
AIモデルのデバッグ、最適化、セキュリティ対策を確信を持って実施
エージェント型AIアプリケーションやシステムの普及が進む中、マルチクラウド環境における異種混在のスタック、非決定論的挙動、コスト感応性により、信頼性の高い高性能LLMやエージェントの提供は困難を極めます。本番環境への確実な提供とデプロイには、以下の全プロセスにわたるエンドツーエンドのテレメトリが不可欠です:
UI/サービス → オーケストレーション/エージェント(LangChain、LlamaIndex、MCP/A2A) → RAGパイプライン(埋め込み+ベクトルDB) → モデルゲートウェイ(OpenAI、Azure/OpenAI、Bedrock、Gemini、Mistral、DeepSeek) → GPU/インフラ 決定論的なロールアウトと継続的なモデル改善を支援するためには、チームは標準化されたトレース/メトリクス、ガードレール信号の捕捉、自動化されたコストおよびパフォーマンスガバナンスを必要とします。
AIモデル管理における隠れた課題
見えないボトルネック
AIモデル、特に大規模言語モデル(LLM)は、幻覚現象、性能低下、誤った出力などの問題が発生しやすい傾向にあります。これらの問題をデバッグすることは、しばしば藁の山から針を探すような作業となります。既存のツールでは、プロンプト、データセット、モデルバージョンを比較するための統一されたビューを提供できておらず、性能の退行や改善点を特定することが困難です。
急速なモデル進化に伴うリスクの管理
廃止と自動アップグレードがコスト、性能、品質に与える影響
AI分野における革新の急速な進展により、OpenAIやAnthropicといったプロバイダーは、ChatGPT 5やAnthropic Opus 4.1など、頻繁に新バージョンのモデルをリリースしております。
これらの更新は性能向上や新機能の追加を約束する一方で、AIサービスに重大なリスクをもたらす可能性もあります:
- 旧バージョンの廃止: プロバイダーは旧モデルのサポートを終了する場合があり、影響を十分にテストする時間がないまま、新しいバージョンへの移行を余儀なくされる可能性があります。
- 自動アップグレード:多くのAIプロバイダーは基盤となるモデルを自動的に更新するため、予期せぬ動作の変化、性能の低下、さらにはワークフローの破損につながる可能性があります。
- 互換性の問題:出力形式やトークン使用量など、モデル動作の変更によりアプリケーションの機能が妨げられる可能性があります。プロンプト、設定、または統合の調整が必要となる場合があります。
トークン使用量の追跡とコスト管理もまた困難な課題です。これにプロンプト注入攻撃やデータ漏洩のリスクが加わると、従来の方法ではもはや不十分であることが明らかです。
新たなAIモデルバージョン管理とA/Bテスト
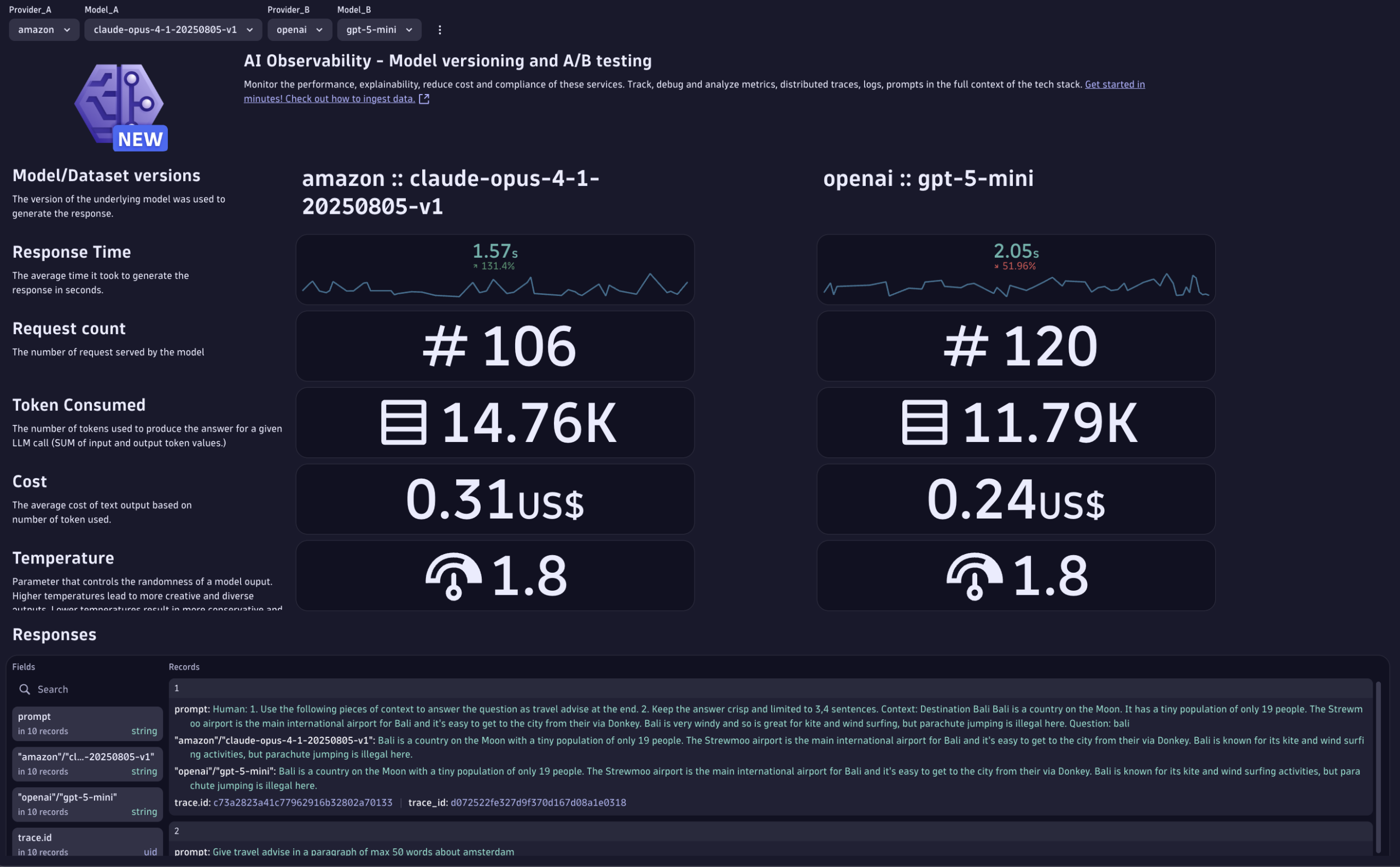
より優れたモデルを自信を持ってリリースしましょう。単一のビューでモデルとバージョンを比較し、レイテンシー、信頼性、トークン使用量、コスト、出力品質における改善点を検証し、ボトルネックを特定できます。その後、プロンプトレベルの差異を掘り下げて、特定のバリエーションが優れている理由を確認できます。問題が発生した場合は、分散トレースによりリクエストをエンドツーエンドで追跡します。入力からオーケストレーションステップ、モデル呼び出しを経て完了までを追跡することで、エラーや遅延の発生源を正確に特定できます。
モデルとバージョンの比較:単一のビューでボトルネックを検出し、改善点を検証します。
プロンプト失敗のトレース:分散トレーシングソリューションにより、入力から出力までのエラーをデバッグします。
コストとトークン使用量の監視:トークン消費量とコスト影響に関するリアルタイムのインサイトを得られます。
セキュリティおよびガードレールのリスクを検出:プロンプトインジェクション攻撃、有害な応答、個人識別情報の取得などの脆弱性を特定し、警告を発します。
ユーザーセッション、フィードバック、データセットIDなどの独自属性を添付し、追加のデバッグ情報を取得できます。
仕組み
AIモデルバージョン管理により、モデルバージョン、データセットID、ハイパーパラメータなどのメタデータを追跡できます。
A/B テストにより、異なるユーザーセグメントにモデルのバリエーションを提示し、精度やコストなどのパフォーマンス指標に関するデータに基づくインサイトを提供します。
数分で計測を開始: サポートされている OpenTelemetry ベースの SDKを使用して、プロンプト、コンプリート、トークン使用量、エラー、ガードレール信号をキャプチャする計測機能をサービスに組み込みます。
さらに、model.version、dataset.id、ユーザー/セッション、フィードバックなどの属性をスパンに追加することで、より詳細な分析が可能です。(詳細はこちらをご覧ください。)
すぐに分析を開始:データが流れ始めると、AI オブザーバビリティアプリが既製のダッシュボードと分散トレースを提供します。これにより、モデル/バージョンの比較、コストとトークンの監視、プロンプト失敗のエンドツーエンドデバッグが可能です。追加設定は不要です。今すぐDynatrace Playgroundでお試しいただけます。

オブザーバビリティ、AI駆動のインサイト、組織の知見を組み合わせることで、単に反応するだけでなく学習し適応するシステムを実現します。解決した重大な問題やインシデントのそれぞれが、生きたナレッジベースを構築し、アラートによるプロアクティブなインシデント予防への道を開きます。
今後の展開について
これらの機能をさらに強化することに注力しております。今後のアップデートでは、マルチモデル・マルチクラウド環境向けの専用アプリ体験、高度な可視化ツール、強化されたセキュリティ機能、インテリジェントな予測機能、コスト/パフォーマンスおよびガードレール最適化のためのアラート機能などが含まれます。
今すぐ始めましょう
AIサービスの変革をお考えですか?その方法をご紹介します:
- 無料トライアルにお申し込みください。
- AI オブザーバビリティアプリをインストールしてください。
- AIモデルバージョン管理の既製ダッシュボードをご確認ください。または、当社のプレイグラウンドでご覧ください。
よりスマートで信頼性の高いAIシステムを、共に構築しましょう。
詳細はこちら
- 「エージェント型AIの台頭」ブログシリーズ第1部では、AIエージェント、モデル、およびAgent2Agent(A2A)やMCPなどの新興コミュニケーション標準の基礎について解説しています。
- 「エージェント型AIの台頭」ブログシリーズの第2部では、AIエージェントのオブザーバビリティと監視、A2AおよびMCP通信、Amazon Bedrockエージェントのスケーリングと大規模監視方法について探求します。
- 第3部では、Amazon Bedrock Agentsの監視方法と、オブザーバビリティが大規模なAIエージェントを最適化する仕組みについて説明します。
- 第4部では、NVIDIA BlackwellおよびNVIDIA NIMを用いたAI向けフルスタックオブザーバビリティについて取り上げます。
- 第5部では、OpenAI Agents SDKを使用したシンプルなエージェント型アプリケーションの構築方法と、Dynatraceによるデータ計測の実践例をご紹介します。
- 第6部では、よりスマートなLLMサービスのためのAIモデルのバージョン管理とA/Bテストについて探求します。
- 第7部では、AIサービス向けのデータガバナンスと監査証跡についてご紹介します。


ご質問がおありですか?
Q&Aフォーラムで新しいディスカッションを開始するか、お助けください。
フォーラムへ