
Kubernetes is used by many organizations to build, deploy, and manage large-scale distributed applications. However, the overwhelming advantage of running applications on Kubernetes comes at a cost. Progressive rollouts, rollbacks, storage orchestration, bin packing, self-healing, cost efficiency, and access to the Cloud Native Computing Foundation (CNCF) ecosystem carry heavy observability challenges. Incidents are harder to solve. Triage and diagnosis become a long process of hunting for clues.
With the release of Dynatrace version 1.249, the Davis® AI Causation Engine provides broader support to subsequent Kubernetes issues and their impact on business continuity like:
- Automated Kubernetes root cause analysis
- Davis AI targeting Kubernetes orchestration
- Correlating performance issues with Kubernetes pod evictions
- Degraded performance in relation to Kubernetes workload misconfigurations
These crucial enhancements provide significant advantages in meeting your Kubernetes performance goals while avoiding potential service disruptions.
Automated Kubernetes root cause analysis: a paradigm shift
The sheer volume and “noise” from multiple containers, pods, nodes, and clusters – usually not knowing exactly what you’re looking for – makes traditional search and drill-down techniques cumbersome and slow. Critical problems demand smarter decisions and the elimination of confusion and wasted time. Dynatrace Davis AI root cause analysis is the critical path forward—the Davis AI engine now automatically detects Kubernetes workload and platform problems that cause failures, slowdowns, abandoned shopping carts, and lost business.
Davis AI targets Kubernetes orchestration: in real-time
Kubernetes can encounter problems while attempting to change an application’s state back to the intended state declared in Git—deployment mistakes, unpredictable traffic patterns, and resource miscalculations can make such state changes impossible. The Dynatrace Davis AI engine now targets such Kubernetes problems in real time, allowing ops teams to reduce the related business and user impact.
Kubernetes problems can impact users by increasing failure rates or response times. Such problems include:
- Pod evictions due to resource exhaustion
- Changes in workload resource requests and limits
- Inadequately tested container images deployed to production
- Misconfigured configurations, environment variables, or other settings
Problems like these are situationally challenging to understand and require involvement from both application and Kubernetes ops teams. Understanding root causes and planning remediation can be stressful. As minutes tick by, alerts are triggered, and customers complain. Dynatrace Davis AI now helps prevent such scenarios.
Performance issues and Kubernetes pod evictions
Evictions usually occur when exhausted memory or disk pressure forces Kubernetes to terminate pods on a node proactively. Evictions are an example of Kubernetes attempting to bring applications—or the cluster itself—to a declared state. Preventing evictions is unnecessary, as they’re a regular Kubernetes operation and may not impact users. Setting alerting thresholds on evictions doesn’t work because evictions are usually only the symptom of a problem, not problems in and of themselves.
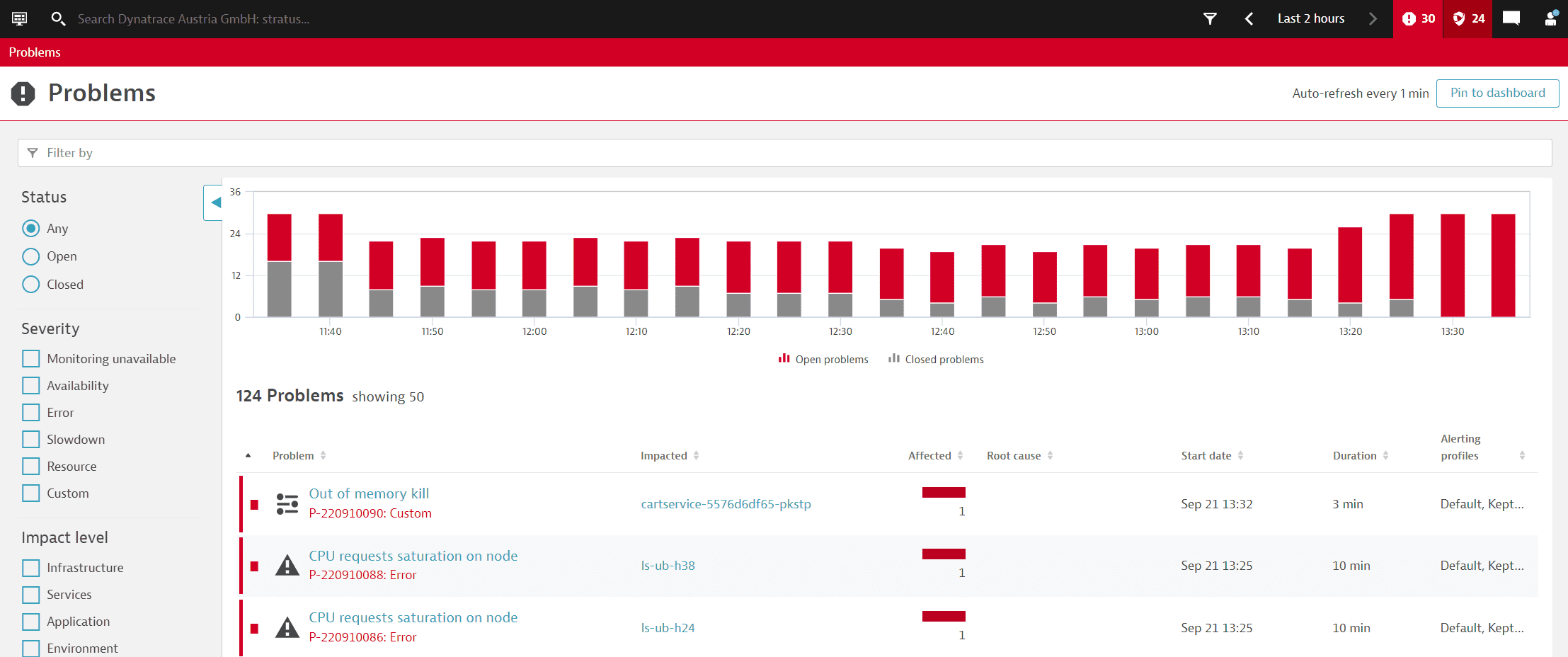
A better way of framing evictions is in the context of the root cause. Such context is easy to understand using the Dynatrace Davis AI engine. The screenshots below show a Davis-detected problem that resulted from pod evictions. Unlike evictions from resource exhaustion on a node, this event resulted from ephemeral storage limits exceeded on the pod. The first screenshot shows the left side of a Davis problem page. Here you see the incident and its impact on users and microservices. Fortunately, the problem was detected while only a fraction of current users were impacted.
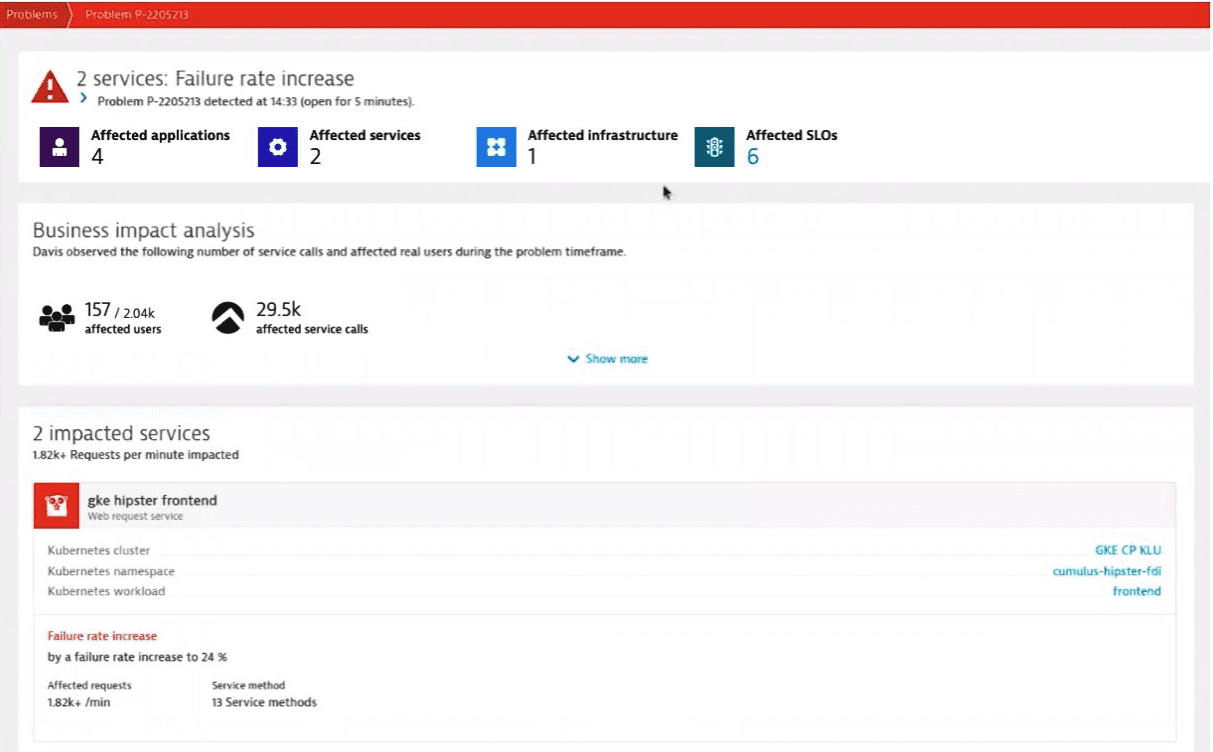
The screenshot below shows the right side of the Davis problem page. A microservice has been identified as the root cause of the problem—the service is running in a Kubernetes pod rather than at the node level. Two Kubernetes signals are also highlighted, showing that the pod was killed and purposely evicted.
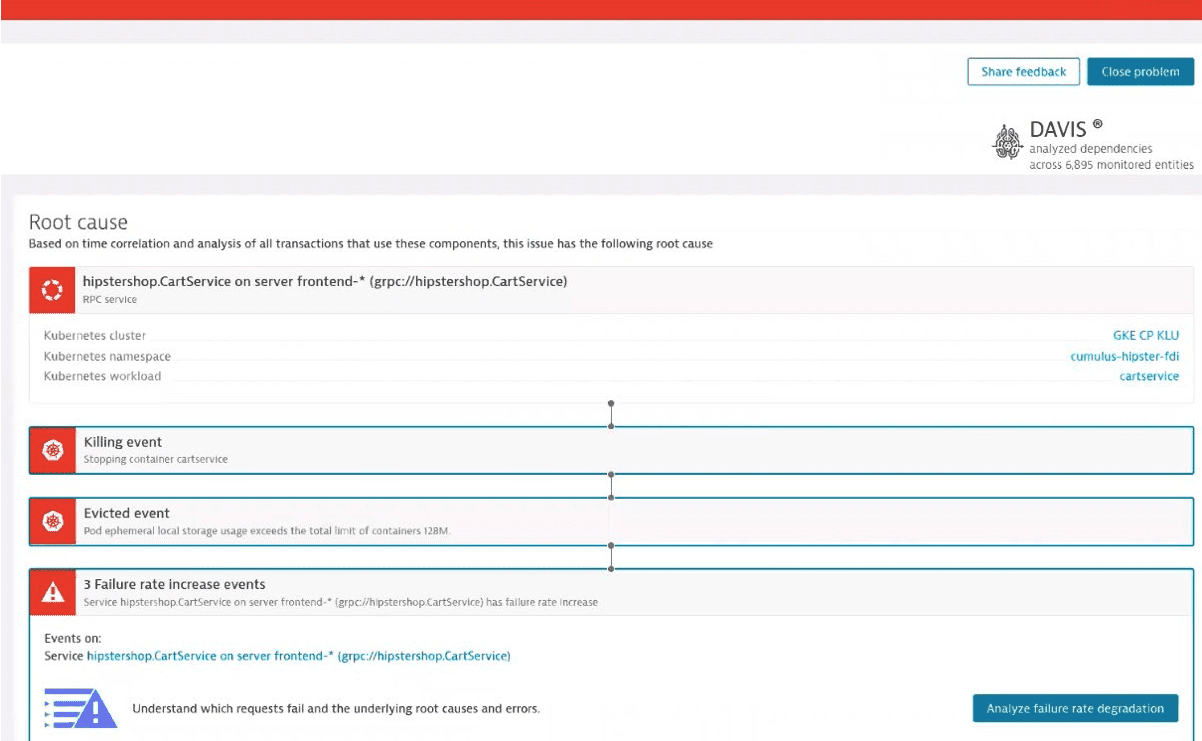
Davis AI root cause analysis demystifies this problem and provides immediate insight (a healthy node with evicted pods resulting to degraded performance would otherwise be a mystery). The Kubernetes ops team can adjust and redeploy the workload, and save users from frustration without bothering application teams or engaging in prolonged investigation.
Degraded performance and Kubernetes workload misconfigurations
Kubernetes’ many advantages translate into shorter development cycles. Faster cycle times mean greater agility, but velocity can lead teams to pay less attention to detail. Improper resource limits, mistakes in configurations, or poorly tested container images are complex problems to identify using traditional techniques.
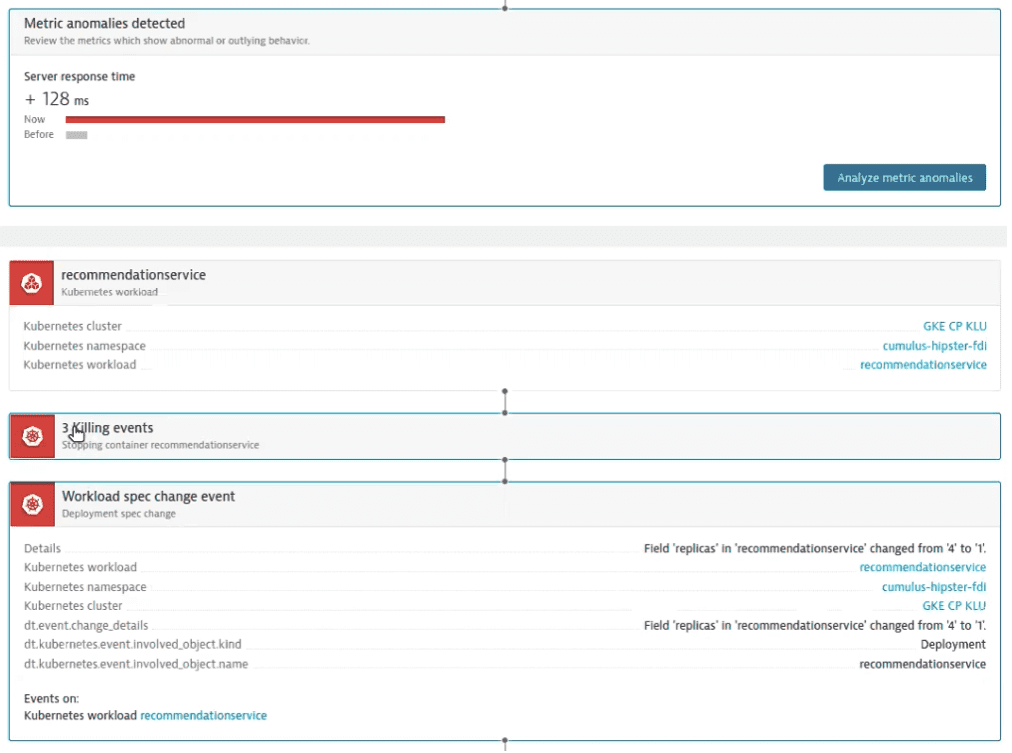
The Dynatrace Davis AI engine can identify these problems as root causes based on changes to the deployment manifest of any Kubernetes workload. The screenshot below shows a Davis problem impacting users with increased microservice failure rates. The problem occurred when a new container image was deployed as part of a large changeset. Davis AI shows the root cause analysis, including the workload spec changes that caused the microservice failures in the same pod. Precise answers like these reduce MTTR by revealing clear remediation steps for rollback.
Detection of these Kubernetes signals in Davis AI was released with Dynatrace SaaS cluster version 1.249 .
What’s next: Sneak peek at new Kubernetes anomaly detection at scale
Soon, in an upcoming release, Dynatrace will offer anomaly detection at scale for a wide range of common Kubernetes problems. Operations teams can analyze anomalies—such as node readiness, CPU, or memory capacity issues—without configuring individual alerts ahead of time. Anomaly detection at scale means automatically applying default or custom sensitivity thresholds across each layer of a Kubernetes infrastructure. This is a superior solution to contemporary methods of creating alerts and monitors.
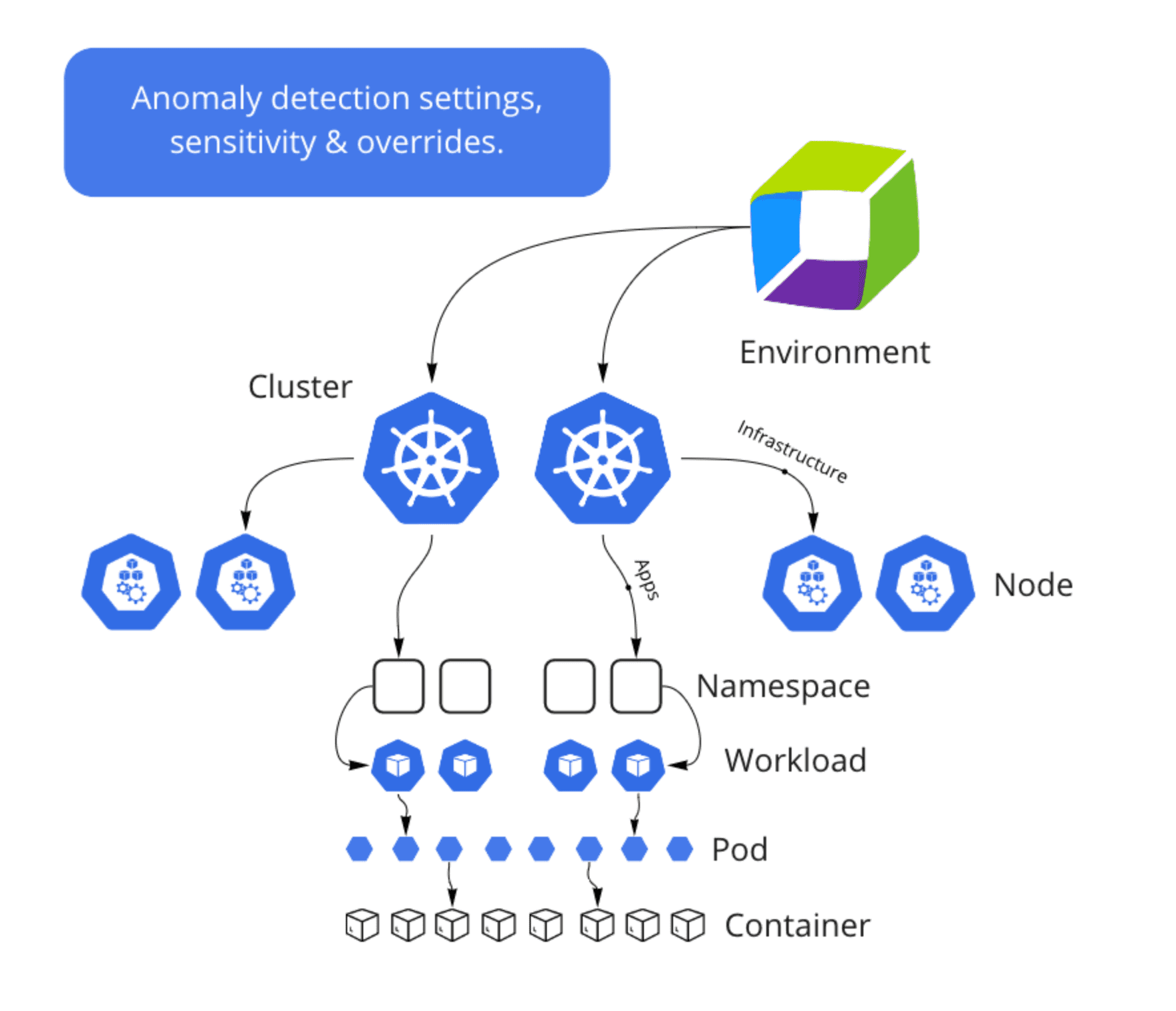
Kubernetes problems surfaced by Dynatrace anomaly detection will appear as in the context that makes sense (cluster, node, or workload level).
Get started with Dynatrace and Davis AI for Kubernetes
- If you’re already a Dynatrace customer, refer to our updated Kubernetes deployment instructions.
- New to Dynatrace? Sign up for a fully-functional Dynatrace free trial.
Kubernetes in the wild report 2025
Uncover global Kubernetes adoption trends, cost-optimization strategies, and key tools driving innovation for thousands of organizations worldwide. This report highlights global trends in the technology’s adoption and usage in production environments from thousands of organizations across diverse industries.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum