
Last week, news began to leak out of some major flaws in common CPU architectures which could be used by the Spectre and Meltdown exploits. There are plenty of articles describing the why and how these exploits work, what is not known is what the impact that the patches/fixes will have on applications and end users. In this article we will explore how we are using AI (Artificial Intelligence) to watch the metrics most likely impacted by these fixes.
All of the major vendors from Intel & AMD to Apple & Microsoft to Google & Amazon have released statements on how they are reacting to these exploits. In almost every case, the near-term fixes will be software based patches, and most will inevitably result in code executing more slowly. The impact of these exploits will vary based on how your application has been deployed (I’ll explain this in a little more detail in a minute). Given the increasing complexity of applications and the reliance on the cloud where virtualization is particularly impacted by these fixes, understanding the performance impact of these fixes is more important than ever.
The fixes will likely not only impact performance, given the processing required to support modern applications it will impact capacity. Expect your operational compute costs to go up unless you start doing some code optimization now.
Most importantly, you need to maintain a close watch on your user experience and application performance, as the impact of these patches will have different impacts based on architecture and design (more on that below). Your end users should notice no change to their overall experience. Our recommendations on ‘what to watch’ are designed to ensure you continue to delight your users, and that you are able to do so by managing your operational capacity as a means to this end
This article from Ars Technica points out that we are already seeing an impact of some of these fixes. The article correctly states that YMMV (Your Mileage May Vary) in terms of the impact these fixes will have. Let’s have a look at a couple of categories to watch:
Impact on Monolithic Applications
Let’s look at the impact these fixes will have on Monolithic applications (we use this term to describe the classic on-premise application which exists in a traditional data center).
The tongue and cheek response to the Twitter thread (in this article) indicates that “sure your CPU goes from 98% idle to 96%” is not that much to worry about… It’s not that simple.
Yes, Monolithic application servers tend to have capacity overhead which can easily absorb a small CPU processing increase, however even Monolithic applications depend on components which are highly optimized in terms of their processing usage. For example: databases and message queues are often highly optimized, meaning there is very little room for CPU performance increases on these servers.
Applications are highly complex, there is rarely a single server involved, most run hundreds of processes and services running on dozens of hosts which are all impacted by these exploits.
Unless you are monitoring every server (what we call hosts) you are exposing yourself to risk that the fixes for Spectre & Meltdown may be impacting the performance of particular components of your application.
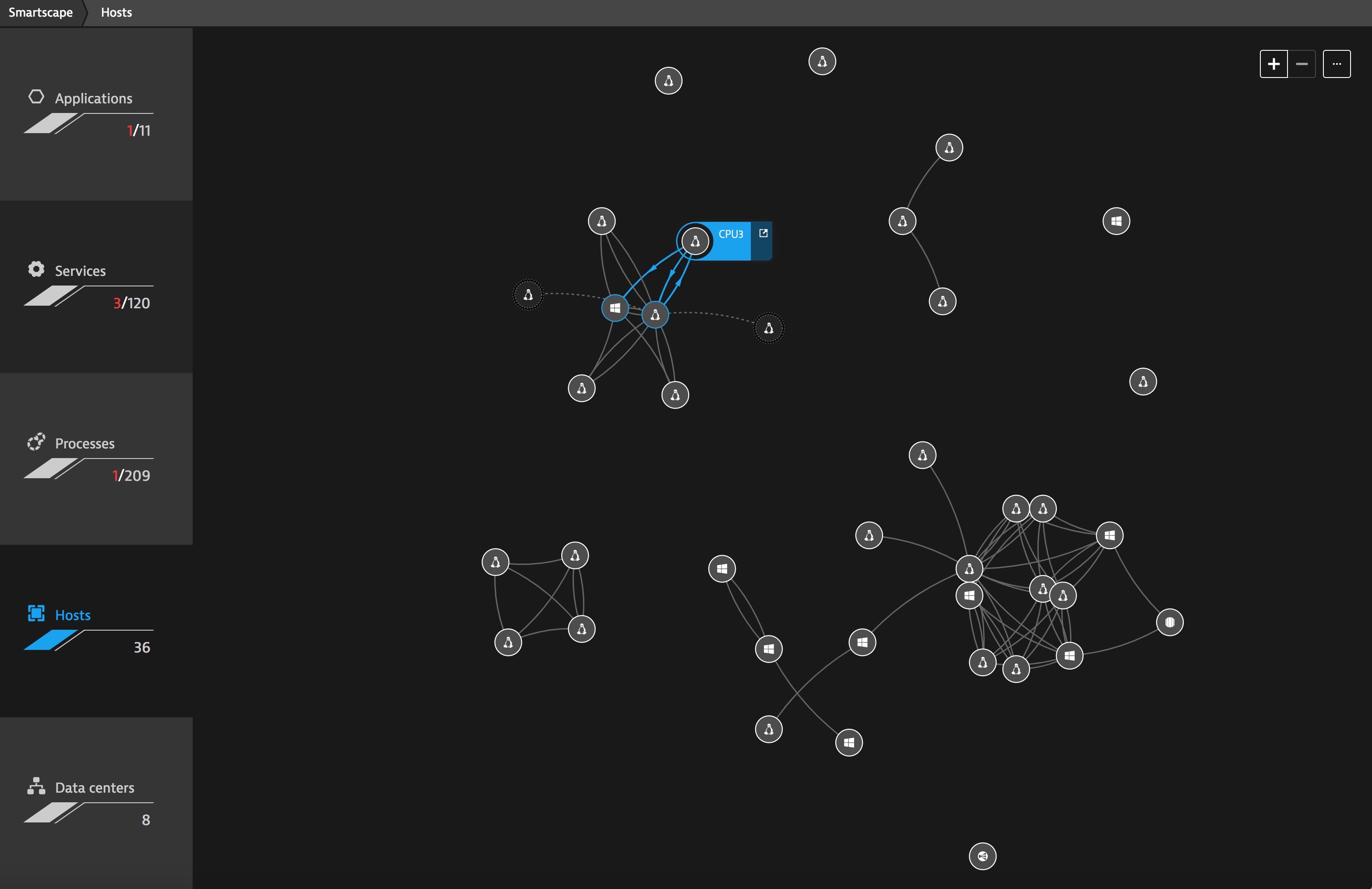
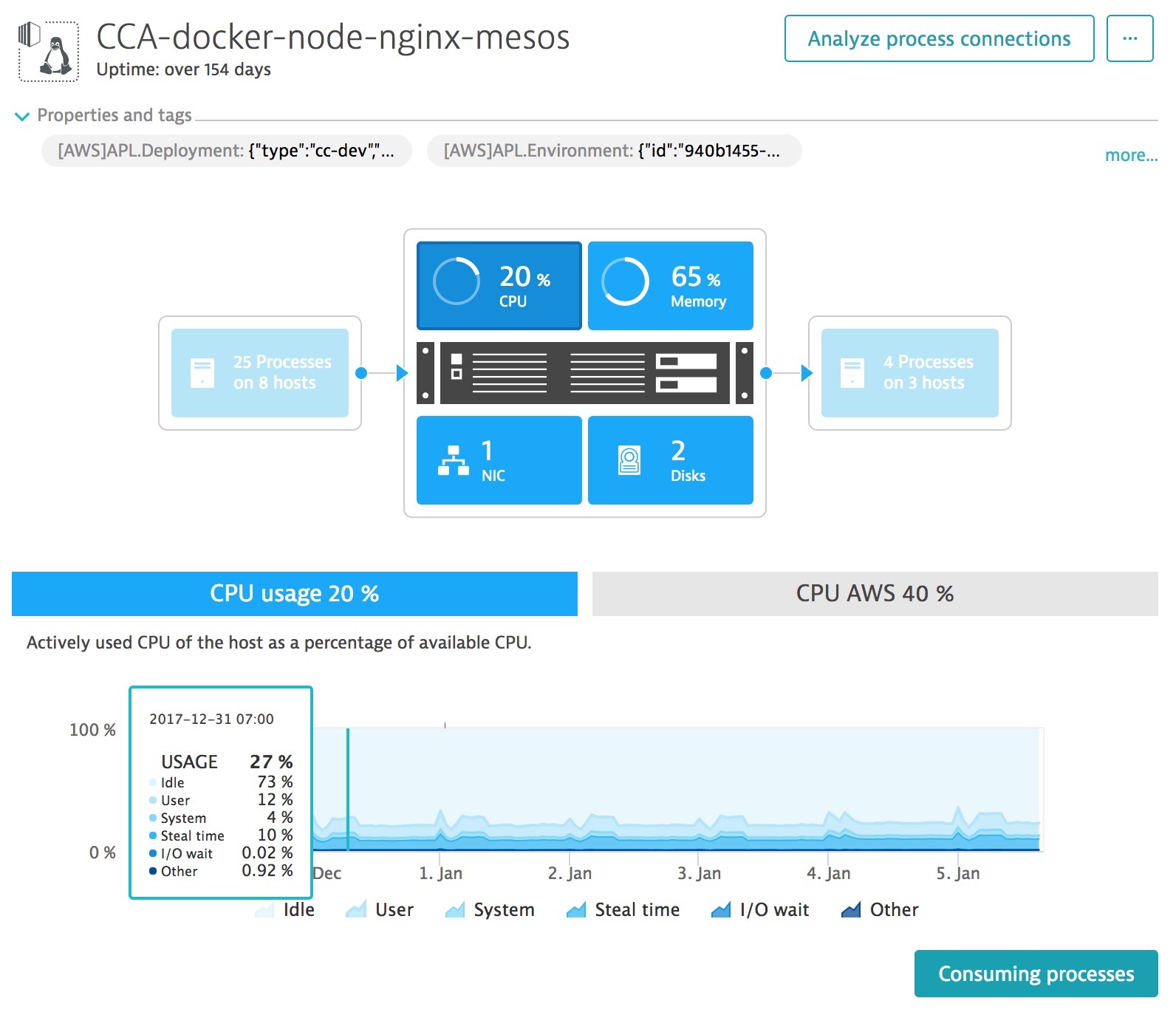
You need make sure you are monitoring all of your infrastructure, above is an example of an automatically generated Dynatrace SmartScape. Dynatrace auto-discovers hosts within your environment and begins to automatically monitor metrics like CPU usage.
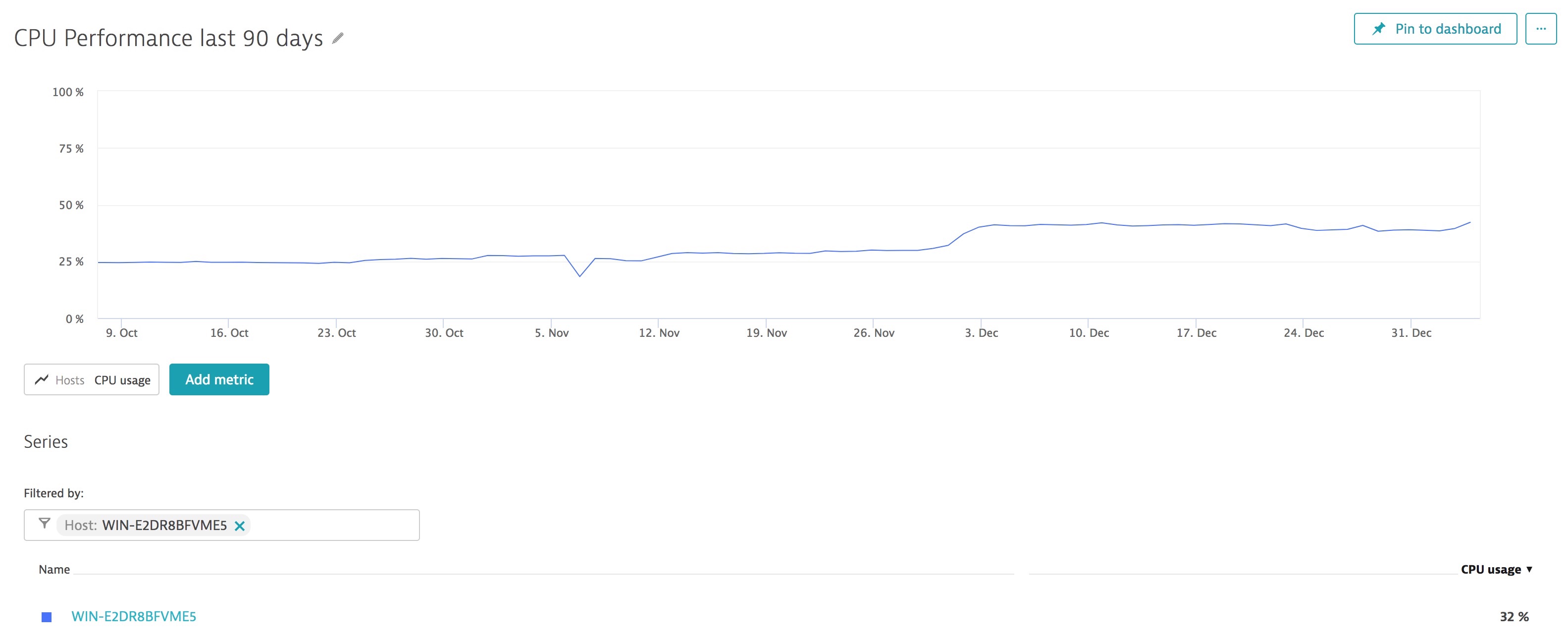
The Dynatrace AI automatically begins creating a baseline of your CPU and looks for anomalies which could be caused by the performance impact of fixes deployed to deal with Spectre & Meltdown exploits.
Impact on Cloud Application
Let’s look at the impact these fixes will have on cloud based applications. Amazon has released the following information on how it is responding to these exploits. The key takeaway from this is that while the majority of applications may not have any performance impact by these fixes, how do you know if your application is being impacted?
Cloud applications rely heavily on virtualization to maximize efficiency within their environments. In addition, the advent of containerization even further maximizes the efficiency of Cloud environments. Containers typically run in environments which are highly optimized and have little tolerance to decreases in CPU performance.
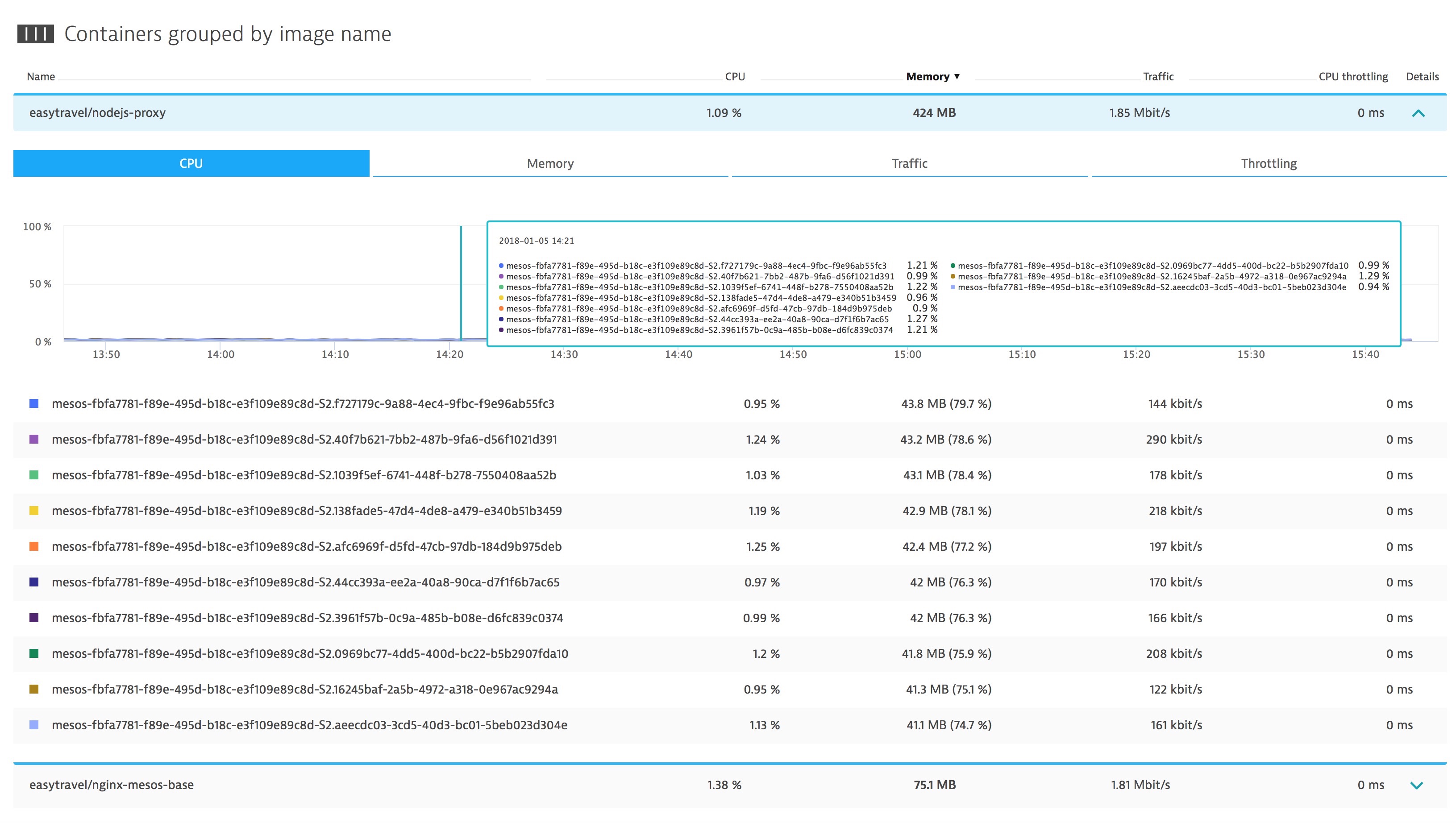
Above, we can see how Dynatrace auto-discovers containers and where the Dynatrace AI starts to baseline the CPU performance for the processes running within those containers. If a Docker Host is having resource contention issues due to the deployment of the exploit patches, the Dynatrace AI will be able to automatically detect this and determine where code can be optimized to run even more efficiently to offset the performance impact of the exploit fixes.
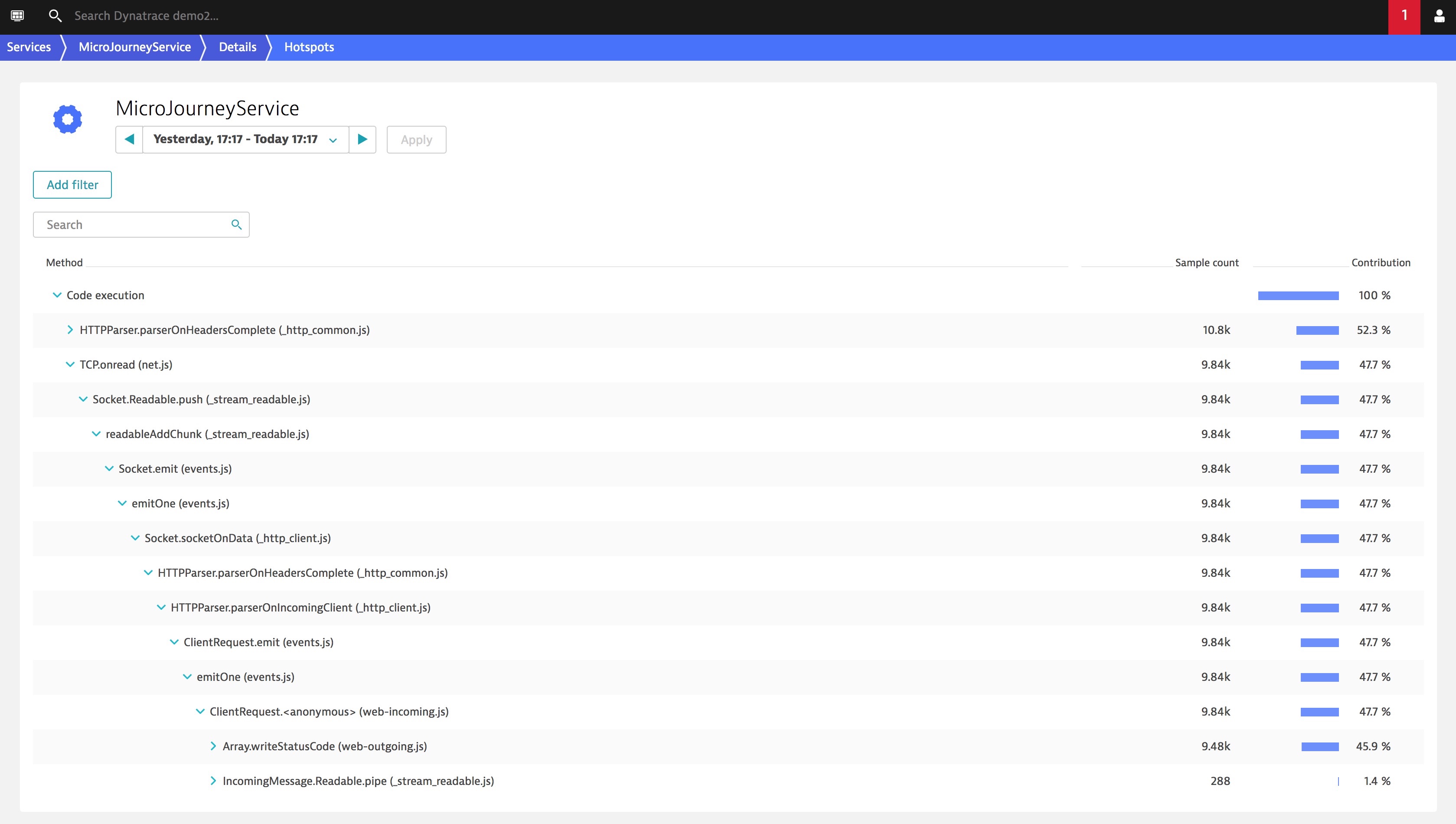
Above is an example of how Dynatrace can see inside of the code running within a container to identify which method can be optimized.
What this means, is that there is an option available, so that rather than increasing your operational cost by consuming more cloud services to offset the performance impact these fixes will have on your environments, you can optimize your code to run more efficiently on the same foot print.
What to Watch
Monitoring simple CPU usage alone is not enough. Memory usage on hosts is more involved.
In the example above, the Dynatrace AI monitors and baselines more details around CPU resources. These are not only the CPU usage, but Idle, user, system, Steal time, I/O wait and other. Monitoring and creating baselines of this CPU detail will be important as the patches for Spectre & Meltdown directly impact how CPUs behave when processing code.
In virtual environments, CPU resources are shared across VMs on the server. In situations where your VM displays a high percentage of Steal time, this may mean CPU resources are being removed from your VM for other commitments. In these situations, your VM may be using more than its share of CPU resources or your physical server may be over-subscribed. In either event if the patches are going to impact your performance it will likely start here.
Remember that even in cloud environments, you may think you are OK but if you are running in a segment which has other “neighbors” using shared resources how do you know when suddenly, their applications start consuming those shared resources?
The type of problem pattern you can expect to see is going to be CPU Saturation
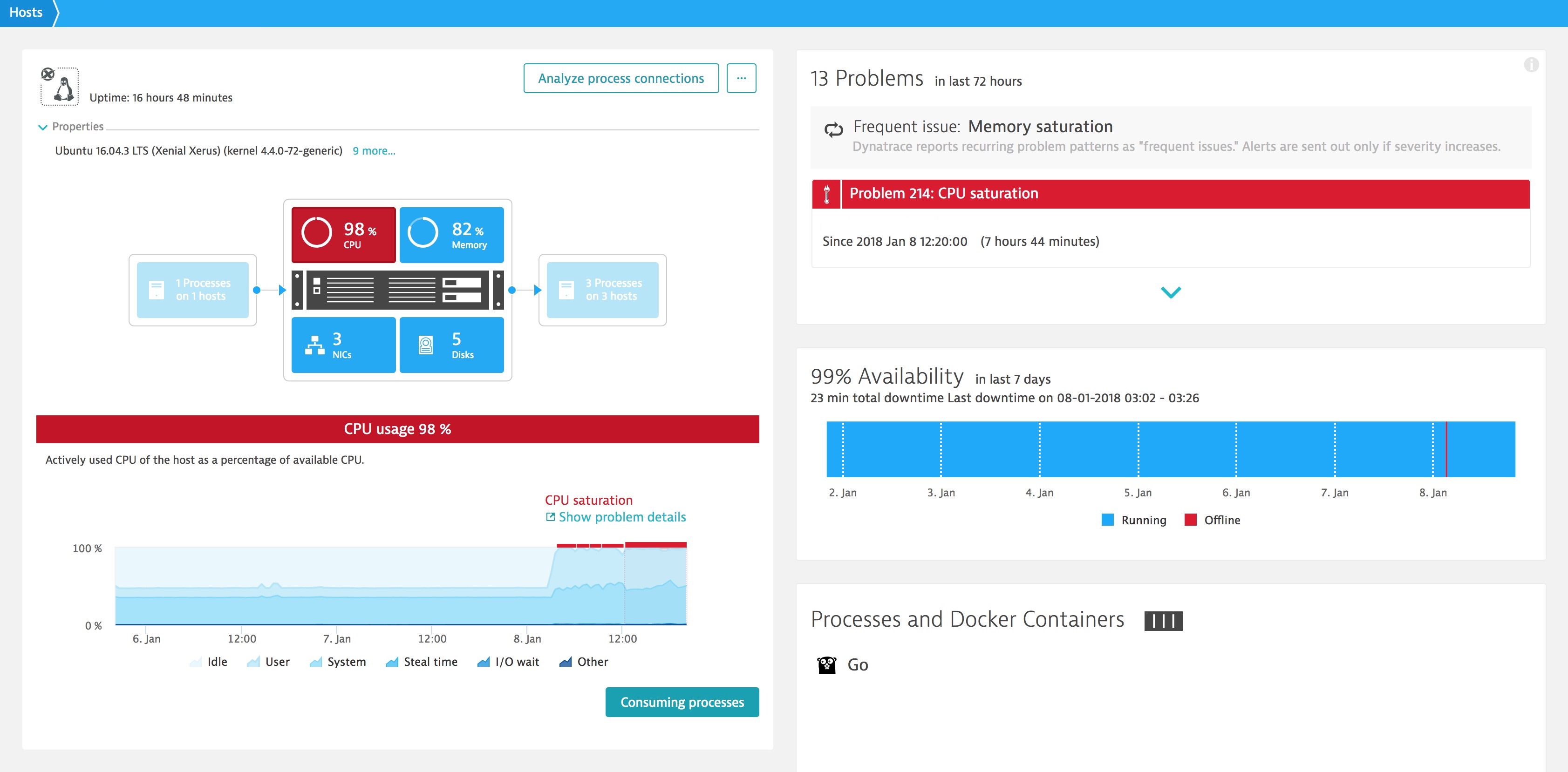
Another metric to monitor will be your spend. The cloud is not free, what you have been spending in the past may not remain the same after these patches are applied. Keep a close eye on having to increase your capacity to maintain the same levels of performance. One way to do this is to keep an eye on your processing throughput, for example the number of requests being handled. If you see a decrease in the number of requests being process on the same infrastructure that is a good indicator that you have a problem.
While monitoring this detail is important from an operational planning stand point you also need to make sure that this performance hits on the server side are not translating to performance hits for the end user.
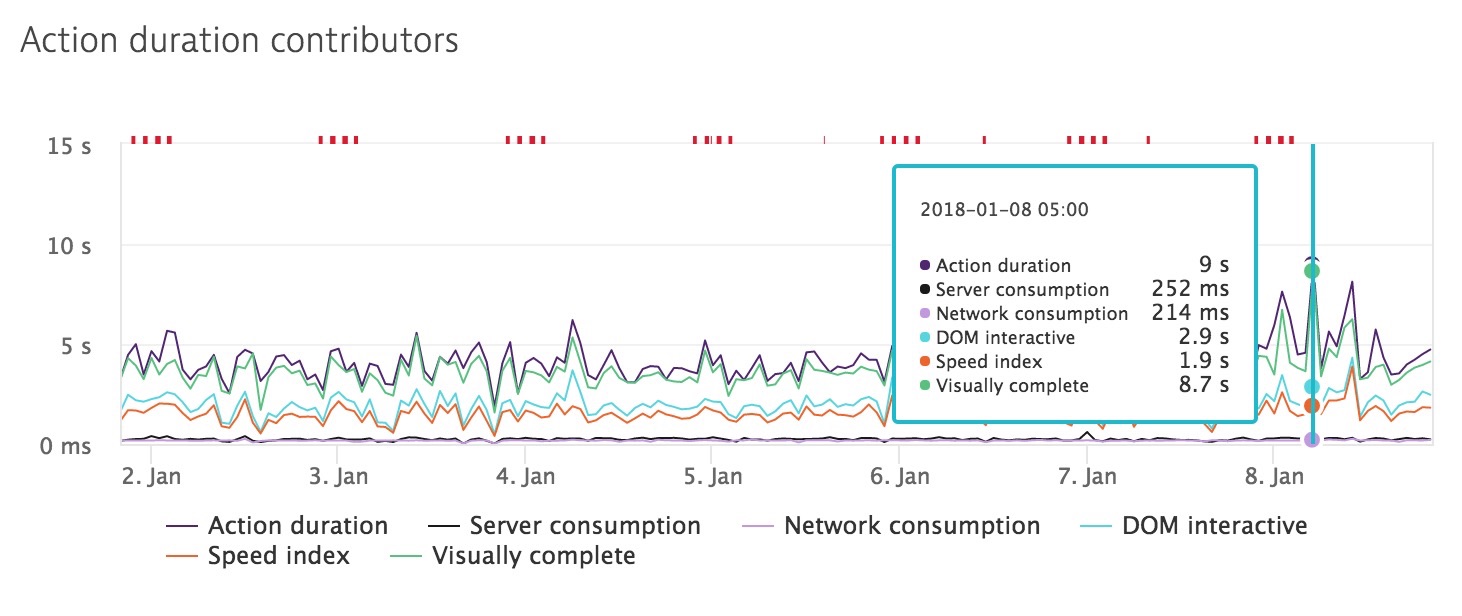
Everyone needs (more than ever) to get some visibility into their infrastructure. If you are unsure of how the patches for Spectre & Meltdown are impacting your applications here is a free trial of Dynatrace with its AI-based monitoring capabilities to ensure you are prepared for understanding the performance impact of the fixes for these critical exploits.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum