
Having been named as a Leader in the 2020 Gartner APM Magic Quadrant for the 10th consecutive time proves that Dynatrace is the best-of-breed application performance monitoring tool available. Our Davis® AI causation engine can easily detect root causes that are related to service slowdowns or increases in failures. But what happens if a service work perfectly but the underlying infrastructure, such as processes and hosts, experience an outage? To address such issues, Dynatrace Davis® can now also analyze large-scale incidents from the perspective of infrastructure monitoring (IM), in addition to its APM capabilities. As such, Davis automatically detects process and host availability root causes for large-scale, user-impacting incidents. This capability eliminates the need for default trigger events for process availability issues. Therefore, we introduced a new default setting at the process-group level that reduces event spam for non-stable process groups. This setting also allows you to opt into trigger events for your most important process groups. Let’s take a look at how this works.
Davis automatically detects process and host outages as root cause
Take the following example of a critical outage that affects multiple services: Dynatrace Davis automatically analyzes the situation and detects that several important processes were unexpectedly shut down.
See the incident summary from Davis below, where changes in the availability of processes was detected as the real root cause of this problem.
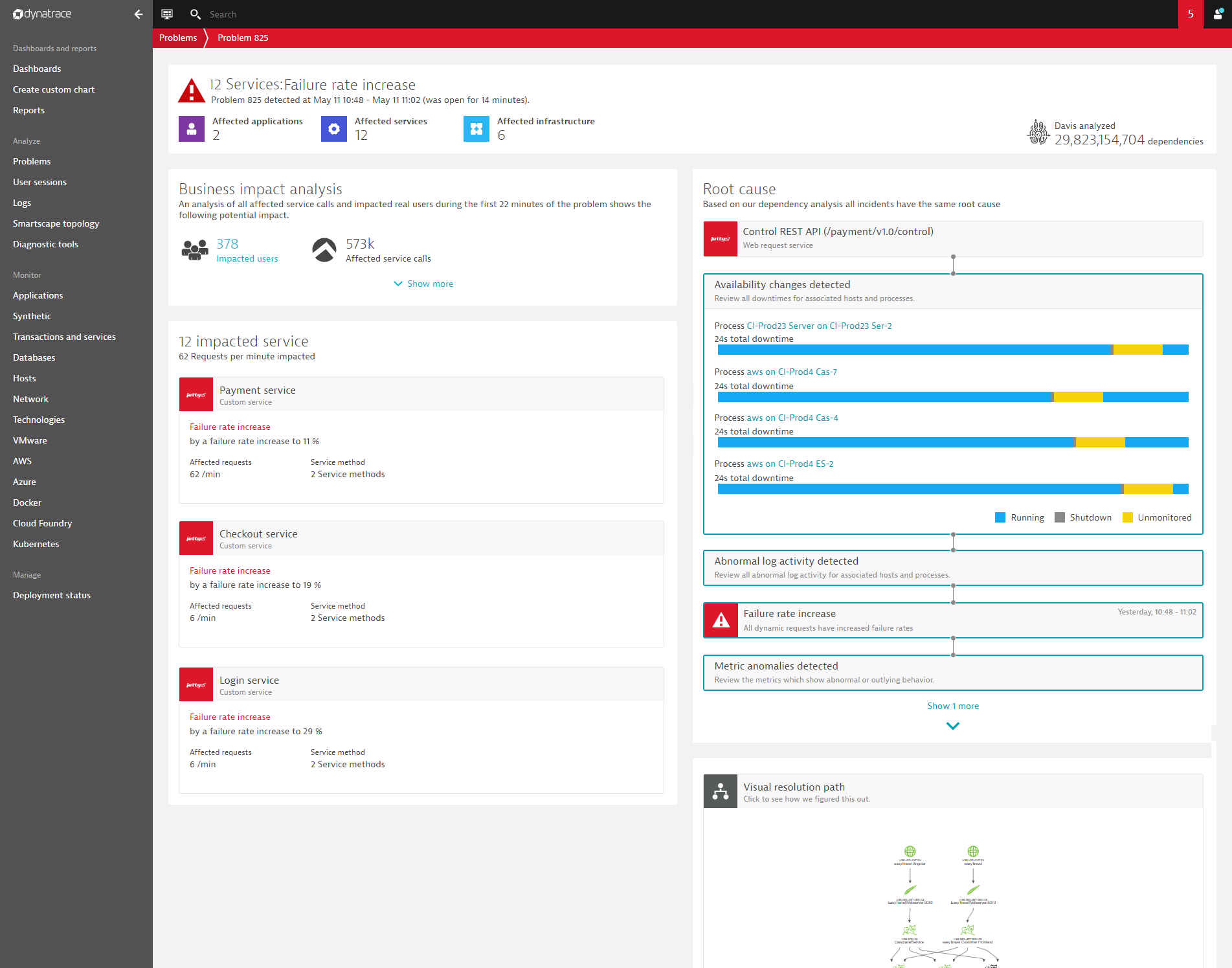
From this example, you can see some key advantages of Dynatrace Davis over other monitoring solutions:
- Davis can detect process- and host-related availability root causes.
- Davis combines APM incident and impact detection with infrastructure monitoring root-cause detection at the process and host level.
- The presented availability root cause summarizes all relevant process and host outages, so there’s no longer a need to click through individual pages to understand the scope of the problem.
As you can see, Davis is perfectly capable of detecting the availability of individual processes and hosts as the root cause of a user-impacting incidents. To be alerted on the availability of your most important process groups however, you need to specifically opt into a Davis availability event trigger at the process-group level.
Receive alerts only for the most important process-group availability issues
Dynatrace version 1.194 includes an important enhancement in process and process-group availability settings.
Instead of reporting process availability events of service-hosting process groups by default, we’ve switched to an opt-in approach for process group alerts. On the settings page for process group availability, you can now see that alerting is disabled by default.

The reason for this change in the default behavior is twofold:
- The new Davis capability of showing process root causes is independent of process-related trigger events.
- A lot of process groups that host services restart on a regular basis. For example, the Tanium Client process group restarts regularly and, therefore, generates a lot of noise from availability events.
If you decide that a process group is stable and important enough to trigger Davis in case of an availability incident, you can choose between the following two options:
Raise an alert when any process in a selected process group becomes unavailable
This option triggers an availability event when any process in the selected process group becomes unavailable.
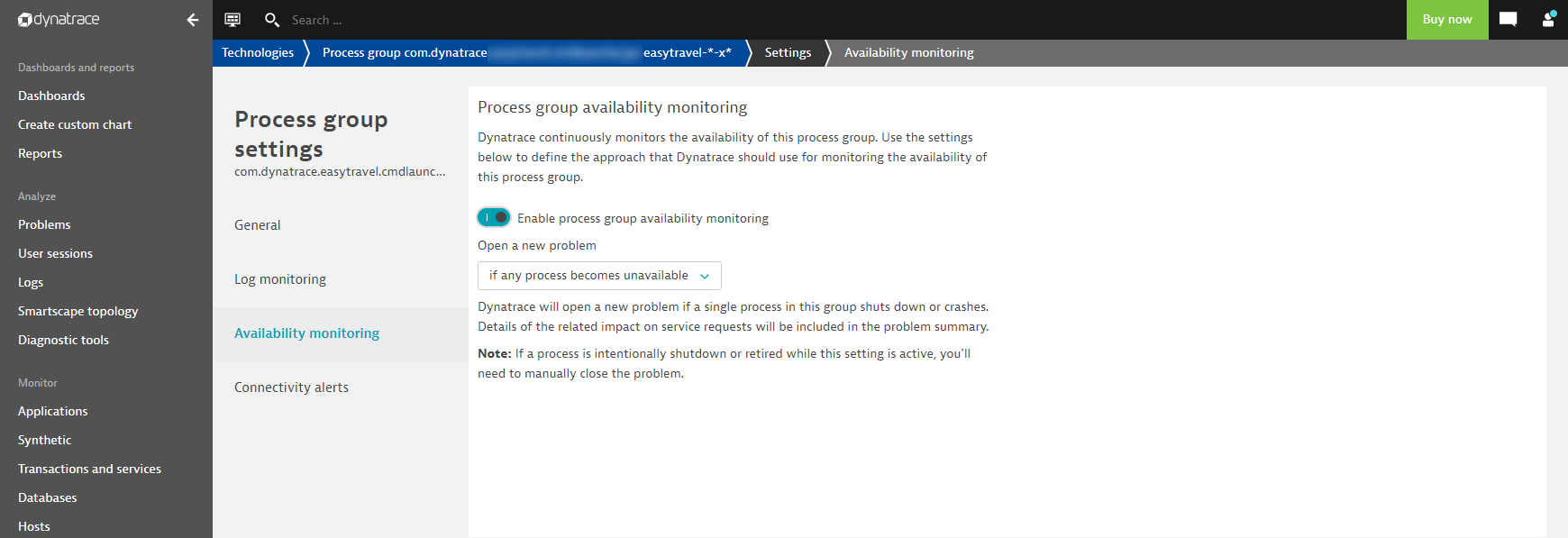
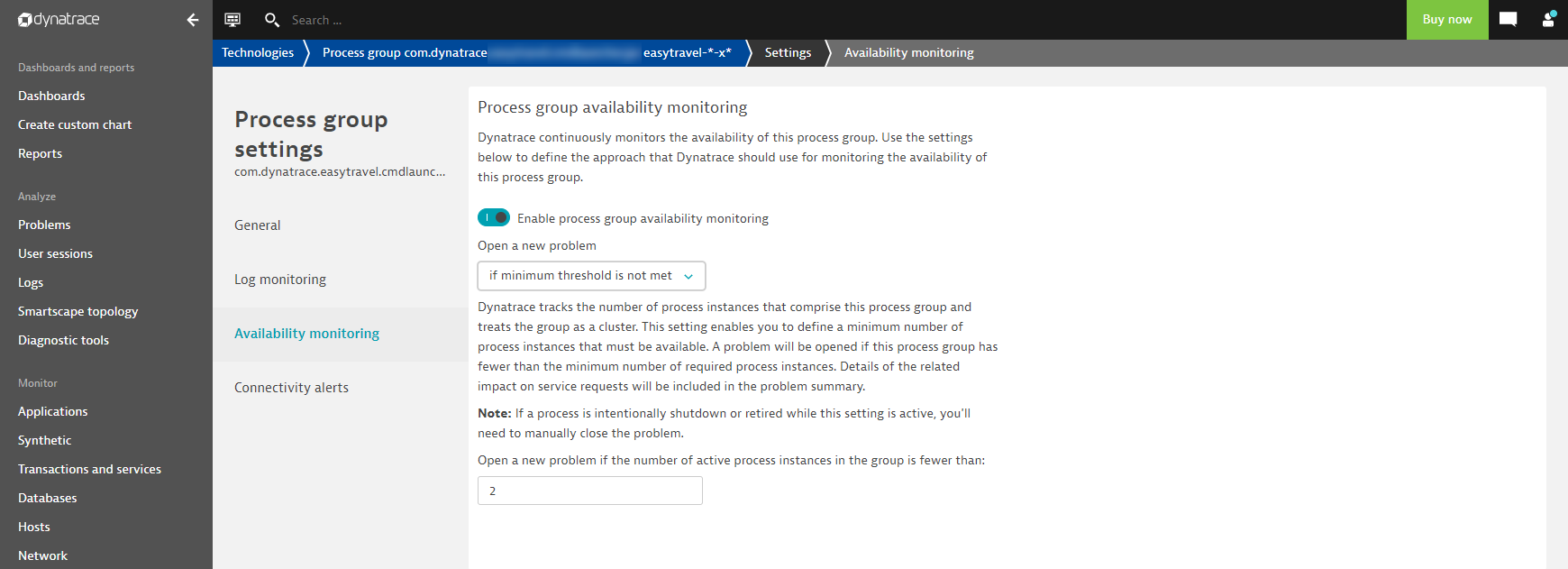
Raise an alert when a minimum number of processes are no longer available in a selected process group
This option triggers an availability event when a user-defined threshold for the minimum number of running processes within a selected process group isn’t met.
In the example below, the required minimum number of running processes is set to 2. This means that whenever this process group has fewer than two running processes, Dynatrace will trigger an availability-level event for the process group.
Summary
As Dynatrace Davis is capable of automatically detecting process and host availability issues related to large-scale incidents, default trigger events for process availability are no longer necessary.
The new default setting at the process-group level reduces event spam for non-stable process groups (for example, Tanium Client) while also allowing you to opt into trigger events for important process groups.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum