
Understanding Application Performance in The Cloud
Chapter: Virtualization and Cloud Performance

While proponents believe that the cloud solves all problems, skeptics see nothing beyond large-scale virtualization with all its inherent compromises. Which is correct and what are we to think about the desirability of cloud implementations?
It's true that clouds are typically, though not necessarily, implemented as virtualized systems, this isn't an argument for or against a cloud-based solution. Similarly, clouds make little sense for very small environments, but this is no reason small applications can't take advantage of an existing cloud. What matters most is that one can provision new VMs in the cloud without making explicit hardware assignments. It's all done with templates and handled by cloud management.
From an operations perspective this is a huge cost- and time-saver, and it makes it feasible to schedule load tests during off-peak hours while ensuring priority for production VMs. At the rather large scale typical for cloud computing, this can significantly reduce hardware and operations.
The Dark Side of Clouds: Changing Layers of Complexity
However, the key cloud advantages of self-service, automatic provisioning, and rapid elasticity must be bought at the price of increased complexity at the application level. Each newly provisioned instance can have a hidden impact on the performance of already-running applications—an impact that may be visible only when we look at the underlying shared infrastructure.
Cloud features such as automatic provisioning and workload management allow us to ignore the relationship between VMs and assigned underlying hardware, but our applications must still run on the actual hardware. So while we may be blissfully ignorant of these assignments, when things go wrong we need to be able to track down the problem.
For example, Application A might impact Application B today, yet tomorrow it might steal CPU time from Application C! How are we to tell? The inherent dynamism of clouds presents significant challenges when it comes to monitoring and application performance management.
Things aren't much better for application owners, who often have no access to the hypervisor layer, usually managed by a separate group, making it nearly impossible to do proper troubleshooting and application tuning.
What's needed is visibility; a means to monitor applications, the VM, and the hypervisor layer at the same time. It's the only way we can trace cause and effect when physical hardware is shared by two running applications. With such an integrated application-monitoring solution, we are able to gather application-level metrics such as response time, load patterns, and resource usage—the information required to ensure application performance and achieve optimal utilization.
Monitoring cloud applications, though not fundamentally different, is more complex because of the added layer of indirection. But APM also gives us the means to run performant applications cost-effectively, which takes us to the next section of our chapter.
Making Cloud Applications Performant and Cost Effective
With clouds, we're able to automate the process of dynamic resource allocation based on changing application demands. At the same time, a cloud, whether public or private, cannot make our applications run any faster. In fact, no transaction will execute more quickly in a cloud. Therefore, the wonderful flexibility we gain from cloud computing must be carefully balanced against the inherent need to be ever more aware of transactional efficiency.
The process of performance tuning remains much the same, with the addition of the metrics just discussed. But there is yet another layer of complexity added by the use of third-party services over which one has no control. For example, most cloud vendors provide database services. Like everything else, these services impact transactional performance and must be monitored.
Similarly, as we add VMs to an application, which is simpler and more flexible than changing resource allocations, we do not want to over-provision. For example, adding a huge VM instance when we need 5% more power is overkill (huge in the sense that it requires a lot of CPU and memory resources). Instead, increasing available hardware in small increments helps to maintain the advantages of flexibility.
The use of smaller, less power full VM instances has two logical consequences:
- The number of instances per tier tends to increase, resulting in a very large number of tiers overall.
- Elastic scaling can become necessary for each tier.
At the same time, clouds are designed to accommodate massive horizontal scaling, which means that we're likely to have a greater number of tiers than with an equivalent data center deployment, and with a greater number of nodes. As you might guess, all of this adds to the complexity of the scaling logic, making it more difficult to find performance issues and optimize applications. This is a task that most monitoring tools and scaling mechanisms were not designed to deal with!
As difficult as this sounds, realizing the cost advantages of the cloud means that we must leverage this elastic scalability. To achieve this and maintain the desired single-transaction performance, we need to rethink the way we design and monitor our applications.
Cloud-deployed applications must be inherently scalable, which means:
- Avoiding all synchronization and state transfers between transactions. This limits sharing and requires a tradeoff in terms of memory and caching. For distributed data, we must use inherently-scalable technologies, which might disallow a particular SQL solution that we are used to.
- Optimizing the critical path so that each tier remains as independent as possible. Essentially, everything that is response time-critical should avoid extra tiers. The best-case scenario is a single tier in such cases.
- Using queues between tiers to aid scaling. Queues make it possible to measure the load on a tier, the queue depth, which makes scaling the consuming tier very easy.
But to achieve the full cost-effectiveness promised by cloud computing, a well-designed application must leverage elasticity as well as scalability. This requires a level of application monitoring to collect data on response time and resource usage, and to measure algorithmic scaling load.
That brings us to the major difference between public and private clouds: cost-effectiveness and elastic scaling.
