
Artificial Intelligence (AI) has the potential to transform industries and foster innovation. However, navigating the path to successful AI deployments can be quite challenging, leaving many organizations to wonder why their AI projects fail.
Why AI projects fail
According to one Gartner report, a staggering 85% of AI projects fail. Several factors contribute to this high failure rate, including poor data quality, lack of relevant data, and insufficient understanding of AI’s capabilities and requirements. These issues underline the importance of robust data management and precise strategic planning for AI projects, including cloud-based models and LLMs.
The data challenge in AI projects
Data is the lifeblood of AI and machine learning (ML) projects. Without robust data, AI models struggle to produce accurate and reliable results. A NewVantage survey from 2024 highlights this issue, with 92.7% of executives identifying data as the most significant barrier to successful AI implementation. Moreover, a Vanson Bourne survey reveals that 99% of AI and ML projects encounter data quality issues. These statistics underscore the critical need for effective data management and monitoring solutions.
The role of data observability
Data observability refers to the ability to monitor and understand the state of data systems. It involves tracking data quality, lineage, and performance across data pipelines.
Organizations can ensure the success of an AI project by monitoring the data’s freshness, volume, distribution, schema, and lineage. Dynatrace offers comprehensive data observability features designed to significantly enhance the success of AI projects, for example:
- Data freshness monitoring. Monitoring data freshness helps to ensure that your data-driven decisions are based on the most current information. When making decisions, relying on the freshest and most relevant information available is crucial.
- Volume monitoring. By monitoring data volume, you can receive alerts about unexpected changes in volume, which can signal potential issues.
- Distribution monitoring. This feature helps identify anomalies, patterns, and outliers in your data, enabling you to detect any irregularities.
- Schema monitoring. This feature detects and flags unanticipated changes in data structures so you can stay informed about any unexpected adjustments.
- Lineage tracking. This feature offers a clear view of the origins and impacts of data, which is essential for troubleshooting and optimizing data flows. Understanding the origin and impact of data both upstream and downstream, also known as data lineage, provides valuable context for comprehending the data’s journey and reliability.
AI Observability: Ensuring model performance and reliability
However, we can’t just stop at data observability. As already mentioned, data isn’t the sole reason why AI projects fail. Insufficient understanding of AI’s capabilities and requirements is also part of it.
AI observability involves monitoring and understanding AI models and systems to ensure they perform as expected in real-world applications. It includes:
- Performance monitoring. Tracking metrics like accuracy, precision, recall, and token consumption.
- Explainability. Understanding how models make decisions to ensure transparency and interpretability.
- Drift detection. Identifying shifts in model performance that indicate issues with accuracy or relevance.
The following diagram shows how AI Observability can detect and resolve degradation in an AI model’s performance:
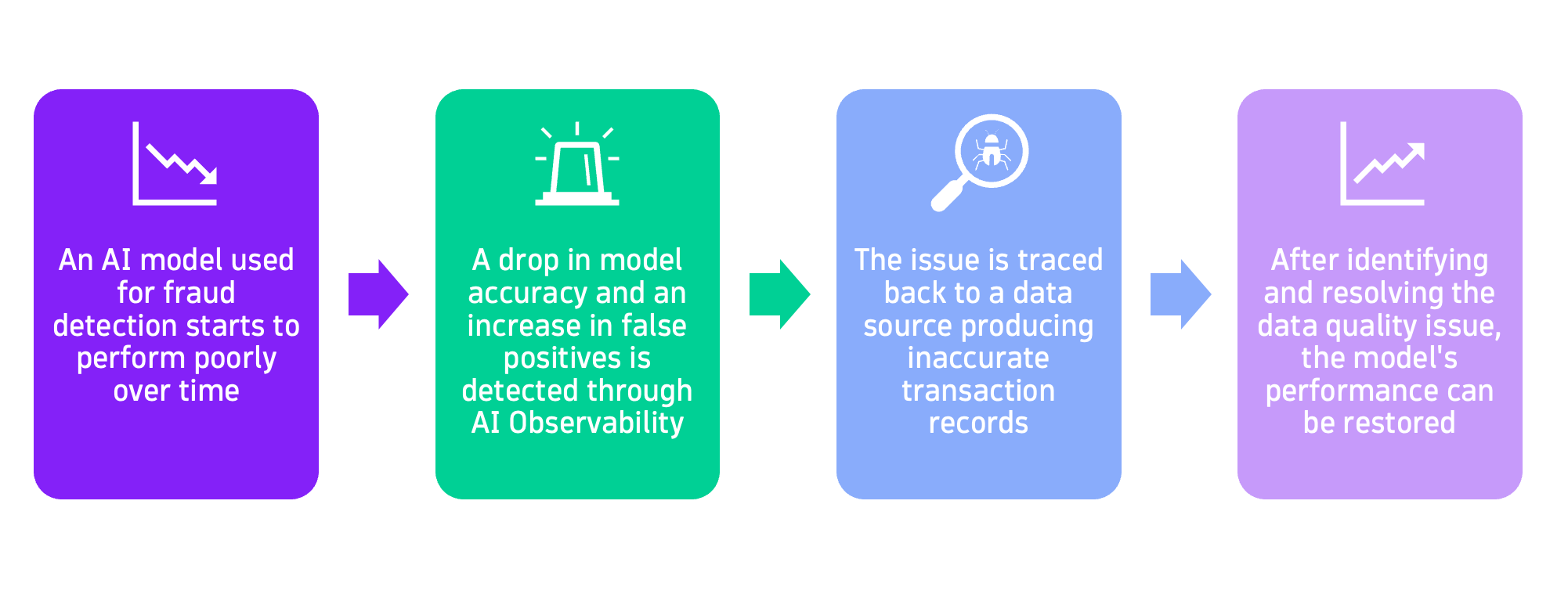
Comprehensive monitoring with data and AI observability
Data and AI observability work together to provide a holistic view of the system. Data observability concentrates on the pipeline and infrastructure, while AI observability delves into the model’s performance and results.
Feedback mechanisms
Effective AI observability relies on feedback loops, which rely on data observability. Identifying data drift, for instance, necessitates a profound comprehension of the data pipeline and its lineage.
Swift issue resolution
Discrepancies in AI performance are often rooted in problems within the data pipeline. Data observability aids in tracking these issues to their source, enabling the swift identification and resolution of problems affecting AI systems.
Compliance and governance assurance
Ensuring compliance with regulations and governance standards is crucial. Data observability ensures data management aligns with industry standards, while AI observability ensures that models adhere to ethical guidelines and regulations.
Ensuring AI excellence: How Dynatrace enhances model reliability
Dynatrace equips organizations with the necessary tools for data and AI observability, helping build sustainable AI applications. By providing comprehensive monitoring and understanding of data systems and AI models, Dynatrace ensures that AI projects are based on high-quality data and that AI models perform reliably and transparently in real-world applications.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum