
Ansible automation has changed the game for IT operations. But the Red Hat Ansible Automation Platform integration with the Dynatrace Software Intelligence Platform takes automated remediation to a whole new level.
Early in my IT career, I worked in IT Ops and DevOps roles, building release deployment solutions for repeatable outcomes. Back then, the concept of automation meant something different. Everything I did was automation. Whether deployment of a new system, a new release, or a rolling patch update, I wanted it done consistently and successfully every time. In some cases, this meant testing my scripted methodology hundreds of times before deploying to production in order to catch every nuance and condition that could affect the result.
Years later, a few configuration management solutions came into play that required heavy amounts of coding, but proved that the industry was moving toward compartmentalized automation solutions.
Red Hat Ansible automation changed the game for IT operations
Then one day, Ansible became the game-changer for home-grown automators. All the conditional checks in my Perl script suddenly became obsolete. These evaluations that I hard-coded into a script were now embedded into the back-end of Ansible’s modular approach. Using Ansible, what once took me hundreds of lines of code now take only a few dozen lines of YAML.
Like many improvements in our lives, changes in automation happen gradually. For example, the old hand-crank cars from the early 1900s gave way to the electric starter, then more recently, to remote starters, which enabled users to pre-heat and cool their vehicles. Now, computer-driven thermostats start the car automatically under certain conditions to maintain a median temperature.
In the same sense, simple IT automation was just the beginning. When Ansible evolved to include a GUI, this allowed for API integration. Now, something other than a human with a big red button could kick off an automated process. This ability empowered other applications to leverage Ansible’s powerful automation through a RESTful API. As a result, humans could pre-define automation routines and allow the machines to trigger them when certain conditions were met.
Enter Dynatrace for automated remediation
The next phase of my amazement involves deep introspection into a monitoring and observability solution called Dynatrace. Because of the quantity of “proper noun solutions” I experienced in my System Administrator career, I wasn’t previously aware of the full spectrum of capabilities in Dynatrace. The market offers plenty of monitoring solutions that can link a specific monitored event with a specific scripted action. As I began working more closely with Dynatrace in my role with the ISV Partner Ecosystem at Red Hat, however, I quickly realized that Dynatrace is much more than a simple monitoring tool.
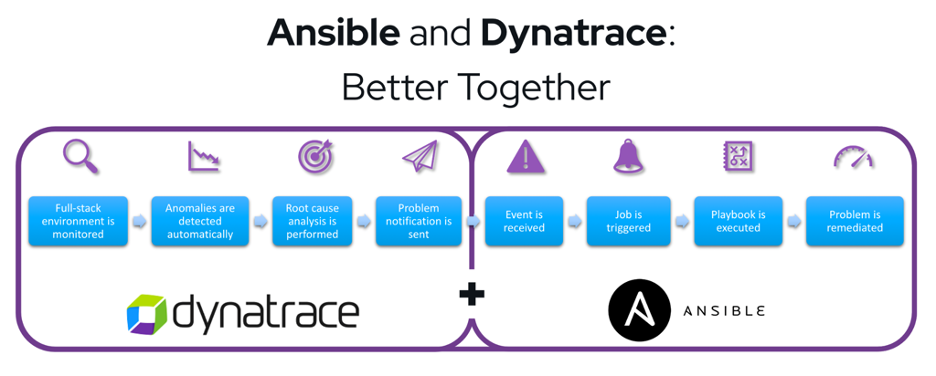
Working collaboratively with Dynatrace over the past few years, we’ve grown an intelligent automation solution that uses the power of the Red Hat Ansible Automation Platform along with deterministic AI from Dynatrace. The result of the Ansible integration with Dynatrace provides a solution capable of self-remediating IT incidents without reactive intervention from IT staff. To begin this prescriptive approach, we perform the initial deployment of infrastructure and applications with Ansible Automation Platform, providing a more consistent and predictable environment. The Ansible Playbooks include a small piece of YAML to interact with the Dynatrace AI, allowing Dynatrace to perform automated remediation when such action is necessary.
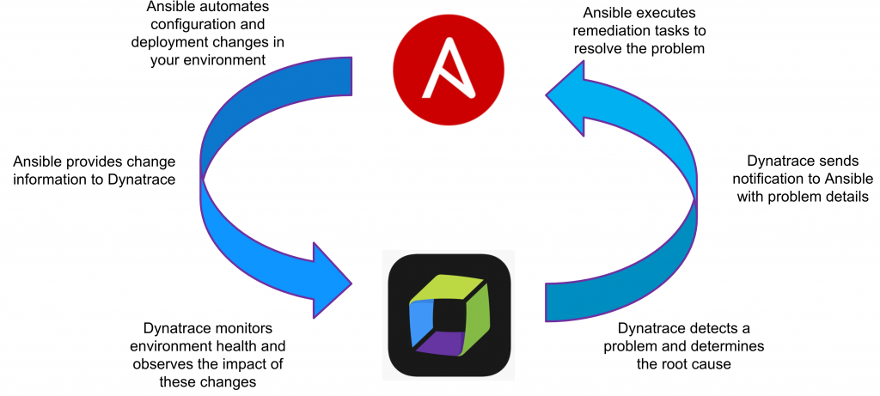
Dynatrace proactively discovers problems before they happen
Because Dynatrace isn’t simply searching for “service is up, service is down” type of events, Dynatrace can actually proactively discover problems in the environment before they happen. Traditional monitoring agents are programmed by a human with a threshold of specific events. For instance:
“If APPSERVER123 sees the word ‘error’ in the log file more than 10 times per minute, trigger a problem.”
“Probe APPSERVER456 once per minute. If it responds with HTTP error code ranging 4xx or 5xx, pull it out of the load balancer pool and tell a System Administrator to manually check it for issues.”
While both examples would discover noteworthy issues, they’re heavily dependent on humans to pre-define what is “bad.” Dynatrace’s deterministic AI evaluates multiple conditions of an application server. Dynatrace can evaluate a system and decide what specific files, services, ports, and events are noteworthy for health reasons. This health check isn’t manually defined by threshold and isn’t solely based on success or failure. Dynatrace monitors relevant aspects of the system and aggregates historical data. By doing so, Dynatrace can detect anomalies in performance and health that don’t necessarily immediately result in a failed message transaction. Simply put, the Dynatrace AI can predict the conditions that will lead to failure, often before the failure even occurs.
Deterministic AI detects patterns to enable automated remediation
Using this deterministic AI approach, Dynatrace takes notice of anomalies and remains aware of the types, times, and severity of anomalies. When it detects an unexpected pattern, Dynatrace can then proactively leverage the Ansible Playbook that deployed the system or service in question, applying a known desired state, quite possibly without ever experiencing an outage. These Ansible automation routines can interact with the load balancer or dependent databases to the application server, providing a calculated rolling remediation that considers aspects of the infrastructure and customer experience, not just whether or not the application is responding.
Once Dynatrace performs the automated remediation action, it doesn’t stop there. When the system is performing in the expected desired state, Dynatrace intentionally monitors attributes of the previous anomaly for the issue to recur. If no further automation steps are necessary and the initial action was a success, the Dynatrace incident record is updated with details from the fix, including variables fed in by the Ansible automation routine. Dynatyrace notifies the IT staff of the problem, the fix, and the fact that no further action is needed. The admin wakes up to good news that “Dynatrace detected and fixed it with Ansible… all while you were sleeping.”
To find out more about this technology and how to apply it intelligently in your environment, contact Dynatrace to discuss your automation needs at Redhat@dynatrace.com.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum