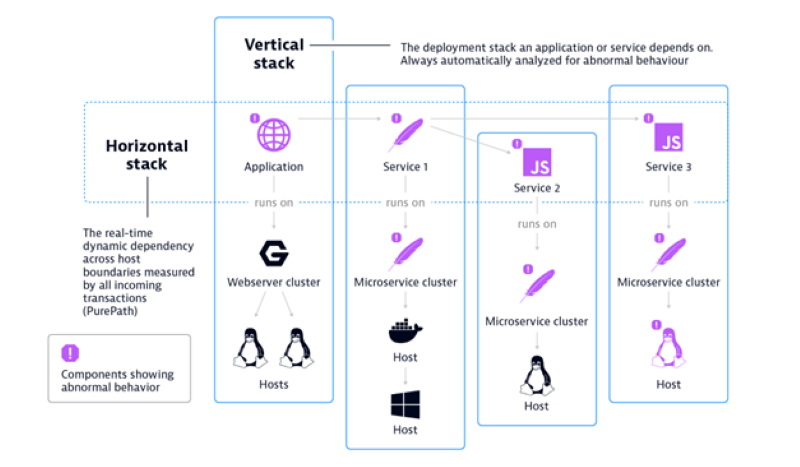
Let’s say, for example, an application is experiencing a slowdown in receiving its search requests. The deviating metric is response time. It triggers the fault-tree analysis, so you begin analyzing with the monitored entity to which the metric belongs — the application. This is now the starting node in the tree.
Next, you investigate all the app’s dependencies. It may have third-party calls, such as content delivery networks, or more complex requests to a back end or microservice-based application. The AI then analyzes and investigates all those dependent nodes for anomalies. If a node is cleared, it forms a leaf. Nodes showing anomalies will be further investigated down their dependencies.
From there, you look at the web server the application is communicating with, further to the front-end tier and search service. Then, you see search requests are slower than usual on all nodes.
Now, it’s not that simple to just follow the dependencies in one direction. Let’s assume the operating system hosting the search service is also running another process independently that consumes significant CPU. This causes a shortage and slows down the search service. From the search service, you follow the dependency to the process and to the host, and then back up to other processes running on that host.
This process continues until the system identifies a root cause. In this case, it’s a chatty neighbor. On the other end of the tree, you can assess the impact. For example, how many users have been affected by that problem? A huge advantage of this approach is speed. It works without having to identify training data, then training and honing.
The significance of topology information for AIOps use cases
Because it follows a logical fault tree, deterministic AI requires a topology model of your data center or application deployment. Otherwise, you would never be able to walk through the tree like this and find the root cause.
A traditional AIOps platform ingests data and metadata to offer correlational data and dashboards to conduct root-cause analysis. On the other hand, a deterministic AI approach based on fault-tree analysis uses topology data and builds an entity model in real time by incorporating observed raw data — including metrics, logs, events, traces, and contextual information, such as user experience data. This entity modeling with contextual data enables deterministic AI to deliver precise and repeatable root-cause identification.
Two types of root cause
There are two different types of root cause: technical and foundational. The earlier example explains how the system identifies a technical root cause. In this case, it’s a CPU spike of another process. The foundational root cause explains what led to that spike — in this case, a deployment.
To achieve automated foundational root-cause analysis, the AI needs to be able to browse through the history or changelog of the monitored entity that has been identified as the technical root cause. Of course, this information must be available to the AI and, therefore, part of the entity.
How AI helps human operators
Like all AI applications, whether in manufacturing, healthcare, finance, or other industries, AIOps is not about reducing the human factor’s importance. Rather, it’s about helping people work faster and smarter. Modern IT operations involve observing networks, cloud resources and applications, endpoint devices, and more. The amount of data generated by the tools used to collect information on the status and behavior of these systems is simply too much to properly manage, even for teams of IT professionals.
AIOps bolsters the abilities of DevOps workers, security professionals, and administrators by providing them with the data filtering and parsing needed to comprehensively observe their systems. Machine-learning-supported tools provide human operators with only the information relevant to the task at hand, leaving out the noise. Alert fatigue and chasing false positives are not only efficiency problems. They’re also discouraging the people who would rather focus on the important work they are trained to do.
Taking AIOps to the next level
With modern multicloud environments, AIOps must evolve to include the full software delivery lifecycle.
The traditional, machine-learning-based approaches — which still rely heavily on human input — give us event monitoring tools that cannot scale up to meet the demands of modern multicloud microservice-based apps.
However, a deterministic, fault-tree approach to AI allows for precise technical and foundational root-cause identification and impact analysis in real time. The result is more complete automation throughout the entire development and delivery pipeline. Therefore, DevOps staff can innovate and create new solutions to human problems, rather than simply keeping the lights on.
To learn what the next generation of AIOps software can bring to your organization and how to apply AIOps use cases, check out our eBook, “Developing an AIOps strategy for cloud observability.”


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum