
Software Delivery
Accelerate digital transformation with simple yet powerful automations driven by observability and security insights.


Automate and orchestrate
critical processes
Leverage our easy-to-use visual workflow creator or automation-as-code workflow capabilities to see:

greater software quality

higher employee satisfaction

fewer deployment failures

lower IT costs




Turn answers into action quickly
and at scale
Leverage observability and security data to drive Workflow Automations use cases.
Incident triage
- Automatically create or update tickets and alert the appropriate teams to spare devs from alert storms and false positives.
- Proactively identify and triage issues with Dynatrace intelligence.

Auto-remediation with a closed loop
- Automatically pinpoint the root cause of incidents and execute remediation workflows through runbook integrations or natively through Dynatrace.
- Verify issue resolution and update tickets seamlessly.

Quality gates
- Stop bad quality code in its tracks with quality gates.
- Ensure code meets your KPIs, SLOs, and security requirements before reaching production, effectively allowing safe, secure, and high-quality releases.
Infrastructure operations
- Employ predictive analysis to optimize infrastructure sizing by evaluating golden signal performance –ensuring satisfied customers.


Create custom workflows with AutomationEngine
Our answer-driven automation technology leverages causal and predictive AI to intelligently power BizDevSecOps workflows throughout the DevOps lifecycle.

Software Delivery resources
 BLOG POSTDevOps automation: We’re only halfway there
BLOG POSTDevOps automation: We’re only halfway there BLOG POST
BLOG POSTTame cloud complexity with answer-driven automation
See how AutomationEngine delivers answers and intelligent automation from data at an enormous scale.
 Blog Post
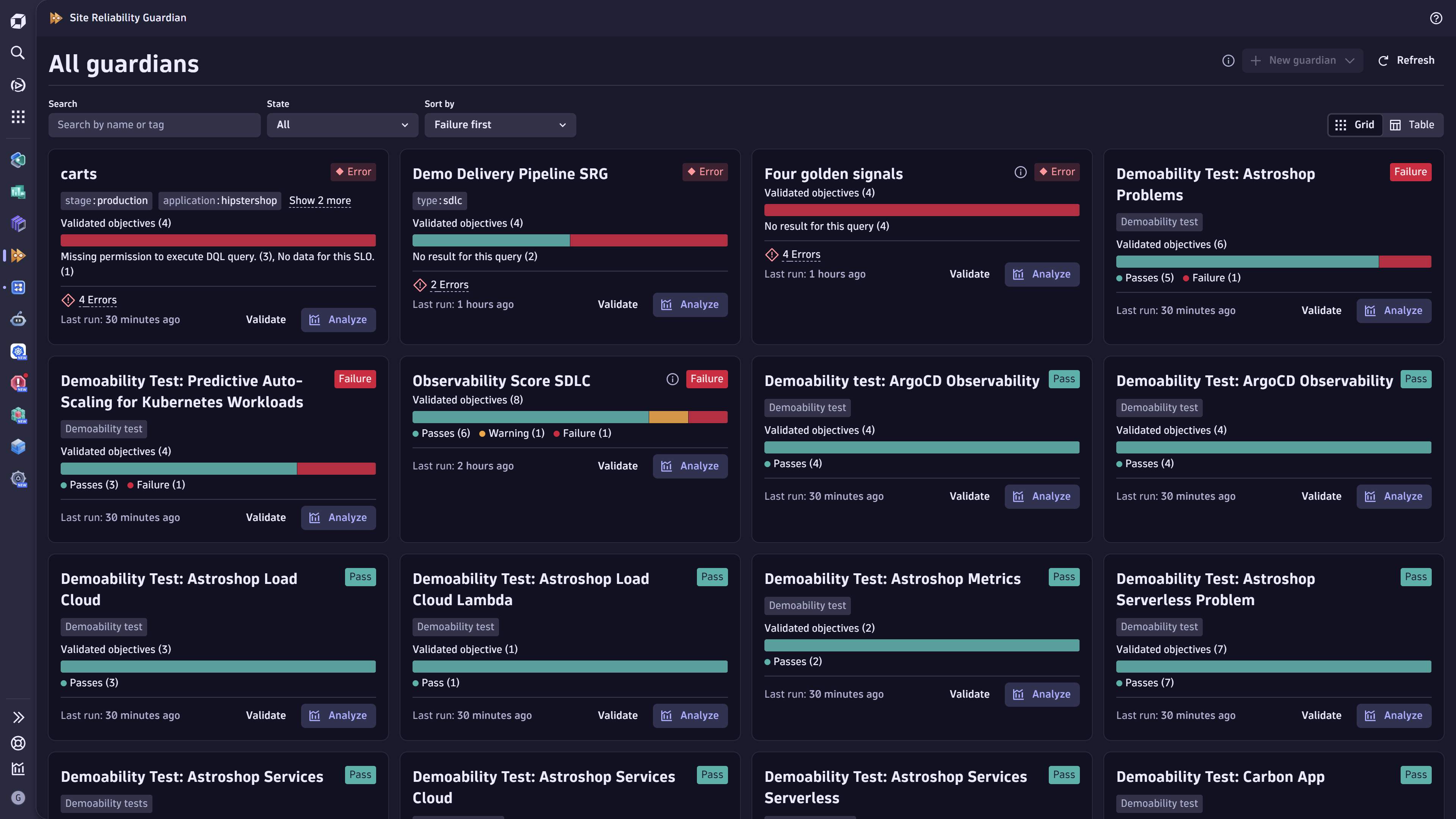
Blog PostAutomated Change Impact Analysis with Site Reliability Guardian
The Dynatrace® Site Reliability Guardian simplifies the adoption of DevOps and SRE best practices to ensure reliable, secure, and high-quality releases.



