
DevOps monitoring
Unify development and operations around real-time insight to accelerate delivery and improve software quality.


What is DevOps monitoring?
DevOps monitoring is the continuous practice of observing application behavior, infrastructure health, and delivery signals across the software lifecycle to help teams detect issues early, understand impact, and increase delivery velocity without compromising reliability.
Drive benefits across the enterprise
Turn software delivery into measurable impact
Give teams the confidence to push updates, fixes, and optimizations from development through testing and into production without slowing down. Modern software delivery reduces outages, improves customer experience, and allows the business to respond in real time.

Increase speed, quality, and reliability at scale
Build a modern software delivery foundation grounded in observability, automation, and AI. Provide DevOps teams the visibility and control they need to detect risk earlier, automate routine decisions, reduce incident fallout, and sustain high deployment velocity without increasing operational load.

Create shared ownership of reliability and delivery outcomes
Align teams around a common view of system health, release impact, and production risk. Shared context replaces handoffs and guesswork with coordination, clear accountability, and a culture build on modern software delivery practices.

DevOps Automation Pulse: The current state of DevOps automation

DevOps leaders face pressure to innovate faster amid rising cloud complexity
DevOps best practices to know
-
Continuous Integration / Continuous delivery (CI/CD)
Framework in which code is regularly merged into a central repository (CI) for automated builds and tests, facilitating a release to production (CD). With this practice, deployment-ready built artifacts are always available.
-
Continuous observability
Continuous observability of your system across all stages of DevOps allows you to manage the performance and availability of software applications. This leads to quick response times, improved computing processes, and satisfied customers.
-
DevSecOps
DevSecOps expands the impact of DevOps by adding security practices to the software development and delivery process. It resolves the tension between DevOps teams that want to release software quickly, and security teams that prioritize security over all else.
-
Continuous automation
In addition to CI/CD, bringing automated testing, monitoring and remediation to the DevOps lifecycle shortens innovation cycles, speeds up application delivery and reduces MTTR.
-
AI-powered DevOps
AI integrated into DevOps allows for quicker identification and resolution of issues through root cause analysis, improved collaboration between teams, and the ability to make risk-free release decisions.
-
Shift-left/Shift-right
Testing code quality, performance, & security early in the SDLC for proactive remediation (shift-left) while also observing new releases in production to continuously ensure optimal performance (shift-right)
Driving DevOps and platform engineering for digital transformation
Download the free ebook to discover the nuances, best practices, and tangible benefits that DevOps and platform engineering bring to organizations and more.

Insights from our experts
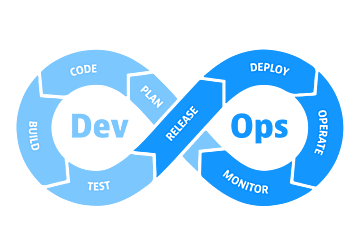 Blog postWhat is DevOps?
Blog postWhat is DevOps? BLOG POSTUnderstanding continuous integration and continuous delivery (CI/CD)
BLOG POSTUnderstanding continuous integration and continuous delivery (CI/CD) BLOG POSTSite reliability engineering: 5 things to you need to know
BLOG POSTSite reliability engineering: 5 things to you need to know Blog postWhat is DevSecOps?
Blog postWhat is DevSecOps? BLOG POSTSRE vs DevOps: What you need to know
BLOG POSTSRE vs DevOps: What you need to know BlogShift left vs shift right: A DevOps mystery solved
BlogShift left vs shift right: A DevOps mystery solved





