
The Theory Behind Performance
Chapter: Application Performance Concepts

Finally, we must take the plunge into the theoretical foundations of performance management. It's essential to our everyday work to understand some of the immutable laws of application performance. We promise to limit this discussion to the most important and practical considerations.
Performance Modeling Using Queuing Theory
Queuing models are often used to model the characteristics of a software system. Although they present a simplification, they are helpful in understanding the characteristics of software systems.
The basic idea is simple. An application requires resources to fulfill a request, and these resources are available in limited quantity. If a resource is not available, a request must wait for it. The figure below shows a simple queuing model for a single-tier application. The resources include a pool with servlet threads for the database, memory, and the CPU. These are interdependent, so if the thread pool is too small, it would not help if more CPU were available.
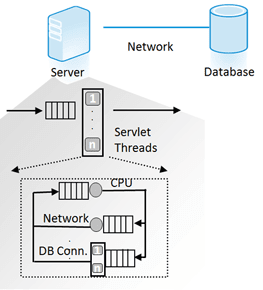
What can we conclude from this? The performance and scalability of our application depend upon the resources available. When there are fewer resources available, the more heavily what is available will be used. This can quickly lead to poor application scaling and ever longer execution times.
While a resource is in use, it's not available to other requests. These limited resources have the potential to become performance bottlenecks, and this is why they become an important focus for monitoring and application scaling. When application response becomes slower, it is almost always due to a lack of resources.
This is why it's so important to keep an eye on the utilization of individual resources and monitor the transactions using them. Once we have constructed such a model, we can detect and eliminate almost all performance and scalability problems. Queuing models are also the basis for two important performance and scalability limits.
Little's Law
Little's Law states that given a queue system in a stable state, the average number of customers, or requests, is equal to the product of their average arrival rate and the average time spent in the system. Put more simply, a system is stable when the number of new requests is not higher than the maximum load that can be processed.
For example, when it takes half a second to process a request, then a maximum of two requests can be processed per second. If, over a longer time period, more than two requests per second are received, the system will become unstable.
This may seem both trivial and logical, but how does it help us in our daily work? First, we can use it to estimate scalability. We know that we have two cores available for an application, meaning 2,000 ms CPU time per second. If a request requires 200 ms, our maximum stable load is ten requests. We can therefore determine very easily the point at which our resources are saturated. This is already a basic way for capacity planning. Although it is oversimplified it helps as a first guess.
Another interesting use case is for verification of a test setup. We can use Little's Law to determine whether test results are valid and not impacted by an overloaded test driver. If a load test shows that we had a maximum of five requests per second, each one taking 200 ms in a system with ten threads, then we know something is wrong. According to Little's Law, we should have had ten times the throughput as we had 10.000ms of available time across the ten threads. In this case the load generator did not succeed in putting our system under an appropriate load and the test does not represent the limit of our application.
Amdahl's Law
Amdahl's Law defines the effect of parallelization on the response time of a system. Let us look at an example. If we can parallelize 200 ms of a request taking 500 milliseconds and divide the execution to 4 processes, we achieve a response time of 350 (300 + 200/4) milliseconds.
This concept is exploited primarily in grid and large batch systems, in which a high degree of parallelization can be achieved. The higher the proportions of parallelization, the greater are the effects.
Amdahl's Law cannot be used 1:1 for the amount of execution time gained. However, analogous considerations help us understand which effects parallelization has on an application. It can also be used for an estimation of effectiveness. At a particular point, parallelization no longer makes sense because the gain in overall performance is very low.
Table of Contents
Application Performance Concepts
Memory Management
How Java Garbage Collection Works
The Impact of Garbage Collection on application performance
Reducing Garbage Collection Pause time
Making Garbage Collection faster
Not all JVMS are created equal
Analyzing the Performance impact of Memory Utilization and Garbage Collection
The different kinds of Java memory leaks and how to analyze them
High Memory utilization and their root causes
Classloader-releated Memory Issues
Performance Engineering
Virtualization and Cloud Performance
Try it free
