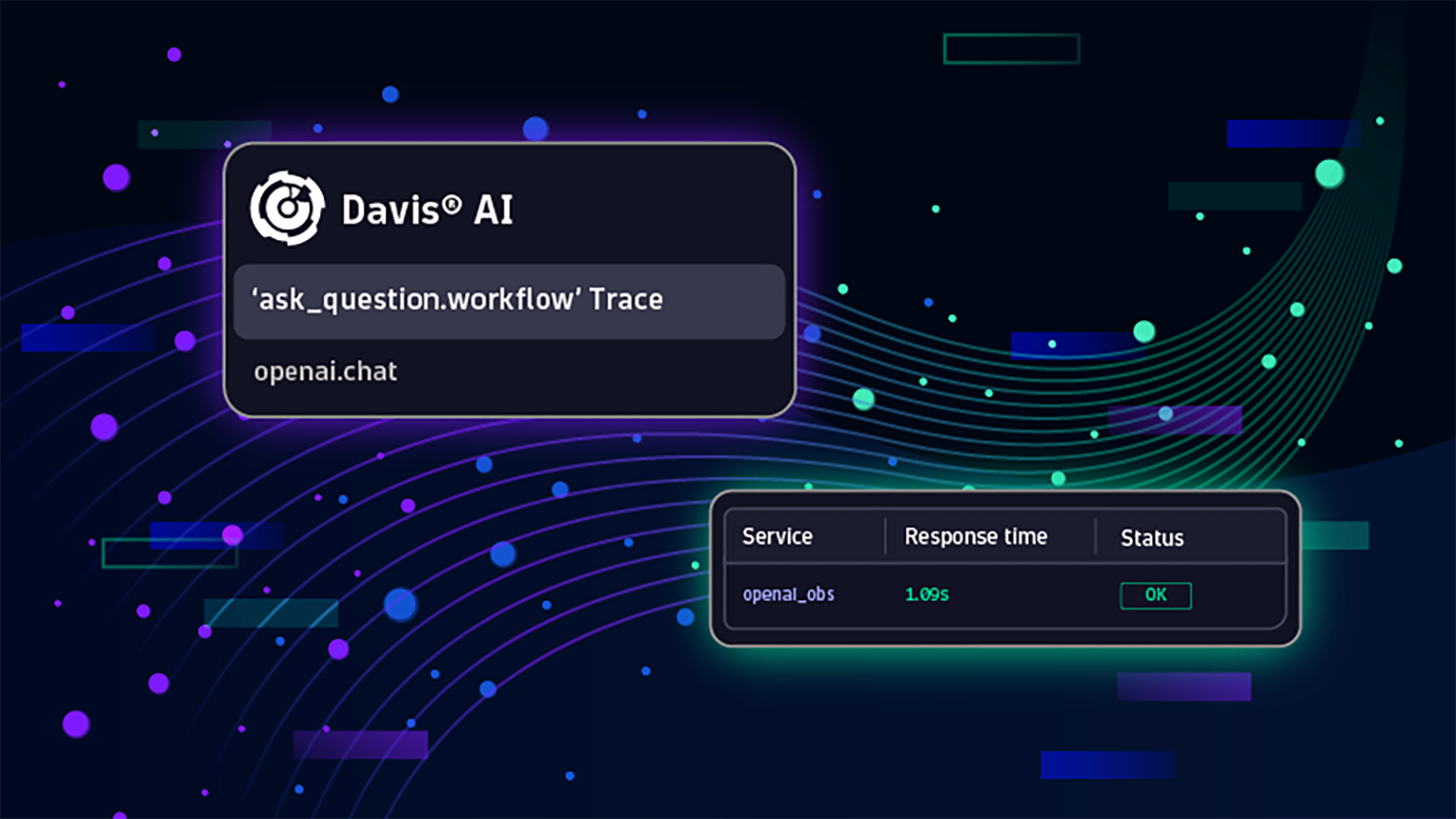
Dynatrace monitors OpenAI for reliable services.
Dynatrace tracks OpenAI/GPT requests, spotting issues in service behavior, aiding in pinpointing slowdowns as a platform feature for years, enduring customer demands.
Read more
Gain insights about vector database resource utilization and cache behavior
TechnologyVector databases, exemplified by Milvus, play a crucial role as semantic caches within contemporary Large Language Model (LLM) service frameworks.
Semantic caches are instrumental in mitigating latency for familiar and frequently accessed user prompts, concurrently optimizing the overall expenditure associated with cloud-based pre-trained model services.
Vigilant monitoring of cache efficiency and memory utilization is imperative for optimal resource allocation, while the cache's adaptability to dynamic contexts serves as a metric for its ability to accurately respond to evolving conversation dynamics. Furthermore, considerations of cache warm-up times contribute to expediting the availability of cached information. In the realm of vector databases, the performance of queries and indexing speed emerges as pivotal indicators directly influencing the system's efficacy in handling similarity searches.
Key factors such as scalability, accuracy of vector representations, and storage efficiency assume critical roles in proficiently managing expanding datasets. Additionally, the performance metrics related to updates, deletions, and query throughput further impact the overall effectiveness of these systems in delivering real-time and accurate responses in natural language processing and similarity search applications.
Striking an optimal balance across these Key Performance Indicators (KPIs) ensures that both semantic LLM caches and vector databases, like Milvus, achieve peak performance across diverse use cases.
To summarize, the overarching goal of vector databases, exemplified by Milvus, is to address performance-related challenges, enhance operational efficiency, and contribute to a more seamless and responsive experience in various natural language processing applications.
The most common Milvus deployment is to run the vector database cache within a Kubernetes workload. Dynatrace automatically collects Prometheus metrics from any pods that are annotated with a metrics.dynatrace.com/scrape property set to true in the pod definition. See below a Milvus Kubernetes deployment specification that automatically exposes Milvus metrics to your Dynatrace environment:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: milvus
spec:
replicas: 1
selector:
matchLabels:
app: milvus
template:
metadata:
labels:
app: milvus
annotations:
metrics.dynatrace.com/scrape: "true"
metrics.dynatrace.com/port: "9091"
metrics.dynatrace.com/path: "/metrics"
spec:
containers:
- name: milvus
image: milvusdb/milvus:latest # Use the appropriate Milvus version
command: ["milvus"]
args: ["run", "standalone"]
ports:
- containerPort: 19530
- containerPort: 9091
resources:
limits:
memory: "2Gi"
requests:
memory: "1Gi"
volumeMounts:
- name: milvus-data
mountPath: /var/lib/milvus
volumes:
- name: milvus-data
persistentVolumeClaim:
claimName: milvus-pvc
This functionality applies to all pods across your entire Kubernetes cluster, regardless of whether the pod is running in a namespace that matches the Dynakube's namespace selector.
Milvus exposes Prometheus-compatible metrics for monitoring at port 9091 under the path /metrics. A standard Prometheus setup can be used to visualize metrics on various dashboards in your Dynatrace environment.
Milvus metrics are then used to measure request latencies, import speed, time spent on vector vs object storage, memory usage, application usage, and more.
Beside other measurements, Milvus exposes following metrics that allow users to observe the health and performance of their vectorized index.
You can use Dynatrace to display, analyze and alert on many different Milvus telemetry metrics that can be categorized into the following three main areas:
• Milvus Performance Metrics • System Performance Metrics: Metrics relating to CPU/GPU usage, network traffic, and disk read speed. • Hardware Storage Metrics: Metrics relating to data size, data files, and storage capacity.
Milvus Performance Metrics
Milvus System Performance Metrics -GPU Utilization: GPU utilization ratio (%).
-Network IO: Network IO read/write speed (GB/s).
Milvus Hardware storage metrics -Data Size: Total amount (GB) of data stored in Milvus. Total File: Number of data files currently stored in Milvus.