Public and Private Clouds: Siblings with Different Performance Goals
Before we go on to discuss application monitoring in the cloud, we need to distinguish between public and private clouds. This has little to do with technology and much to do with visibility, goals, and ownership.
In traditional enterprise computing environments, there are two conflicting goals:
- Maximizing utilization, while minimizing hardware
- Optimizing application performance
Virtualized and cloud environments are no different in this respect.
Private clouds have the advantage of being run by the same organization responsible for application performance and IT operations. We're able to enforce application performance management across all layers, which then enables us to optimize for both goals.
In the public cloud the underlying virtualization is opaque. We can neither manage nor optimize it according to our needs or wishes. We must adopt a black-box approach and optimize with a single goal of fulfilling response-time requirements while maintaining scalability. As if by magic, we're no longer faced with conflicting goals, because it's up to the cloud vendor to optimize resource utilization; it's not our concern!
At the same time, we're no longer faced by the limitations of finite resources. In a private cloud, once our application performance goals are met, we continue to optimize to reduce resource usage. In a public cloud, available hardware is of no concern.
Obviously, we're still driven to reduce costs, but this is calculated on the basis of instance time (not CPU usage), disk accesses, network traffic, and database size. Furthermore, your ultimate cost-saving strategy will depend upon your selected vendor's cost structure. As such, it's more important to choose a vendor based on the particular performance characteristics of your cloud application, than it is to worry about a vendor's hardware.
This calls for an example. We have a transaction that makes 10 disk accesses for each search operation, and each access incurs some very low charge. By cutting the number of accesses in half, the search transaction may not run any faster, but think about the potential operational savings for a transaction that might be executed a million times!
Furthermore, we're faced with a situation in which the vendor pricing structure can change at any time. To optimize expenses in response, we must monitor performance preemptively by capturing data from the right measures.
Before we start on performance analysis, I'll summarize how and why we monitor cloud applications.
Effective Monitoring: Public Cloud–Based Applications
Cloud environments are designed to be dynamic and large. So to maintain consistency and reliability we use an automated monitoring system, and every new application must be registered with this system upon startup. This can be implemented from within the application framework or through a JVM agent–based monitoring approach. Either way, we must also ensure that any newly deployed instances are monitored automatically.
Cost-effective cloud applications will leverage elastic scaling, which for any given tier requires knowledge of the load and response time on that tier. If increased load negatively impacts response time, we know to scale up the specific tier. Combining this technique with a baselining approach, we can automatically scale up predictively based on historical load patterns (Figure 7.7).
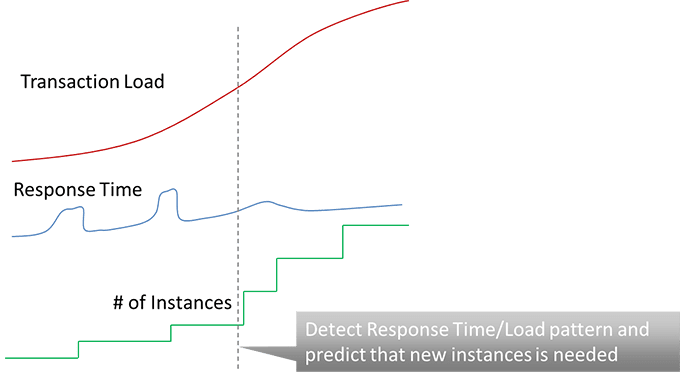
We still need to understand the impact of resource utilization and hardware latencies on our application. In a private cloud we need to maintain the correlation from application to hardware at any given point to resolve issues. In a public cloud we do not need this, but still need to know the impact of the cloud infrastructure in our application to make informed deployment and scaling decisions.
By the nature of the cloud, instances are temporary. So our automatic monitoring system must know when to retire instances, while saving any information we might need later for performance analysis. Since the application will have a longer life cycle than the instances it uses, we can aggregate measures such as response time and underlying virtualization metrics from an application point of view for long-term trending.
For example, it's more important when looking over historical data to pinpoint a month-old problem as CPU ready time due to over-utilization than it is to know exactly which instance may have caused the issue. Most likely, the instance in question has long since been retired.
We must also distinguish between data needed for monitoring (longer-term) and that needed for analysis (shorter-term), so that we can store it differently. For instance, a trending analysis might use 10-second or 1-minute interval aggregates; but for detailed diagnostics we'll need the same information, but for every single transaction.
Of course, the real value of a good monitoring setup becomes abundantly clear when resolving any issues, especially during performance analysis.
Table of Contents
Application Performance Concepts
Memory Management
How Java Garbage Collection Works
The Impact of Garbage Collection on application performance
Reducing Garbage Collection Pause time
Making Garbage Collection faster
Not all JVMS are created equal
Analyzing the Performance impact of Memory Utilization and Garbage Collection
The different kinds of Java memory leaks and how to analyze them
High Memory utilization and their root causes
Classloader-releated Memory Issues
Performance Engineering
Virtualization and Cloud Performance
Try it free
