
Today's organizations need a new approach to software intelligence. See how a data and analytics-powered approach unifies observability and security data while generating real-time insights.
Software and data are a company’s competitive advantage. That’s because every company is now a software company. As a result, organizations need software to work perfectly to create customer experiences, deliver innovation, and generate operational efficiency. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. That’s exactly what our platform does.
Much of the software developed today is cloud native. However, cloud infrastructure has become increasingly complex. This requires hundreds of interdependent services to work perfectly. Organizations must update services and apps dozens of times a day. Further, the delivery infrastructure that makes this happen has also become complex. The only way to address these challenges is through observability data — logs, metrics, and traces. But it doesn’t stop there.
Teams interact with myriad data types. For example, users generate user data, ecommerce sites generate business data, and service portals generate service desk tickets and call volume data. But how is this data connected? That’s where context comes into play.
Organizations need to unify all this observability, business, and security data based on context and generate real-time insights to inform actions taken by automation systems, as well as business, development, operations, and security teams.
Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost.
With a data and analytics approach that focuses on performance without sacrificing cost, IT pros can gain access to answers that indicate precisely which service just went down and the root cause.
The next frontier: Data and analytics-centric software intelligence
Modern software intelligence needs a new approach. It should be open by design to accelerate innovation, enable powerful integration with other tools, and purposefully unify data and analytics. Enter Grail-powered data and analytics.
Grail is a purpose-built data lakehouse for observability, security, and AIOps. Grail makes it possible to converge real-time analytics, historical analytics, and predictive analytics on a single platform.
This purpose-built data lakehouse approach for observability, security, and AIOps offers schema-less ingestion of various data types, including logs, metrics, traces, user data, business data, and topology data. Additionally, it provides index-free storage and direct analytics access to source data without requiring data rehydration.
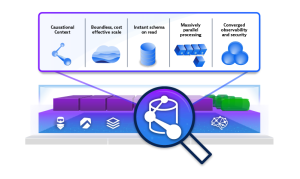
Ultimately, this helps address data scale and access performance constraints that prevent organizations from unlocking data’s full potential.
Here are six steps to creating a modern data stack and AI strategy for observability, AIOps, and application security.
1. Identify the business outcomes
It’s important to understand what business outcomes you want to achieve. Your key business objectives will drive your strategy and metrics. An example is improving customer experience. Customers today expect a very high level of experience when they engage with an organization.
Consider the data needed and its source. Collecting logs, metrics, events, and trace data is great. But for full-stack observability, you also need to bring together the topology data model, code-level details, and user experience data. If you’re using an approach that employs disparate tools to monitor individual components of the stack separately, then you’re leaving value on the table by failing to take a platform approach. Individual tools continue to promote and generate data silos and prevent organizations from using data effectively.
Modern observability platforms make it possible to centralize observability data from even the most complex stacks and get answers that help you achieve your desired business outcomes.
2. Ingest all the data you need from anywhere
A combination of proprietary and open source technology can speed data ingestion from common and long-tail sources. You need data from myriad sources centralized to get the right context to power precise answers. This is where a data lakehouse with software intelligence comes into play. A purpose-built data lakehouse can ingest a variety of data sources without requiring tradeoffs between data storage and performance.
Don’t reinvent the wheel. Between Dynatrace OneAgent and open source observability frameworks such as OpenTelemetry, you are well covered. These two technologies enable you to ingest all types of observability data — logs, metrics, traces, user experience, and business data.
Logs. Systems automatically generate logs, which record events that took place. Log entries usually contain the following:
- Date and time of event;
- System or resource name;
- App name; and
- Event severity.
Logs come in different formats depending on the source system — including key-value pairs, JSON, CSV, and more.
Metrics. This data is aggregated over a period of time. For example, this includes CPU utilization, memory percentage in use, and average load times.
Traces. A trace is the path a transaction took in an application for completion — for example, querying a database or executing a customer transaction. A trace is usually shown from the beginning of the transaction to the end.
User experience data. Web and mobile apps record data about every user interaction. This data includes information about crashes, lags, rage clicks, user interface hangs, and time spent in apps.
Business data. This data is anything generated from business operations. For example, this includes conversion rate, average order value, cart abandonment rate, service desk ticket, and call volume data.
3. Unify and centralize observability, security, and business data
Centralizing all organizational data is unrealistic. However, observability, security, and business data are different. Organizations need to instantly process, enrich, contextualize, and analyze all the data that supports mission-critical operations. All the infrastructure metrics, application performance data, and user experience data contain records of not only performance degradation events, but also security threats, fraudulent activities, and customer behavior.
Advances in data storage technology and architectures make it possible to store huge volumes and a variety of observability data in an efficient way that scales as requirements evolve. Centralizing observability data makes it easy to curate high-quality data. As a result, organizations accelerate the process of identifying relationships between entities, connecting the dots between disparate data sets, and gaining ROI from aggregated data with actionable insights.
If data sets are in siloed tools and systems, it slows down the process of delivering precise answers. In contrast, if you preserve and manage all the relationships between all data, it makes it possible to do more deterministic, causational AI on this data, resulting in precise answers.
4. Use AI to generate answers and insights from data
Once you unify and centralize the relevant data, you can apply real-time data processing to identify the precise root cause of issues and generate actionable insights. Successfully doing so at scale requires AI to identify the relationships and context between data types.
Having a real-time topology map that tracks all entities is useful. It helps derive context between different data slices. Doing so manually is beyond human capability because of data volumes, ingestion speeds, formats, and the dynamic and complex nature of the application environment and infrastructure. This is where AI excels in data and analytics-powered software intelligence. Continuously processing data from every layer of the stack opens the door to numerous possibilities.
Real-time anomaly detection. Real-time monitoring detects issues within infrastructure and applications before they become costly, customer-facing problems. Anomaly detection helps identify issues that deviate from the norm so teams can proactively resolve them. Getting relevant information to the right teams at the right moment is critical. In part, that involves reducing alerts so IT teams aren’t overwhelmed and can identify high-priority issues. Providing context and a prioritized list of issues helps them focus on the most important tasks.
Automated root-cause analysis (RCA). Automated RCA breaks down an issue into its components and identifies the precise root cause. But without full-stack observability, RCA is impossible. This is because, in many cases, an application issue is tied to a microservice on the back end. Having a real-time topology with deterministic AI helps immediately find the root cause. It saves engineers a lot of time by showing exactly what went wrong and how it happened.
Runtime application security. With continuous software intelligence from full-stack observability data, DevSecOps teams are notified if vulnerable code is called in production applications. By enriching data with vulnerability databases, operations engineers can create a risk-weighted priority list of security issues. Additionally, gaining a complete understanding of vulnerability severity and frequency becomes useful for developers.
5. Use exploratory analytics for lightning-fast answers
Sometimes, teams need to drill deeper into an answer, or a question pops into your mind. Exploratory analytics on a data lakehouse architecture with software intelligence makes it possible to write any query and get an instant answer, thanks to distributed query execution.
6. Automate actions and optimizations powered by AIOps
Automated root-cause analysis eliminates guesswork and human effort. Therefore, IT pros know exactly which code in a software release was problematic, or which server had an issue. Rolling back code deployment or restarting a server makes sense, and you can build rollback into an automated remediation workflow. A shift-left approach helps in designing the remediation mechanism during the early stages of software development. Notifying the right teams of remediation activity closes the loops and removes the burden of manual action.
Data and AI are key to making software work perfectly
Assembling, cleaning, combining, and enriching observability data from various systems is key to getting correct answers. Contrary to popular belief, AI systems easily fall prey to “garbage in, garbage out” principles — that is, the systems are only as good as the quality of the data. Controlling the quality of data is key to getting the right data and the right answers to achieve business goals. A data and analytics platform that includes a data lakehouse design and software intelligence facilitates unifying not only data, but also various analytics workloads for what ultimately matters — time to response and action.
The Dynatrace difference, powered by Grail
Dynatrace offers a unified platform that supports your mission to accelerate cloud transformation, eliminate inefficient silos, and streamline processes. By managing observability data in Grail — the Dynatrace data lakehouse with massively parallel processing — all your data is automatically stored with causational context, with no rehydration, indexes, or schemas to maintain.
With Grail, Dynatrace provides unparalleled precision in its ability to cut through the noise and empower you to focus on what is most critical. Thanks to the platform’s automation and AI, Dynatrace helps organizations tame cloud complexity, create operational efficiencies, and deliver better business outcomes.
Discover how software intelligence as code enables tailored observability, AIOps, and application security at scale.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum