

DevOps monitoring
Eliminate silos, improve cross-team collaboration, and release better software faster.

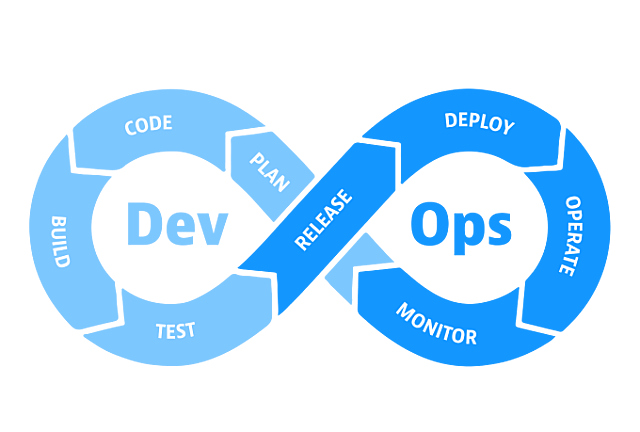
What is DevOps monitoring?
DevOps monitoring involves constant assessment of software health, allowing practitioners to understand and proactively resolve issues, optimize resources, and ensure smooth application performance throughout the SDLC.
Drive benefits across the enterprise
Grow the business
Innovate faster and make customers happier
Spend less time performing manual tasks and triaging issues, and more time innovating. An efficient and scalable DevOps approach helps teams exceed customer expectations and gain a competitive edge.


Streamline it
Increase speed, quality, and throughput
Build a highly integrated DevOps toolchain with observability, automation, and AI at the core to help accelerate the speed of delivery, improve code quality, and increase DevOps throughput.
Change the culture
Build a more productive and collaborative culture
Eliminating friction and silos between Dev and Ops, and rallying everyone around a single source of truth enhances communication and builds a culture of trust, collaboration, and success.

Research report
DevOps Automation Pulse: The current state of DevOps automation

Research Report
DevOps leaders face pressure to innovate faster amid rising cloud complexity
DevOps best practices to know
-
Continuous integration
A software development practice where developers regularly merge their code changes into a central repository, after which automated builds and tests are run.
-
Continuous delivery
Code changes are automatically built, tested, and prepared for a release to production. Done properly, developers will always have a deployment-ready built artifact.
-
Continuous observability
Continuous observability of your system across all stages of DevOps allows you to manage the performance and availability of software applications. This leads to quick response times, improved computing processes and satisfied customers.
-
Shift-left
Process of pushing testing (code quality, performance & security) toward the early stages of the SDLC. By testing early and testing often, you can find and remediated bugs earlier and improve the quality of software.
-
Shift-right / Progressive delivery
Process of monitoring, observing, and testing (resiliency, reliability and security) of new releases “in production” to ensure correct behavior, performance, and availability.
Insights from our experts
Blog post
What is DevOps?
BLOG POST
Understanding continuous integration and continuous delivery (CI/CD)
BLOG POST
Site reliability engineering: 5 things to you need to know
Blog post
What is DevSecOps?
Knowledge Base
What is continuous delivery?
BLOG POST
SRE vs DevOps: What you need to know
INFOGRAPHIC
Common SLO Pitfalls and how to avoid them
BLOG POST
What are SLOs?
2021 DevOps Report
What’s the key to scaling DevOps practices?








