
推論、学習、適応によってタスクを実行する自律型AIエージェントであるエージェント型AIシステムは、企業がタスクを自動化し複雑なワークフローを調整する方法を根本的に変革しています。本シリーズ「エージェント型AIの台頭」の第1回では、エージェント型AIと、エージェント間通信に用いられるAgent2Agentおよびモデルコンテキストプロトコル(MCP)について探求します。
現在では、大規模言語モデル(LLM)や生成型事前学習トランスフォーマー(GPT)によって駆動される生成AIの存在は広く認知されています。次のイノベーションの段階は、エージェント型AIとそれを推進する自律型AIエージェントです。エージェント間通信を促進するモデルコンテキストプロトコル(MCP)を活用するこれらのシステムは、企業がタスクを自動化し複雑なワークフローを調整する方法を革新しています。
LLM、ベクトルデータベース、検索強化生成(RAG)パイプライン、その他のツールによって駆動されるこれらのAIエージェントは、マルチエージェントシステム、クロスエージェントプロトコル、コンテキスト共有標準の出現を促しながら、広範に拡大しています。しかし、これらの自律型エージェントは、監視、デバッグ、セキュリティにおいても新たな課題をもたらします。
本稿では、AIエージェントとモデルの基礎、ならびにAgent2Agent(A2A) やModel Context Protocol(MCP)といったエージェント間通信を支える新興標準について詳細に検証します。
主なポイント:
- 自律型AIエージェントは、エージェント型AIの基盤となります。これらのサービスが連携することで、適応性のある自動化されたタスクを実現します。
- AIエージェントはLLM(大規模言語モデル)とオーケストレーションロジックに依存しております。これらの技術はエージェントの状態、セッションメモリ、コンテキスト、推論戦略を維持します。
- エージェントは、効果的な通信のためにA2AやMCPなどのプロトコルに依存しています。モデルとエージェントは、マルチエージェント間通信を管理するためにこれらのプロトコルを必要とします。
エージェント型AIとは?
エージェント型AIとは、独立したエージェントで構成される人工知能システムであり、主体的に行動し、推論、学習、状況変化への適応を通じて一連のアクションを実行し、タスクを完了させることができます。
Dynatraceのチーフテクノロジストであるアロイス・ライトバウアー氏は、エージェント型AIを次のように説明しています:
 |
|
エージェント型AIシステムは、望ましい結果につながるタスクを実行するためにAIエージェントに依存しています。
AIエージェントとは何ですか?
AIエージェントとは、大規模言語モデル(LLM)による推論、ツールの使用、および多数のデータソースからの状況認識を活用してタスクを実行する、自律的なアプリケーションです。
エージェントは外部からの介入なしに独立して思考し行動できます。思考の連鎖による推論、計画立案、実行(推論+行動=ReAct)、必要に応じた行動の改善が可能です。企業では、カスタマーサービスの自動化、サプライチェーンの最適化、コンテンツ生成などの用途で、こうした自律型エージェントの導入を検討しています。
AIエージェントはどのように動作するのでしょうか?
AIエージェントは、忙しい厨房で働くミシュラン星付きシェフのように動作します。絶えず情報を収集し、計画を立て、実行し、調整を加えながら、目指す最終目標に到達します。
シェフの例えで言えば、料理人は注文内容と入手可能な食材を確認し、適切なレシピを決定した後、フィードバックや資源の制約に基づいてアプローチを改良します。
エージェントも計算環境において同様の動作を行います。具体的には、世界(例えばユーザーのリクエストやデータセット)を観察し、最適な行動方針について内部推論を行い、リクエストを満たすために必要な手順を実行します。このサイクルにより、シェフが調理中に食材を代用したり料理を修正したりするように、変化する状況に適応的に対応することが可能となります。
この反復ループを支える基盤となるのがオーケストレーション層であり、エージェントの状態、セッション記憶、推論戦略(ReAct、Chain-of-Thought、Tree-of-Thoughtsなど)を維持します。大規模言語モデル(OpenAIのGPT、AnthropicのClaude、GoogleのGemini、AmazonのNovaなど)がエージェントの中核的な推論能力を提供します。モデルはユーザーのクエリについて「思考」します。しかしエージェントは、外部情報を取得したり現実世界でアクションを実行したりできる追加のフレームワークやツールを組み込むことで、その能力を発揮します。ツールや情報を取得・提供する一つの方法は、Model Context Protocol(MCP)と呼ばれる統一プロトコルを通じたものです。
さらに、オーケストレーション層は、エージェントがユーザーに最終的な応答を返す前に、複数の推論ラウンド、ツールの使用、ツールの出力がすべて追跡され統合されることを保証します。エージェントはこれらのステップを構造化された方法で実行するため、より正確で文脈豊かな回答を生成し、複雑なタスクを容易に管理できます。
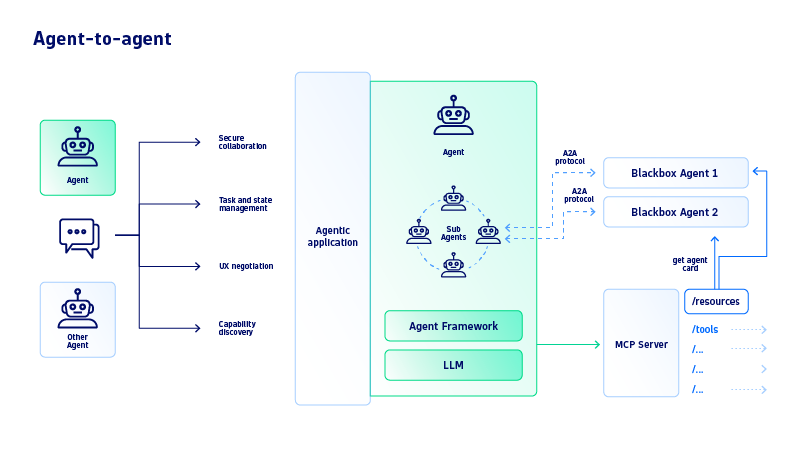
モデルとエージェントの違いは何でしょうか?
モデル(大規模言語モデルなど)は、単にトレーニングデータと与えられたプロンプトに基づいて出力を生成するものであり、通常、セッション記憶、外部アクション、複雑な意思決定ループや検証のための組み込みメカニズムは備えていません。
一方、エージェントはモデルを含みますが、さらに進んだ機能を備えています。状態を保持するプロセス(複数ターンにわたる会話や思考プロセスの管理)を維持し、外部ツールを使用して最新のデータを収集したりアクションを実行したりし、定義されたオーケストレーションロジック(ReActや 思考の連鎖など)に従います。したがって、モデルが中核的な推論コンポーネントであるのに対し、エージェントは自律的で目標指向の行動に必要な周囲の構造と機能を追加します。
エージェント間通信(A2A)とは?複数のエージェントが相互に通信する方法
企業が複数の専門エージェントを徐々に導入するにつれ、信頼性の高い体験を創出するためには、これらのサービスの相互運用性が極めて重要となります。これを実現するため、GoogleのA2Aは、ベンダーやフレームワークを問わず、エージェントが安全に情報を交換し、アクションを調整し、機能を統合することを可能にするオープンプロトコルの構築を支援します。標準化されたJSONベースのライフサイクルモデルでタスク、機能、成果物を定義することにより、A2Aは、本来ならサイロ化されたシステム間でマルチエージェントの連携を促進します。
