
Dynatrace enables Site Reliability Engineering (SRE) teams to proactively ensure the highest service quality levels. Davis, the Dynatrace AI engine, identifies potential contributors to SLO violations in real time, before thresholds are breached. Dynatrace pinpoints the root causes of problems and their impact on SLOs.
In modern service landscapes, Service-level-objectives (SLOs) are the chosen methodology of Site Reliability Engineering (SRE) teams for ensuring the high quality of delivery of their digital services. There is however a major challenge faced by many SRE teams: how to catch relevant degradations early, before a long-term SLO shows an unhealthy state.
Are you still “reacting to bad numbers”?
SLOs with an observation period of, for example, one week, are of course not overly affected by short-lived outliers. However, such observation periods come with a disadvantage: incidents can pile up and there is a delay between those incidents and the corresponding health metrics ultimately dropping low enough to trigger a warning.
Teams who are primarily reactive in their approach therefore use SLOs to decide when the state of a system has become so bad that it requires intervention.
Some SRE teams counter this by defining the same SLOs for different observation periods to reduce the reaction times in case of incidents. Many teams use three different levels of observation periods, one for strategic decisions, one for tactical decisions, and one short period for catching incidents. These redundancies can of course create additional efforts and complexity.
Error budgets and the tracking of their burn rates offer a much better approach, however without extensive manual effort, this approach still leaves two questions open:
- How can I detect anomalies early, before they impact your SLOs?
- To facilitate fast remediation, how can I quickly identify the root causes of emerging issues that have massive potential SLO impact
Most monitoring tools offer only a single SLO metric. However, watching a single SLO health metric and error budget drop doesn’t provide much in the way of answers; it only confirms the obvious—that your SLO is unhealthy. In the best case scenario, to answer the above questions, you need experts to conduct manual investigation and interpret the data for you. In the worst case scenario, the nature of today’s dynamic and heterogenous environments renders such manual investigation impossible.
Dynatrace proactively helps Site Reliability Engineers keep their SLOs healthy
Dynatrace Davis, our AI-engine, offers a unique feature that overcomes the fundamental challenge of reacting quickly enough, even within strategic observation periods. Davis notifies you when any of your SLOs are at risk, before any metrics turn red.
This works out-of-the-box because Dynatrace understands how all your application and infrastructure components depend on each other. In this way, Davis can link defined SLOs to those anomalies that present potential negative impact.
Davis AI predicts if future SLO health is at risk
Let’s look at an example where an SLO was defined for the stability of a frontend service that shows a perfect 100% SLO health status:
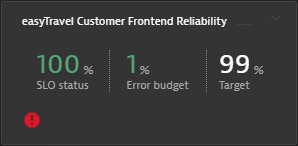
Notice in the above SLO tile that Davis has displayed a critical error indicator to inform the SRE team about an ongoing incident within the service topology that the SLO covers. Even though the SLO still shows perfect 100% health, Davis AI is proactively predicting that the future SLO health is at risk.
Dynatrace AI pinpoints the root causes of SLO-impacting incidents
Further, a single click on this tile displays all active incidents along with the potential negative impact on the future health of the SLO.
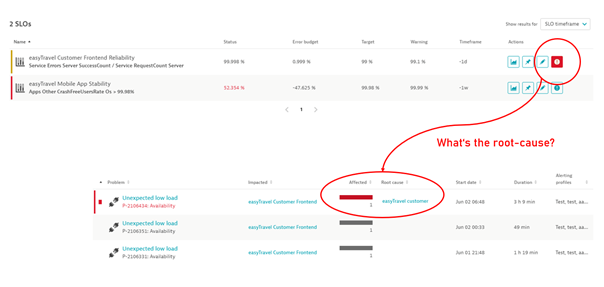
A drill-down from an unhealthy SLO takes you to a filtered feed of detected problems that are the root causes of these incidents. This precise AI-assisted identification of root causes saves valuable time for SRE and DevOps teams during critical service outages, instead of just showing a single, isolated health metric.
Get up and running in under a minute with SLO templates
Service-level-objectives consist of carefully selected Service-level-indicators (SLIs) which provide a quantitative measure of each aspect of the service level. Typically, an SRE team spends a good amount of time selecting the best indictor metrics for their given services, which then leads to well-defined SLOs that reflect the service quality.
The Google Site Reliability Engineering page is a great read for understanding and embracing the idea of defining SLOs for reliable global IT services.
However, getting started with SLOs in Dynatrace is even easier.
SLO templates for the most popular use cases are available out-of-the-box
We offer a collection of best-practice SLO definitions for various use cases beyond the observability domain; simply choose one of the predefined SLO templates that Dynatrace provides out-of-the-box.
For example, you can measure the quality of service of your mobile app offering. Dynatrace offers a mobile crash-free users SLO template that you can use to create a best-practice SLO for measuring the reliability and stability of your mobile apps.
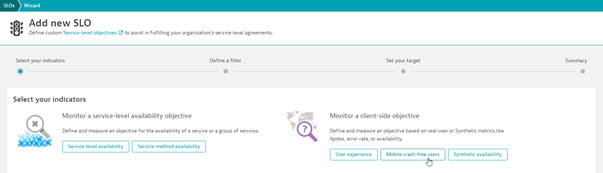
Once you’ve defined your business-critical SLOs, you’re all set. Davis will then automatically analyze your SLOs continuously and provide a truly proactive approach to SLOs. Proactive SLO impact analysis is available with the release of Dynatrace version 1.220. If you’re new to Dynatrace, you can experience the magic yourself by starting a Dynatrace free trial.
Get started with SLOs
Learn more
If you want to learn more about SLIs/SLOs, here are a few resources that we recommend:
- SLO beyond production reporting – automate delivery & operations resilience (by Andreas Grabner)
- SLOs for quality gates in your delivery pipeline (by Andreas Grabner)
- Performance Clinic: Getting Started with SLOs in Dynatrace | Dynatrace
- Wolfgang Heider and Kristof Renders from Dynatrace recently presented a topic at SLOconf 2021, addressing the following questions:
- What are good indicators and who should define them?
- How do I define SLOs in Dynatrace and act upon them?
- Are SLOs just something for production, or are they also for delivery?
You can check out the session recording to find all the details.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum