
友人が新しいレストランで待ち合わせを提案してきたと想像してください。その場所がわからない場合、ただ外に出て歩き出し、運任せにレストランを見つけようとするでしょうか?おそらく、モバイル端末でナビゲーションアプリを開き、住所を検索してルートを設定するでしょう。ITスタックにおける重大なインシデントも同様です。ログやトレース、警告の暗がりを手探りで進み、通行人に助けを求めながら、次々と推測を繰り返す必要はありません。 ここにDynatraceの真価があります。最も関連性の高い情報を厳選し、エンジニアを次の最適なステップへ導き、アラートから解決まで確かな道筋を示します。
Dynatraceでは、根本原因分析の 分野で 長年先導してまいりました 。異常を自動検知し、その原因を特定するのです。こうしたAIを活用した洞察が、Dynatraceが複雑に絡み合った問題を通じてエンジニアを導く知的な基盤を形成し、混乱したデータの都市景観を、焦点を絞った修復の旅へと変えるのです。
本ブログ記事では、架空のSREであるオマールが、Dynatrace OpenTelemetryデモアプリケーション「Astroshop」で重大な障害を解決する過程を追います。オマールは開発者のソフィーと協力し、障害の解決にあたります。
Dynatraceは、あらゆるチームに対し、インシデントライフサイクルの全段階を、迅速かつ正確に、確信を持って導きます。そのプロセスは以下の通りです:
- 問題診断– Dynatraceは 障害を自動的に単一の相関問題としてパッケージ化します。
- アラート通知– オマール様は 、作業環境内で、根本原因分析(RCA)、責任範囲、ディープリンクが既に設定された、詳細で実用的な通知を受け取ります。
- トリアージ– 問題詳細ページは 「トリアージおよび修復の司令センター」として機能し、影響範囲、影響を受けるユーザー、優先的に修復すべき課題を表示します。
- 引き継ぎ– 問題コンテキスト内から 、RCAの知見、ログ、ディープリンクが事前入力されたガイド付きJiraチケットをワンクリックで作成できます。
- ガイデッド調査– 問題 ビューには、問題のコンテキストに関連するすべてのインシデントが一覧表示されます。
- 修復–ライブデバッガーとリアルタイムメトリクスを活用し、ソフィーが問題を修正すると、修正が成功したことが即座に確認できます。
- 将来に向けた強化と学習– 修正内容は自動的にトラブルシューティングガイドに文書化され、今日のインシデントが明日の知見へと昇華されます。
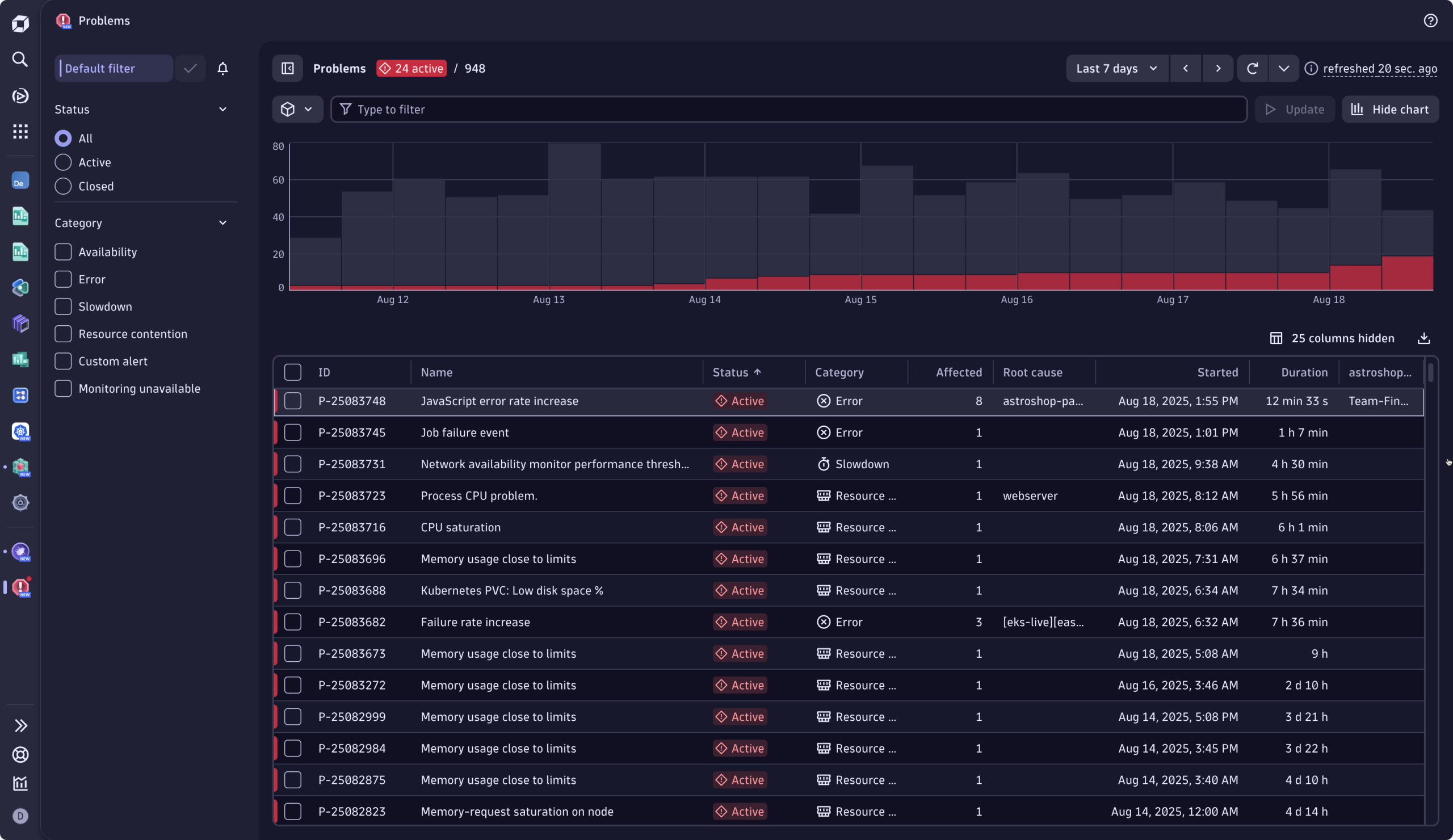
問題の診断:複数のインシデントと信号の流れが、一つのまとまった問題に結びつく
Astroshopオンラインストアでは最近、顧客がAmerican Expressクレジットカードで決済を試みた際にエラーが発生するようになりました。エラーメッセージにより、ユーザーは購入を完了できなくなっています。Dynatraceの季節ベースライン機能はこのサービス健全性の問題を検知し、 関連するすべてのイベント を単一の問題に クラスタリングすることでアラートのノイズを低減。さらに、影響を受けたユーザー、インフラストラクチャ、SLOに関連するすべてのテレメトリ(ログ、メトリクス、トレース)を紐付けました。
Kubernetesラベルに基づくサービスの所有権を判定することで、問題は自動的に適切なチーム(オマール氏のSREチーム)にルーティングされます。
コンテキストに応じたアラート
一方、オンコール担当のSREであるオマールは、自身とチームが作業する環境であるSlackに直接通知を受け取りました。通知には「決済サービスの障害発生率増加」と表示されています。
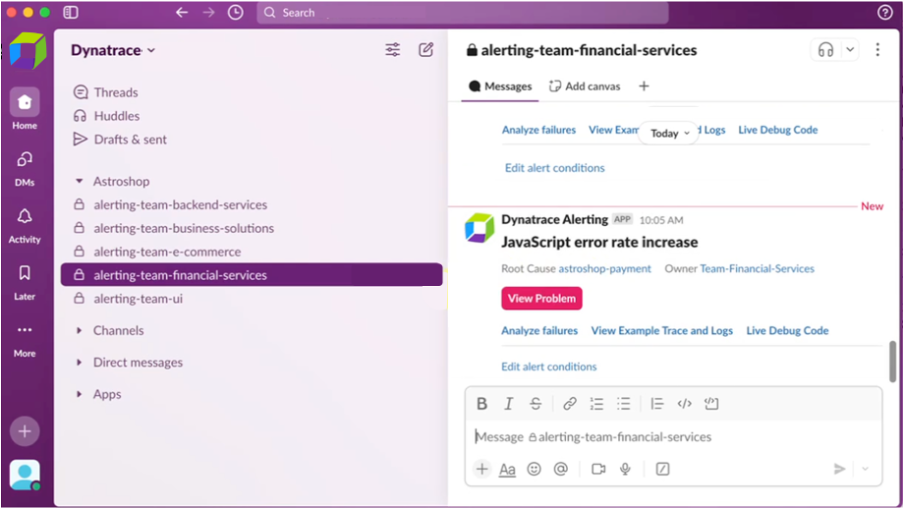
もちろん、このような通知は、チームの作業環境や通知希望先に応じて、JIRA、ServiceNow、その他のツールにも表示されます。通知には完全なコンテキストへのリンクが含まれており、オマールはすぐに修復作業を開始できます。通知には根本原因とサービス所有者が明記されています。また、直接アクセス可能な推奨 ドリルダウン機能も提供されるため、別のツールを開く必要がありません。オマールはコンテキストを調査し、インシデントに対応することから作業を開始します。
トリアージ:問題の内容、担当者、深刻度を把握する
Slack通知内の「 問題を閲覧」ボタンを選択すると、オマールは関連する問題ページに移動します。ここは彼のトリアージと修復の司令塔となります。
オマールは一目で以下の質問に答えられます:この問題の深刻度は?影響を受ける対象と範囲は?問題が存在する期間は?そして、最善の対応策は何か?
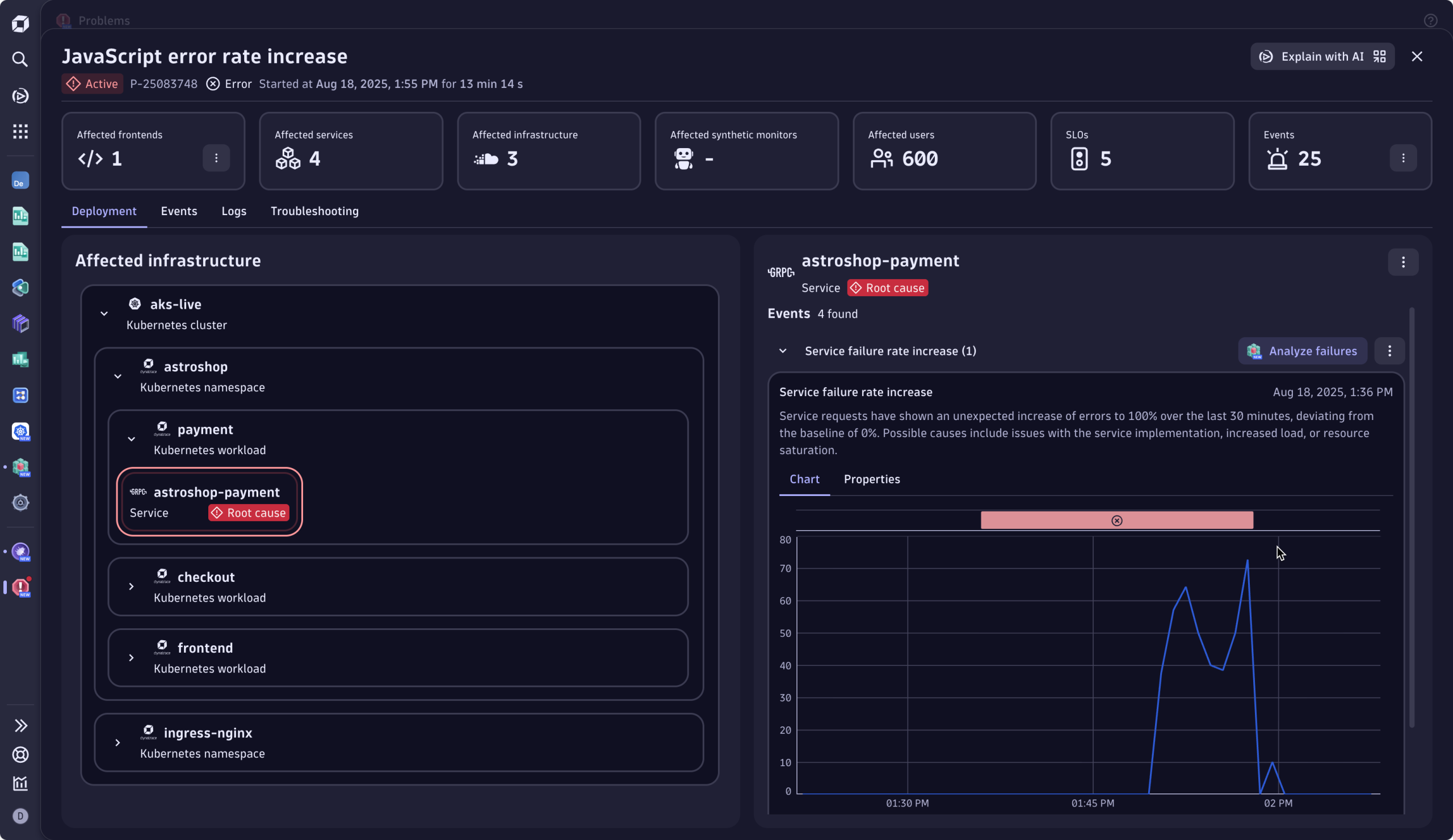
最初の質問:深刻度はどの程度か、影響対象は?
問題インシデントのヘッダーから、オマールは即座に収益を阻害する問題であることを把握します:600 人のユーザーが購入のチェックアウトに失敗しました。さらに、1つのフロントエンドと6つのサービスが影響を受けており、このエラーにより5つのSLOが危険にさらされていることも確認できます。タイルをクリックすると、エンジニアは詳細情報を掘り下げることができ、「次に確認すべき事項」が明確に示されたアクションが提示されます。
エラーの内容は不明ながら、オマールはこの問題が 深刻で 優先対応が必要だと 理解します。対応前に、通常状態との比較で現状を把握したいと考え、次の質問へと進みます。
第二の疑問:この状態はどのくらい続いているのか? チェックアウトの失敗件数は?
イベントチャートが明確に示しています: このインシデントは30分間継続中です。オマールは時間の経過に伴うイベントの推移を正確に把握します。ベースラインを認識したメトリクスにより、通常の変動と真の異常を区別できます。ここでは現在の挙動が通常から逸脱しており、エラーが大幅に増加しています。これは明らかにベースラインから外れており、同じ時間帯にエラーが発生しないことが想定される基準値から乖離しています。
つまり、過去30分間、通常よりもはるかに多くのお客様が購入を完了できませんでした。問題は現在も継続中です。瞬時に 、インシデントの深刻さを確認できました。
第三の問い:何が故障しているのか?
左側のデプロイメントビューでは 、コンポーネントおよびクラスターごとに障害の原因を視覚的に分解しています。根本原因分析エンジンは 、関連するすべての事象と要因を相関分析し、問題の発生箇所を正確に特定しました。原因は「決済サービス」に関連するKubernetesワークロードです。
第四の質問:誰が修正できるか?
これは容易です。影響を受けたインフラストラクチャ内で明確にラベル付けされた根本原因が、責任の所在を明らかにしています。オマールは、ファイナンスチームの開発者であるソフィーが、障害を起こしているサービスの責任者であることを確認しました。
インシデントを迅速に把握したオマールは、自信を持って適切な担当者に問題を引継ぐことができます。
引き継ぎ:責任チームへの手間いらずで正確な引き継ぎ
オマールはDynatrace内の問題詳細ページから直接引き継ぎを開始します。ワンクリックで、関連情報を全て含むJira課題を作成します。
Jiraチケットには問題識別子が自動的に入力されるため、ツールを切り替えることなく影響を受けるサービスやコンポーネントを容易に把握できます。無駄なエスカレーションの往復はなく、最小限の手間で明確かつ確実な業務分担が実現します。
担当開発者であるソフィーはJira通知を受信し、チケットを開くと必要な情報がすべて揃っています:問題ビュー、障害分析、ライブデバッガーへの直接リンク付き簡潔な要約です。
問題モードでのガイド付き調査
最適な次善策を案内されながら 、ソフィーはサービスアプリを使用して障害をさらに分析することを選択します。これにより、サービスアプリ内に表示される視覚的補助レイヤーである「問題モード」が開きます。 このモードは インシデントの影響範囲にスコープされ、以下の基準に基づいてすべてのログ、トレース、警告を事前にフィルタリングします :
- インシデントの範囲
- 関連するサービスとインフラストラクチャ
- イベントの重大度とユーザーへの影響
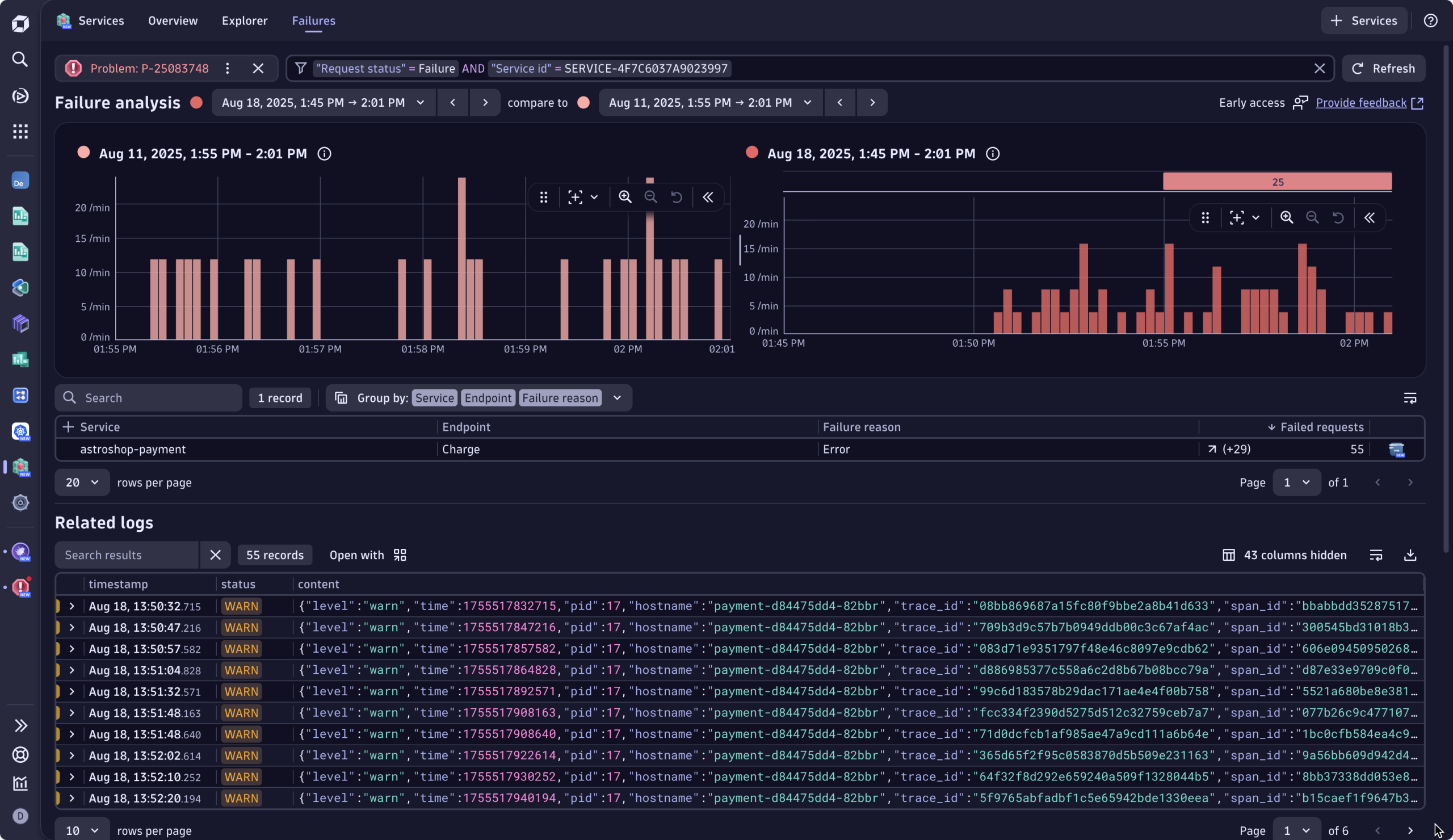
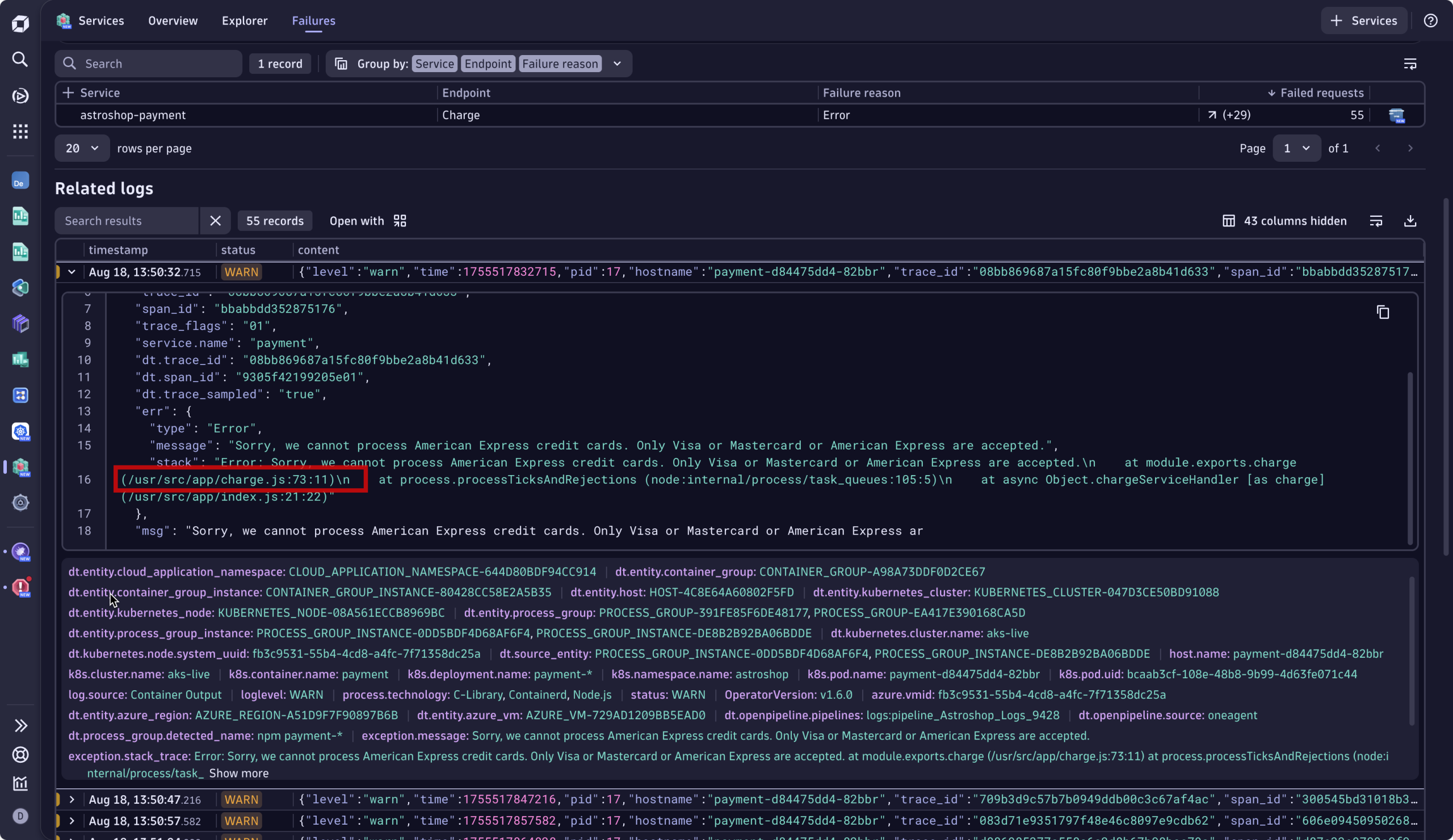
このビューは自動的に重要な情報を優先表示し、単に何が壊れたかではなく、障害が発生した理由を説明するシグナルを強調します。文脈のない古い無関係なログと格闘する代わりに、ソフィーは チェックアウトエラーの正確な時間帯に紐づく エラーログとテレメトリを確認できます。障害に関連するエラーログ(正確なエラーメッセージを含む)に直接アクセスします。ソフィーはこれがコードのバグ、具体的には73行目のJavaScriptエラーであることを即座に把握します。
修復:迅速な修正と即時検証
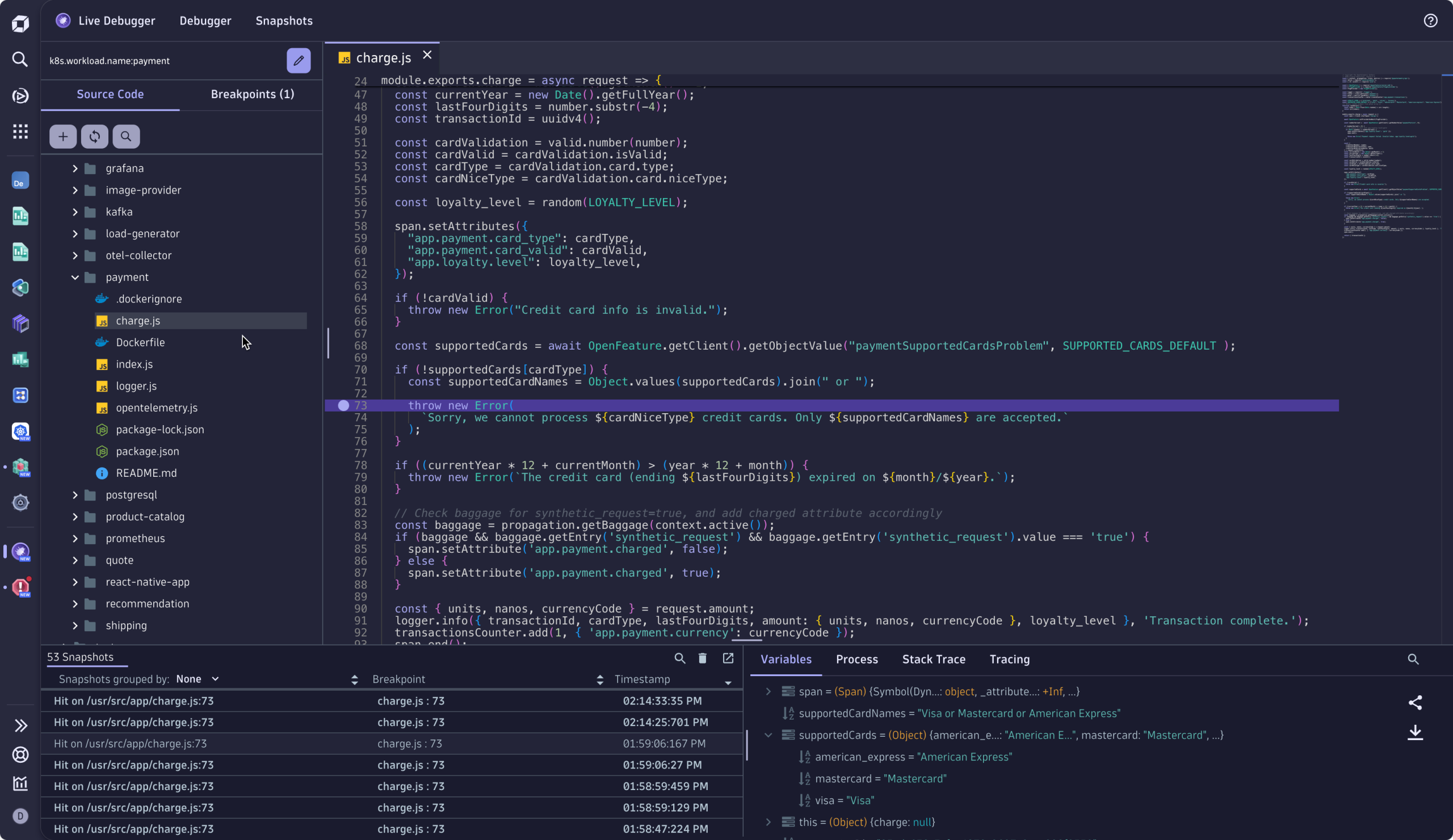
ソフィーは障害を修正するのに十分なコンテキストを把握しています。Dynatrace Live Debuggerを開き 、エラーログが発生した箇所まで移動し、エラーの発生源と特定した22行目に非中断ブレークポイントを設定します。Live Debugger がスナップショットをキャプチャすると、ソフィーは 原因を即座に特定しました。 文字の不一致(American-ExpressとAmerican_Express)がチェックアウトサービスの異常を招いていたのです。
ソフィーは問題を修正し、修正をデプロイします。数分後、ビジネス指標ダッシュボードを確認すると、修正措置が有効であったことをリアルタイムで検証できました。チェックアウトの失敗が解消され、収益が再び流れ始めていることが確認できたのです。
今後の強化と学習のために問題を文書化する
修正がデプロイされると、ソフィーとオマールは問題の詳細にある「トラブルシューティング」 に移動します。2 人は、エラーの詳細と原因、つまりAmerican-ExpressとAmerican_Express のキーの不一致、およびその解決方法を一緒に書き留めます。ソフィーは、デイヴィス® AI によって自動的に事前入力されたインシデントの詳細の横に、検証に使用したダッシュボードへのリンクを追加します。
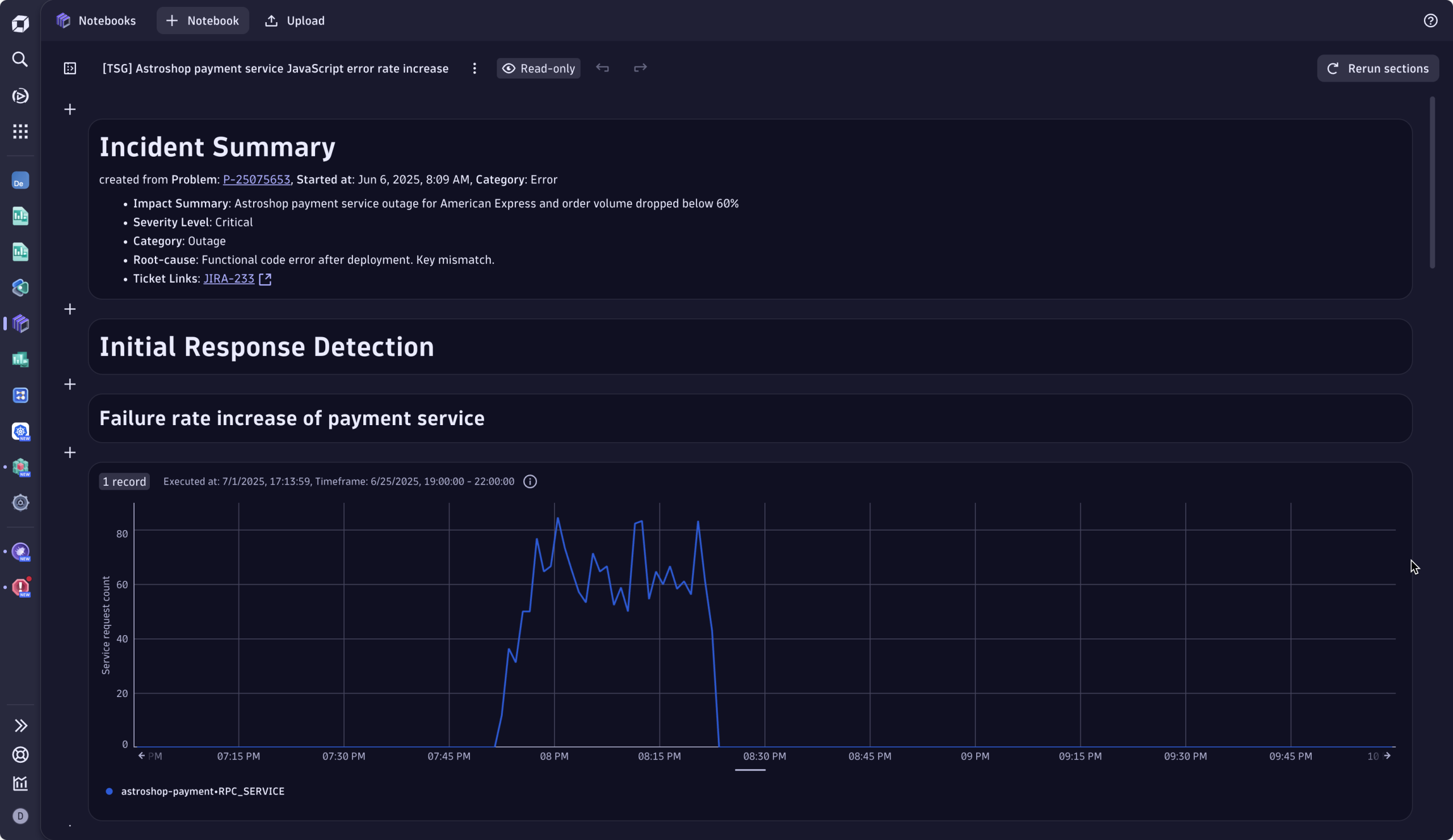
これが完了すると、Dynatrace は自動的に
- インシデントのメタデータとテレメトリをインデックス化
- RCA にリンクされたインシデントの詳細情報を事前入力
- グラフベースの AI およびベクトル検索を使用して、類似のインシデントにリンクします。
数週間または数か月後、同様のチェックアウトの急増が発生した場合、Dynatrace の修復インテリジェンスが自動的に関連するトラブルシューティングガイドを表示し、必要なコンテキストと修復のガイダンスを提供します。
将来、一から調査を始める必要がなく、繰り返し調査を減らすことで問題解決を加速するだけでなく、すべての修正をチームの知恵に変える、生きたナレッジベースを活用することができます。
本日よりDynatraceの問題解決プロセスをお試しください
Dynatraceは問題の検知だけでなく、通知から解決までチームを冷静かつ確実に導きます。繰り返しの緊急対策会議をなくし、今すぐご自身でお試しください:


お探しの情報が見つかりませんか?
Q&Aフォーラムで新しいディスカッションを開始するか、ご支援をお求めください。
フォーラムへ