
エージェント型AIアプリケーションが普及するにつれ、課題は、あらゆる接続機能を組み込んだマルチエージェントシステムを迅速に構築する方法となります。本シリーズ「エージェント型AIの台頭」の第5回となる本稿では、OpenAI Agents SDKを使用したシンプルなエージェント型アプリケーションの構築方法と、Dynatraceによるデータ計測手法についてご説明いたします。
最近、OpenAIはOpenAI Agents Python SDKを使用して構築されたカスタマーサービスエージェントのデモを公開し、動作中のマルチエージェントシステムの例を紹介しました。OpenAI Agents SDKを活用すれば、エージェント、ハンドオフ、ガードレール、ツール(組み込みおよびカスタム)、組み込みトレーシングの支援により、エージェント型AIアプリケーションを構築できます。これらの機能は、DynatraceのCTOであるベルント・グライフェネダー氏が初めて提唱した、スケーラブルで信頼性の高い自動化の基盤となる「知識、推論、実行」という中核パターンを支えます。
本ブログ記事では、OpenAI Agents SDK ベースのエージェント型アプリケーションを構築し、Dynatrace の AI 搭載オブザーバビリティでエージェントとアプリケーションを計測する方法を解説します。Dynatrace により、エージェントの実行状況、ツールの使用状況、プロンプトフローを最初のリクエストから最終応答まで可視化でき、迅速な根本原因分析とトラブルシューティングが可能となります。
Azure AI Foundry上のAzure OpenAIを活用したOpenAI Agents SDKおよびエージェントフレームワークの機能を示すため、前述のOpenAIカスタマーサービスエージェントデモを参考にし、当社のユースケースに合わせて修正したマルチエージェントソリューションを構築いたしました。
当社のサンプルエージェント型AIアプリケーションについて
当社のマルチエージェントシステムは、ユーザーが様々なトピックやコンテンツについて調査、要約、翻訳を行うことを可能にします。このシステムは4つのエージェントで構成されています:
- ウェルカムエージェント:ユーザーと対話し、Azure OpenAIを活用してプロンプトを分析し、意図を特定した上で、適切なエージェントに処理を開始するよう引き継ぎます。
- リサーチャーエージェント:ウェブを検索し、OpenAIを使用して結果を分析します。
- サマライザー エージェント:Anthropic Claude を使用して、検索結果、テキスト、PDF、CSV などのコンテンツを要約します。
- 翻訳エージェント:OpenAIを使用して、クエリや入力をユーザーが指定した任意の言語に翻訳します。
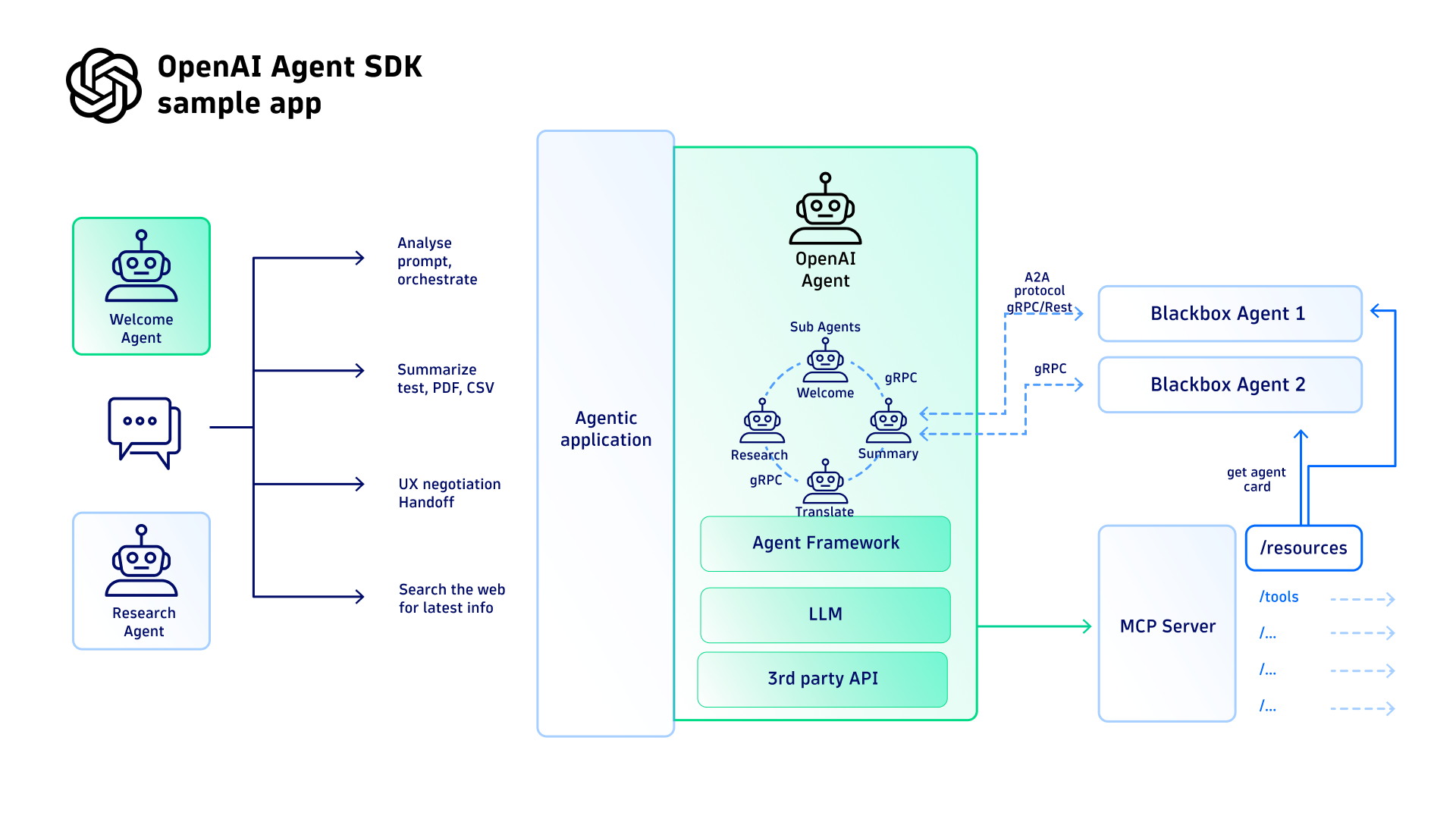
次に、マルチエージェントシステムに以下の2つの異なるシナリオを実行させたいと考えています:
- コンテキスト履歴:指定されたチャットセッションでは、セッション期間中、チャット履歴とコンテキスト全体が利用可能です。一方、個々のプロンプトは処理のために異なるエージェントに引き継がれる場合があります。
- 複合クエリ:アプリは、リサーチ、翻訳、要約、ウェルカムなど、異なる目的のために複数の異なるエージェントを調整します。これにより、ユーザーは複数のサブクエリを含む複合プロンプトを処理するためにエージェントとやり取りすることができます。
マルチエージェントフレームワークとハンドオフワークフローの理解
エージェントフレームワーク間にはいくつかの重要な相違点があります。A2Aプロトコルとは異なり、OpenAIフレームワークにはエージェント用の中央レジストリが明示的に存在しません。代わりに、OpenAIエージェントはOpenAIエージェントフレームワークによって調整される「ハンドオフ」の概念を利用します。
OpenAIフレームワークにおけるエージェントのハンドオフ
オーケストレーター主導の調整はより決定論的で構造化されたワークフローを提供しますが、エージェント間ハンドオフは適応性とモジュール性において大きな利点をもたらします。これらのハンドオフによりエージェントは動的に連携でき、複雑な多段階クエリをより柔軟に処理することが可能となります。このアプローチは分散型でスケーラブルなシステムに焦点を当て、エージェントが専門化して変化する要件にリアルタイムで対応することを可能にします。
以下に、チャットセッションにおけるエージェント間連携(コンテキストの継承を含む)およびマルチエージェントによるクエリ処理を実現する2つのシナリオ例を示します。
複合クエリとマルチエージェントワークフローにおけるユーザープロンプトの表示例
例:「マイケル・ジョーダンについて調査し、40語以内で要約した後、フランス語に翻訳してください」
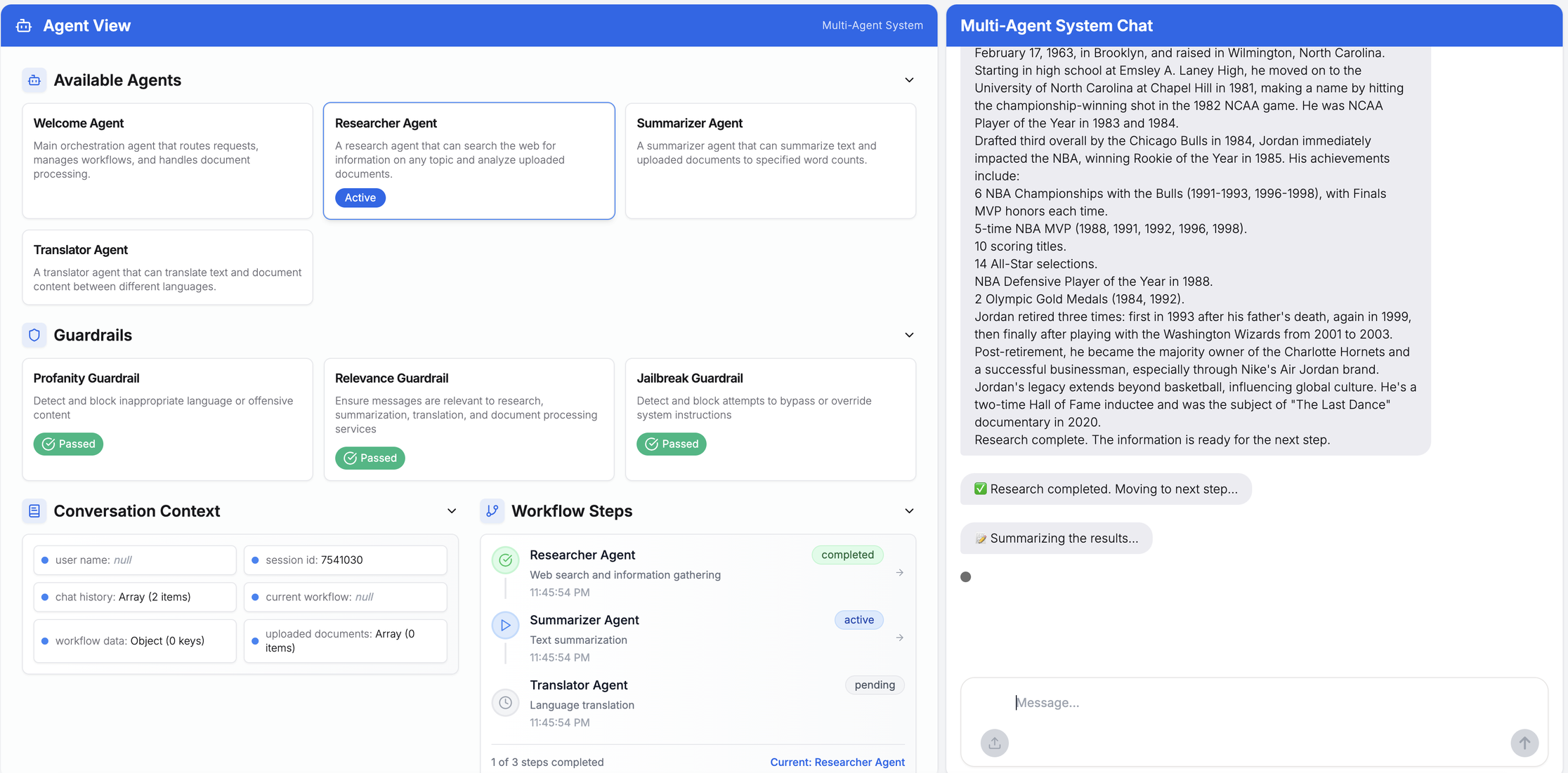
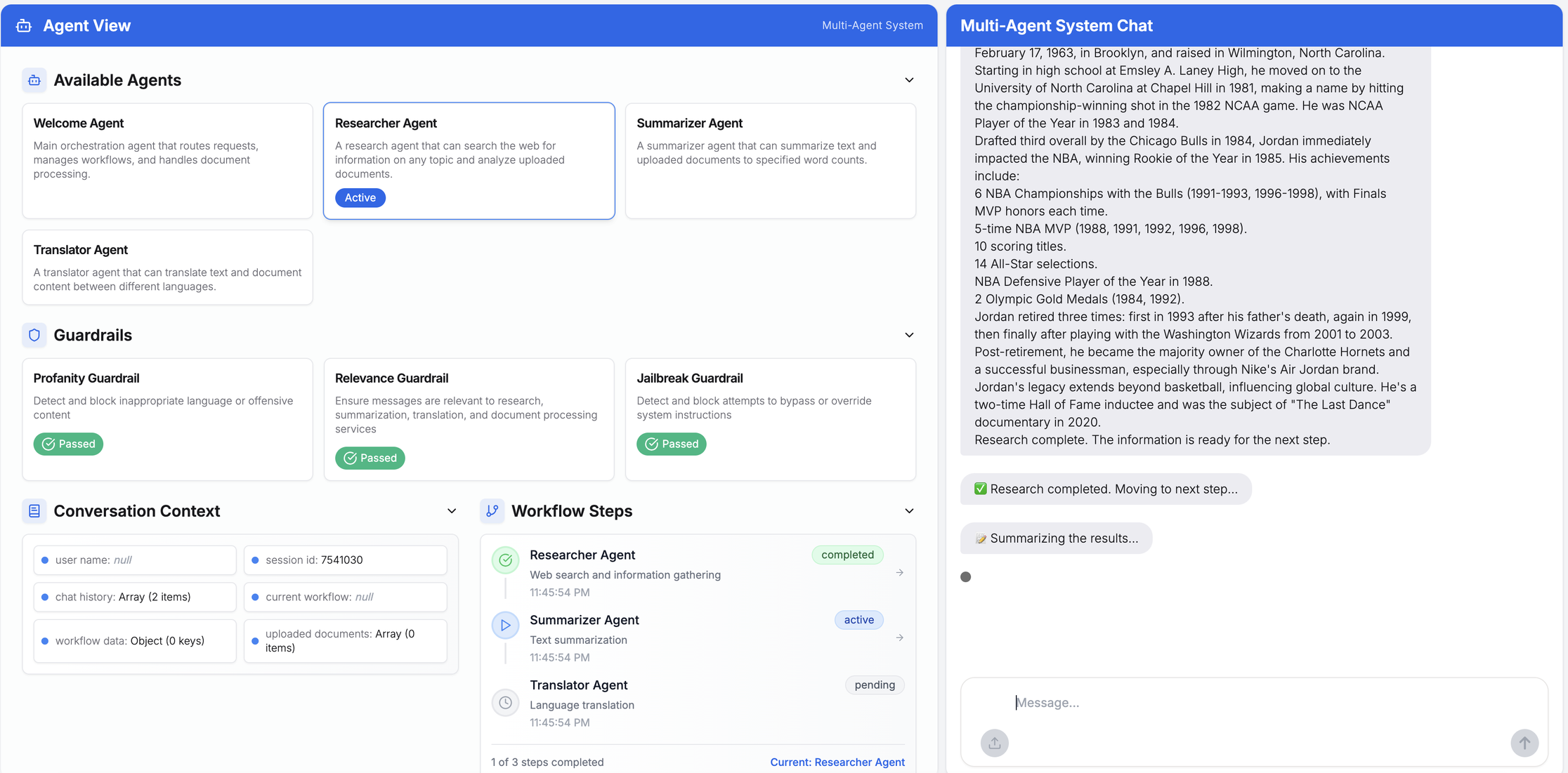
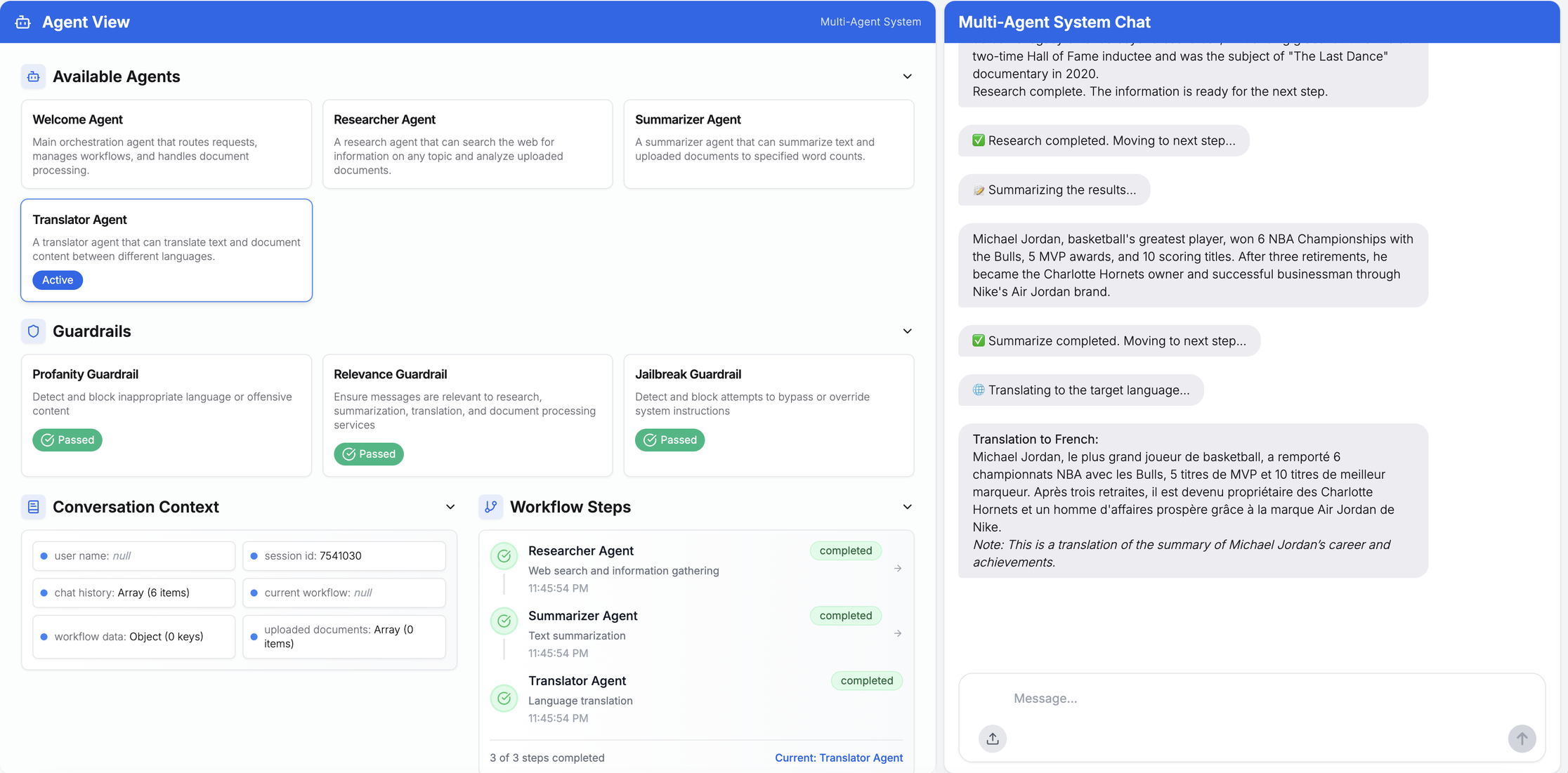
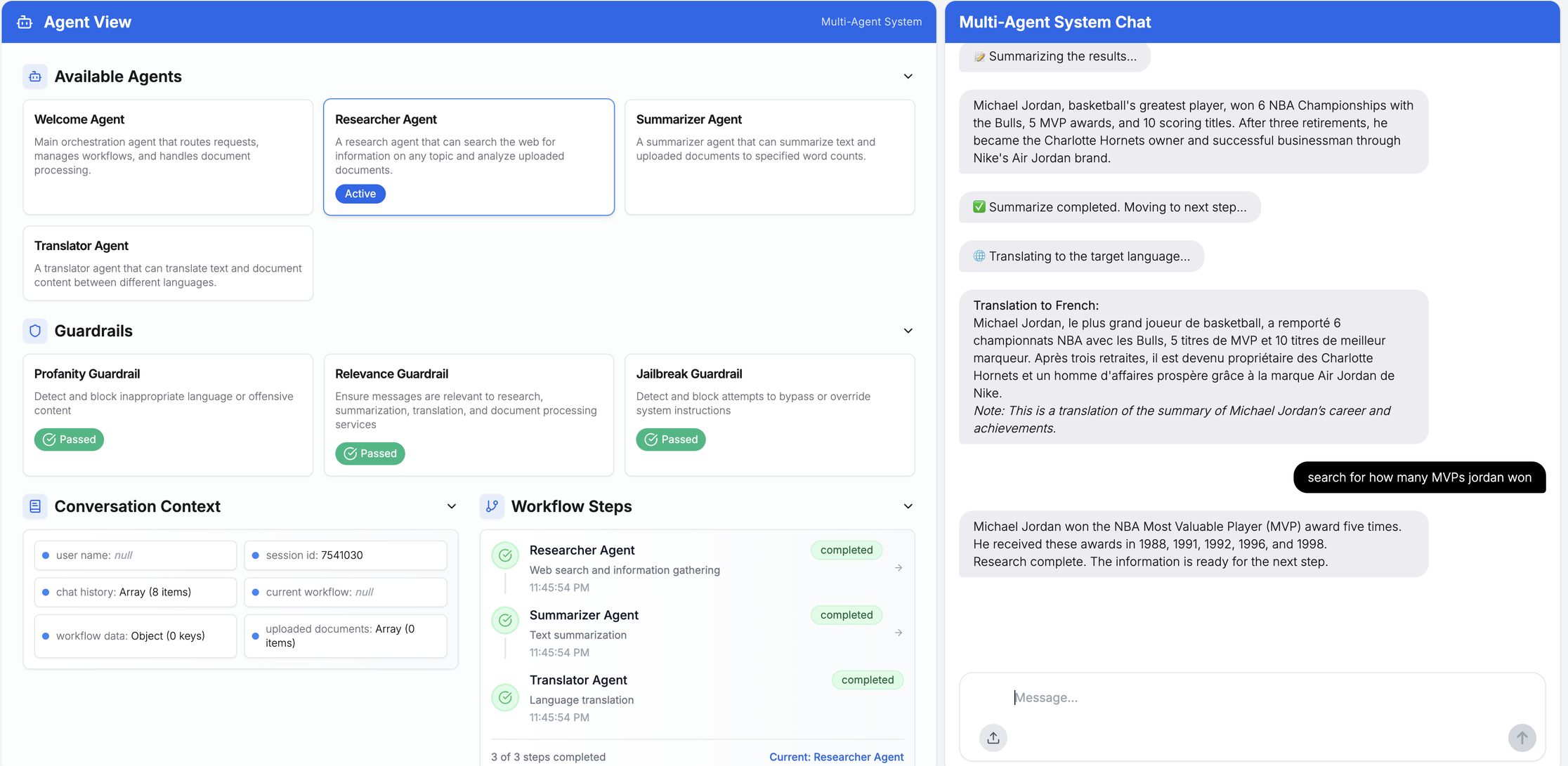
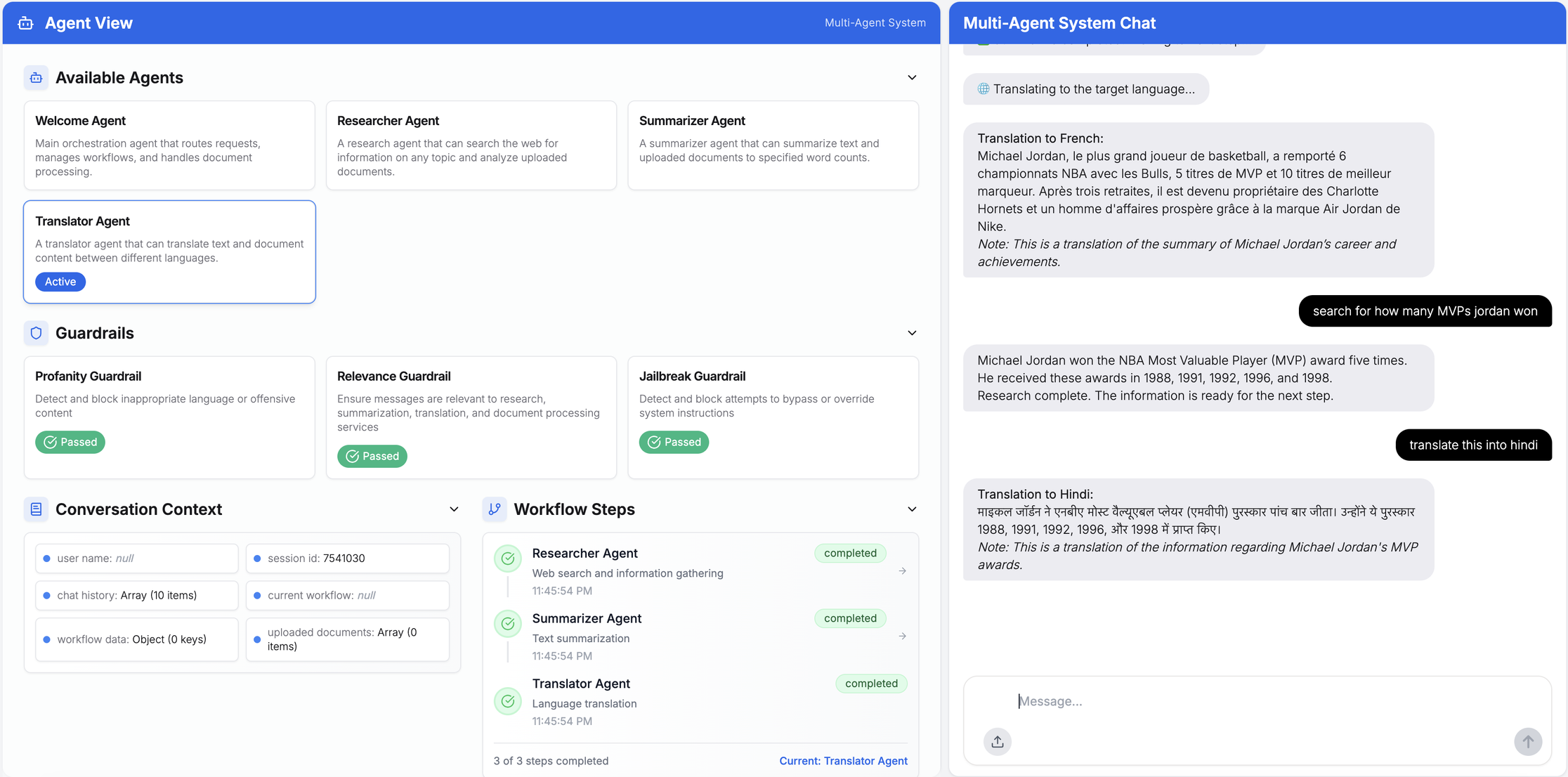
アップロードされたCSVファイルに対するマルチエージェント処理
この例では、チャットセッションにおける文脈と履歴を伴うマルチエージェントワークフロープロセスを実証するため、サンプル顧客データを含みます。
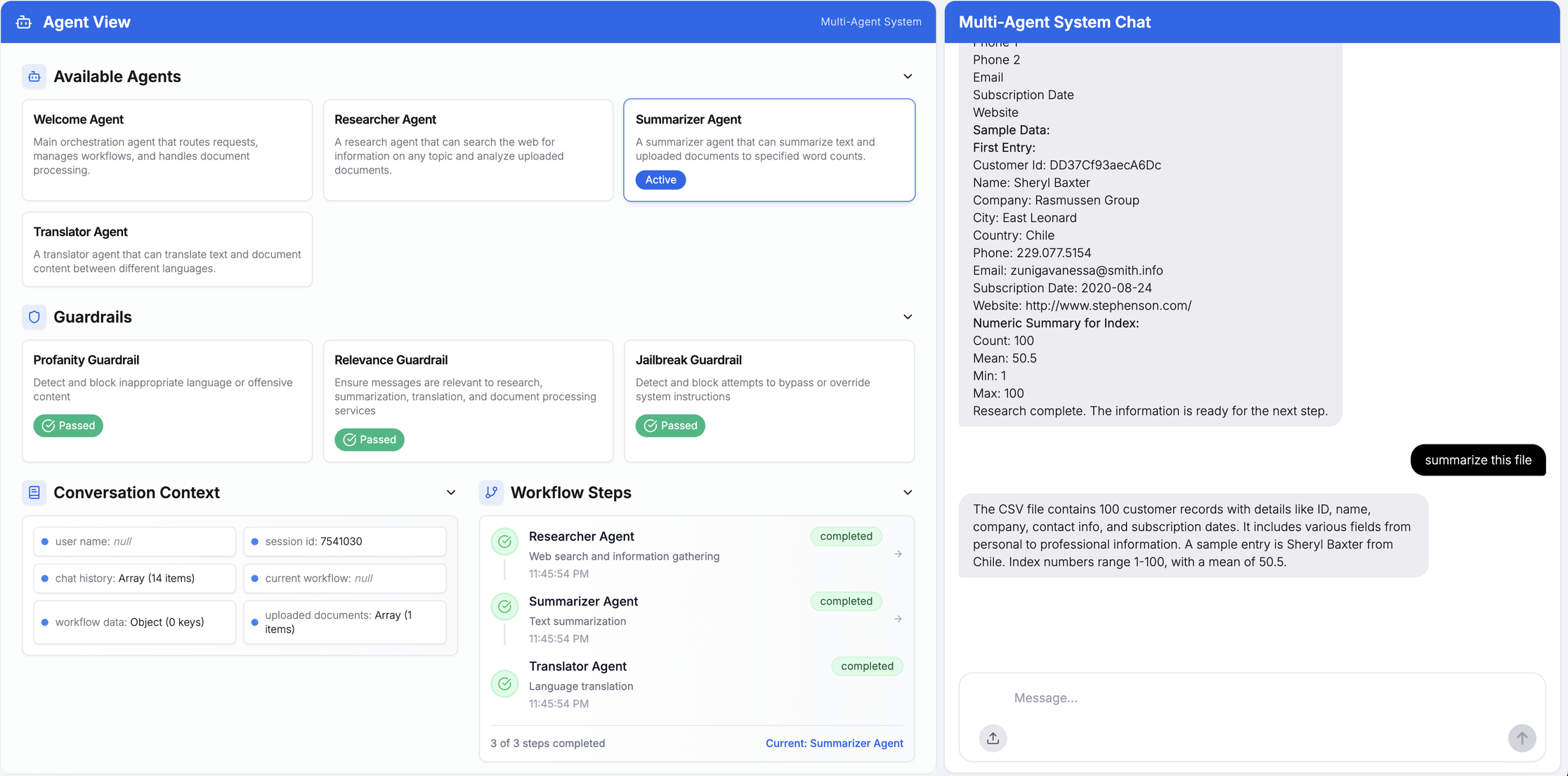
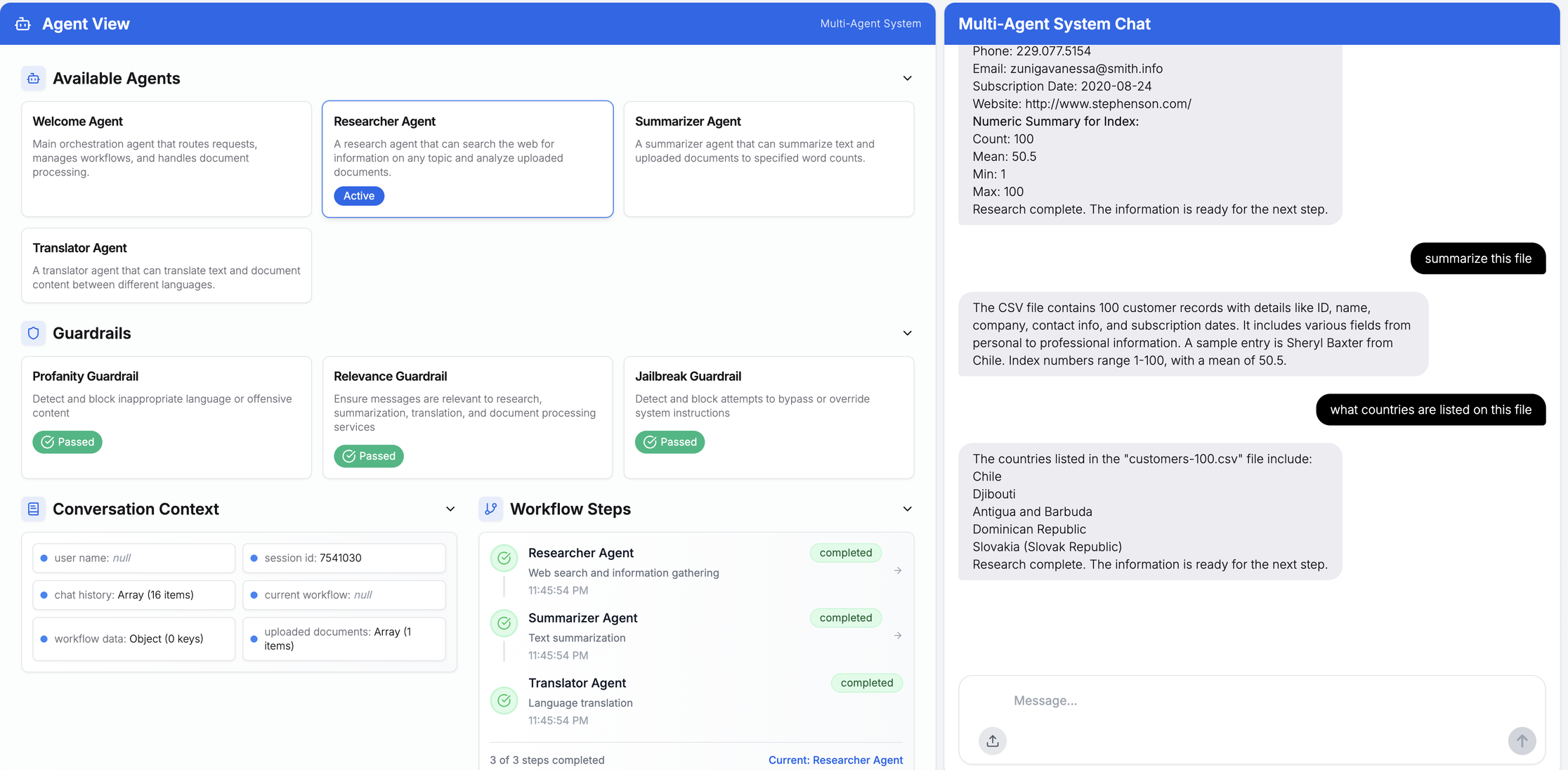
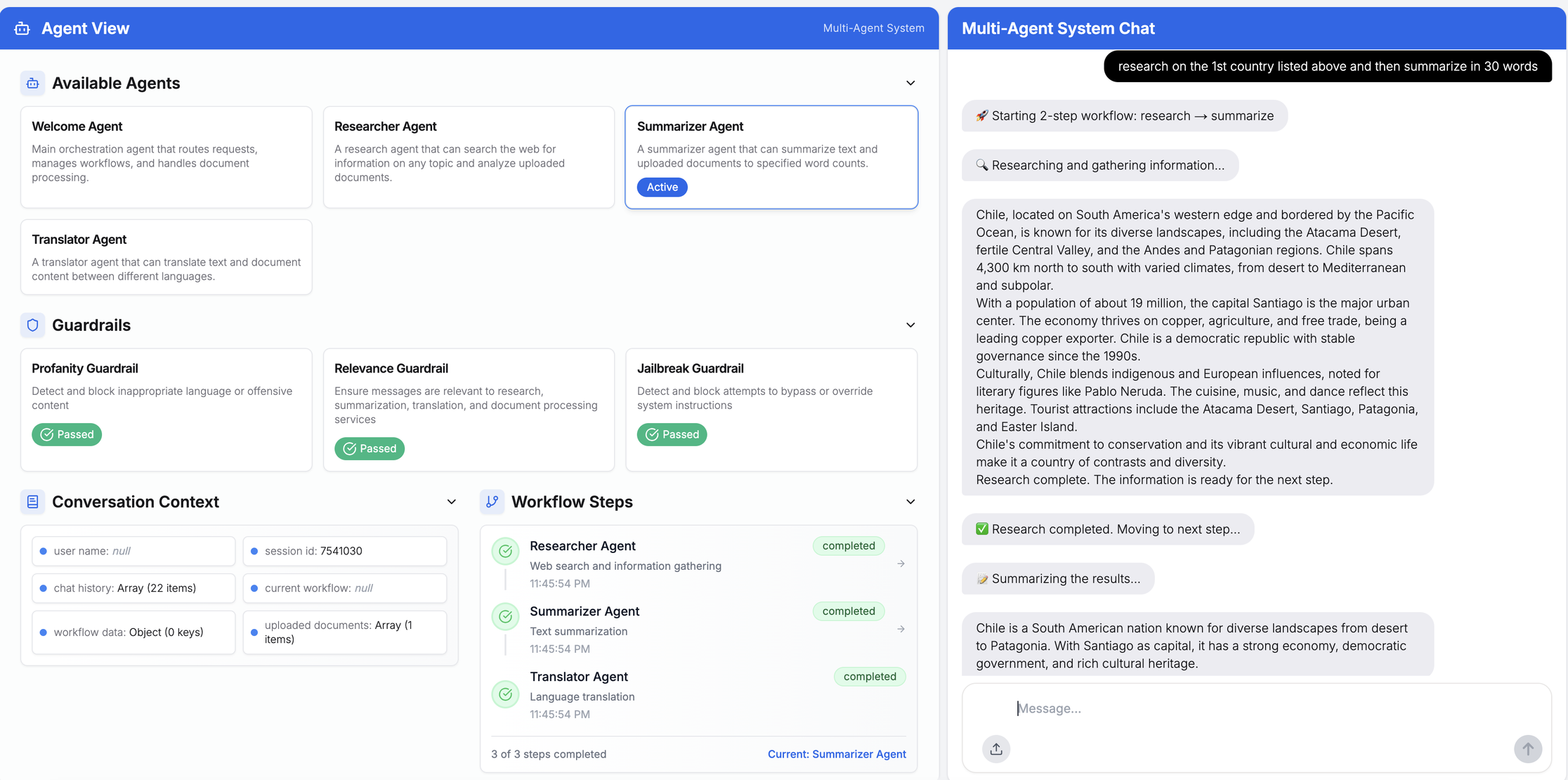
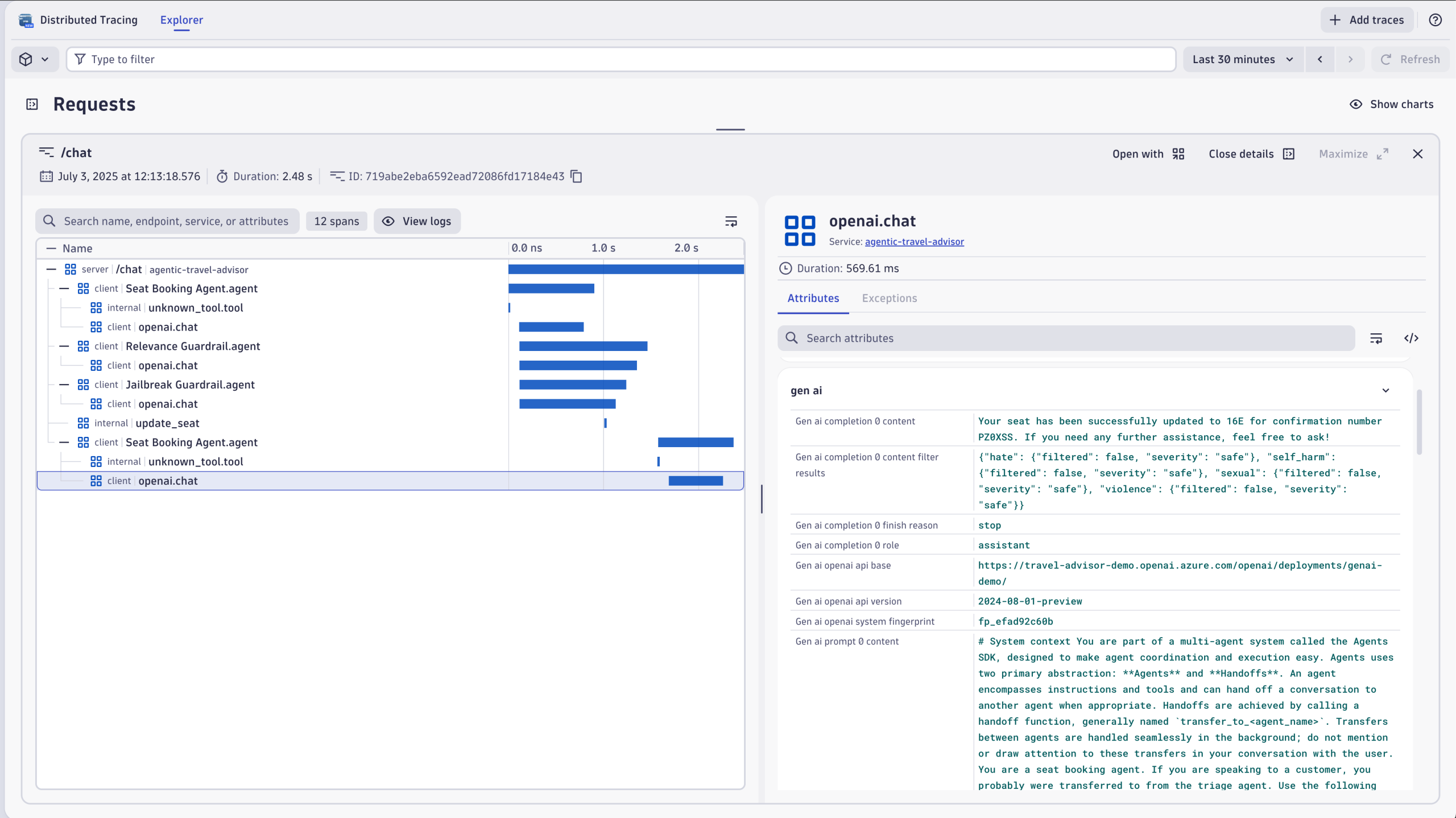
全体として、エージェント間の引き継ぎは、すべてのセッション実行において(コンテキストを保持した状態で)良好に機能しました。トレースとデバッグは、OpenTelemetry で SDK を計測し、データを Azure OpenAI 向けの Dynatrace 組み込み AI オブザーバビリティソリューションに送信することで実現できます。Azure AI Foundry プラットフォームのダッシュボードでは、特定のプロンプトに対するマルチエージェントワークフローを簡単にキャプチャできます。コード例はGitHub リポジトリでご覧いただけます。
Pythonを使用したトレース設定
Pythonを使用する場合、エージェントフレームワークとコアコンポーネントのコードを数行変更するだけでトレースを設定できます:
from traceloop.sdk import TraceloopTraceloop.init( app_name="openai-cs-agents", api_endpoint="https://wkf10640.live.dynatrace.com/api/v2/otlp", disable_batch=True, headers=headers, should_enrich_metrics=True,)
with tracer.start_as_current_span(name="update_seat", kind=trace.SpanKind.INTERNAL) as span:
context.context.confirmation_number = confirmation_number
context.context.seat_number = new_seat
assert context.context.flight_number is not None, "フライト番号が必要です"
return f"確認番号 {confirmation_number} の座席を {new_seat} に更新しました"
分散トレースで結果をすぐにご確認いただけます:
OpenAIオーケストレーション
OpenAIのフレームワーク内では、エージェントをオーケストレーションするにあたり、二つのアプローチが存在します:
- LLMに意思決定を許可する:LLMの知能を活用して、計画を立て、推論し、取るべきステップを決定します。
- コードによるオーケストレーション:エージェントのフローを決定するためにコードを活用します。
全体として、OpenAI Agents SDKは包括的で、わずかなコード変更で簡単に動作させることが可能です。今回はOpenAIのCodexアシスタントを活用しました。
複数のフレームワークやツールキットが急速に発展し、マルチエージェントシステムの実現が近づいています。この分野は今後、急速な進化と革新が進むと予測されます。
マルチエージェントシステムの進化
エージェント型AIの進化に伴い、マルチエージェントアプリケーションはアプリケーションの運用方法を変革する役割を担う準備が整っています。これらのシステムは、専門化されたエージェント間の動的で文脈を認識したコラボレーションを可能にし、企業がますます複雑化するワークフローに取り組むことを支援します。自動化の支援から大規模なデータ分析のオーケストレーションまで、マルチエージェントシステムは新たなレベルの効率性、拡張性、革新性を解き放つでしょう。
Azure AI FoundryやAzure AI Studio上のOpenAI Agents SDKのようなツールは、この進化の最前線にあります。エージェントの引き継ぎ、ガードレール、トレースといった組み込み機能を提供することで、SDKはマルチエージェントワークフローの開発と監視を簡素化します。これらの機能により、組織は責任ある、安全で堅牢なAIシステムを容易に展開でき、運用における透明性と信頼性も確保されます。これらは普及の鍵となる要素です。
今後、この分野では急速なイノベーションが予想されます。MCPやA2Aプロトコルといった新興標準、およびOpenAI Agentsのようなフレームワークが、マルチエージェント相互運用性のための活気あるエコシステムを構築しています。焦点は、エージェントが自律的に計画・推論し、動的な環境に適応する、より知的で信頼性の高いオーケストレーションへと移行していくでしょう。
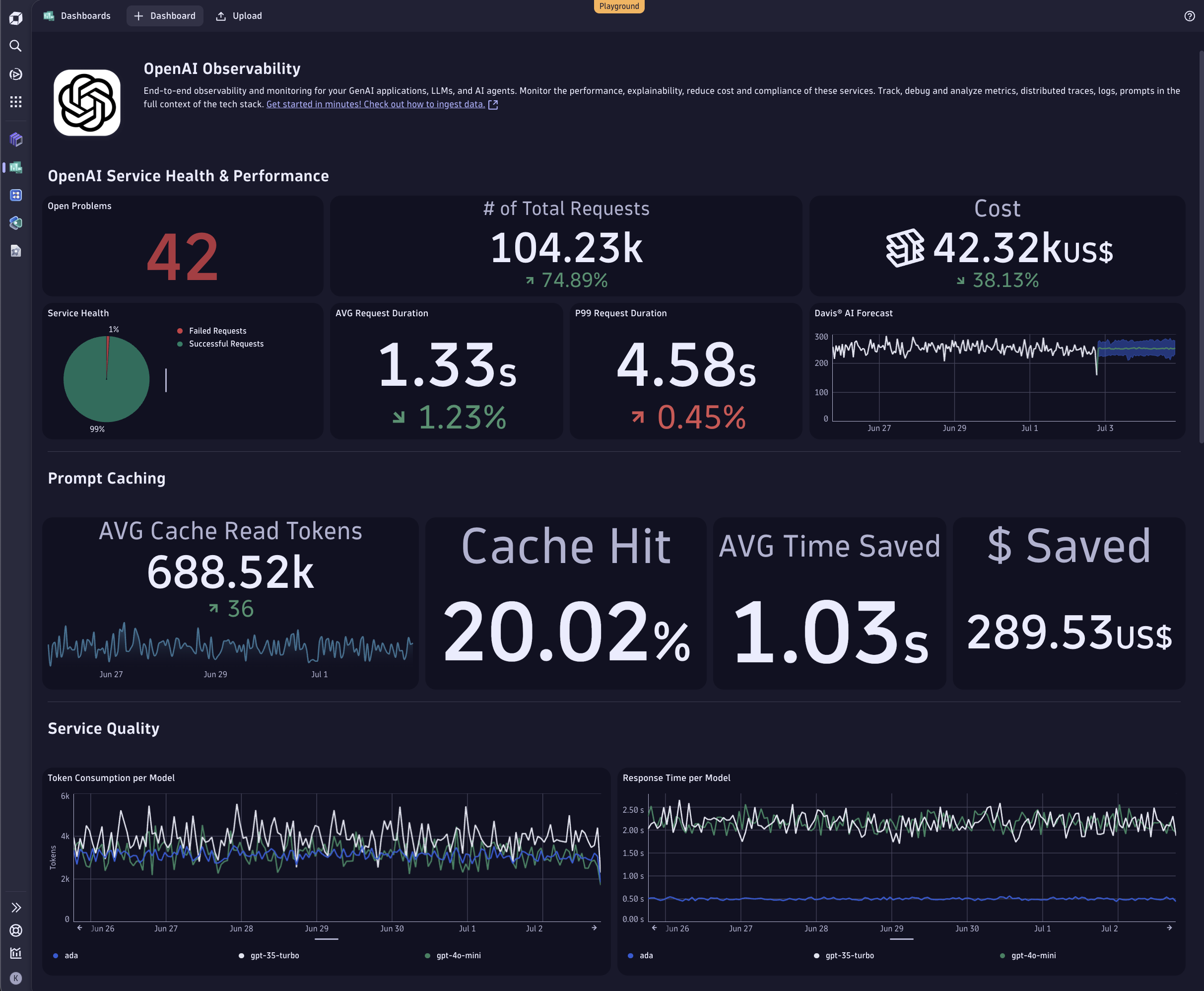
エージェント型AIアプリケーションのためのAI可観測性
こうした進歩に対応するためには、異種エージェントエコシステム全体での透明性を確保するため、可観測性も並行して進化させる必要があると私たちは考えております。Dynatrace AI Observabilityソリューションなどの可観測性ツールの進歩は、企業レベルでより信頼性が高くスケーラブルなAIフレームワークを構築する上で不可欠です。
マルチエージェントシステムの未来には計り知れない可能性が広がっており、OpenAI SDKはその出発点となります。私たちはまだ可能性の始まりに立っているに過ぎません。この技術が進化するにつれ、次第に安定性と信頼性を高め、最終的には産業全体における自動化、コラボレーション、そしてAIを活用した問題解決へのアプローチを根本から変革していくでしょう。
OpenAIエージェント、AWSストランド、Google ADKの詳細なコード例については、当社のGitHubリポジトリをご覧ください。本日より、ご自身のAI可観測性ソリューションの構築を開始いただけます。
続きを読む
- 「エージェント型AIの台頭」ブログシリーズの第1部では、AIエージェント、モデル、およびAgent2Agent(A2A)やMCPなどの新興通信規格の基礎について解説します。
- 第2部では、A2AおよびMCP通信の監視が、より優れた効果的なエージェント型AIを実現する方法を探ります。本ブログ記事では、AIエージェントの可観測性と監視、ならびにAmazon Bedrockエージェントのスケーリングと監視方法について解説します。
- 第3部では、Amazon Bedrock Agentsの監視方法と、可観測性が大規模なAIエージェントを最適化する仕組みについて説明します。
- 第4部では、NVIDIA BlackwellおよびNVIDIA NIMを用いたAIのフルスタック可観測性について取り上げます。
これらの機能を組み合わせることで、エージェント型AI環境において堅牢でスケーラブルな可観測性を実現し、チームが信頼性の高いアプリケーションやサービスを構築することが可能となります。



ご質問がございましたら
Q&A フォーラムで新しいディスカッションを開始するか、ご支援をお求めください。
フォーラムへ