A2Aプロトコルにより、エージェントはオーバーヘッドなしで更新情報の共有やタスクの委譲が可能となります。しかし、エージェント間の直接通信だけでは問題の半分しか解決されません。これらのエージェントは、意思決定を推進し、アクションを実行するための適切なツールセットを備えるために、関連性のある最新のデータとコンテキストも必要とするのです。
多様なデータソースにアクセスする統一された方法がなければ、最も能力の高いマルチエージェントエコシステムでさえ、その範囲は限定されたままです。オープンソースプロジェクトであるモデルコンテキストプロトコル(MCP)はこのギャップを埋めます。
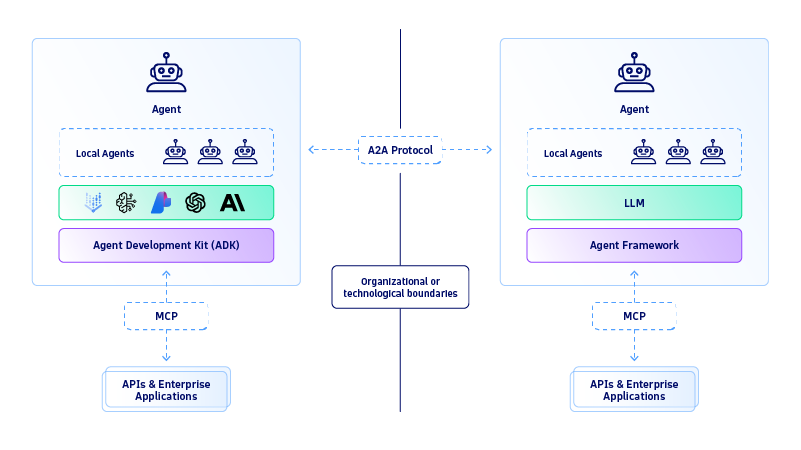
Model Context Protocolとは? MCPがエージェントに与える力
オープンスタンダードであるモデルコンテキストプロトコル(MCP)は、AIエージェントをリポジトリ、ツール、外部APIなどの関連データソースに接続します。前述の各データサイロ向けの統合とは異なり、MCPはUSB-Cのようなユニバーサルインターフェースを提供し、複数の関連ソースを接続してモデルやエージェントに適切なコンテキストを供給します。この汎用性により、エージェントが関連コンテキストにアクセスする方法が簡素化され、複雑な環境全体でタスク成果の向上、実行の最適化、より一貫したパフォーマンスが実現されます。上記のような複雑なタスクを管理するため、GitHub上のDynatrace MCPサーバーは、リアルタイムのエンドツーエンド可観測性とMCPデータを日常業務に取り入れるお手伝いをいたします。
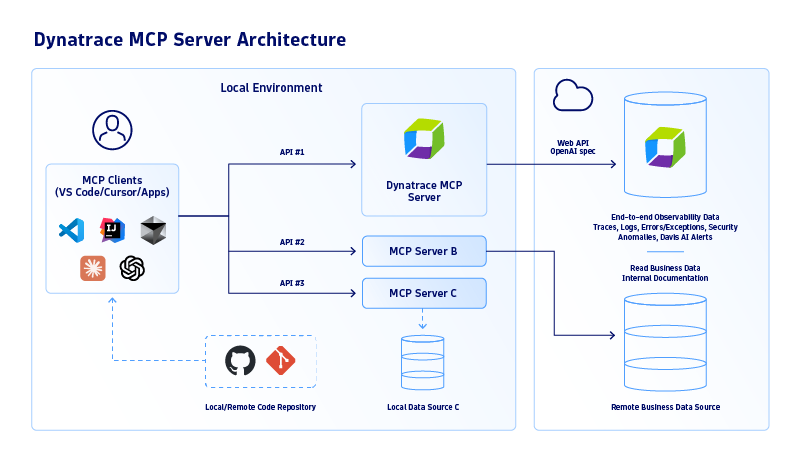
今後の展望:より優れたエージェント型AIのためのA2AとMCPの監視
これらの技術が進化するにつれ、エージェントオーケストレーションプロトコル(A2AおよびMCP)とオープンな可観測性フレームワークのより深い統合が期待されます。これにより、データ取り込みからエージェント間連携に至るエンドツーエンドの可視性が実現されます。同様に、標準が収束するにつれ、組織は完全な透明性と制御を維持しながら高度なAIソリューションを迅速に構築できるようになり、自律エージェントのさらなるスケーラビリティ、回復力、信頼性への道が開かれます。
詳細はこちら
- 「エージェント型AIの台頭」ブログシリーズの第2部では、AIエージェントの可観測性と監視、A2AおよびMCP通信、Amazon Bedrockエージェントのスケーリングと監視方法について探求します。
- 第3部では、Amazon Bedrock Agentsの監視方法と、大規模なAIエージェントにおける可観測性の最適化について解説します。
- 第4部では、NVIDIA BlackwellおよびNVIDIA NIMを用いたAIのフルスタック可観測性について取り上げます。
- 第5部では、OpenAI Agents SDKを使用したシンプルなエージェント型アプリケーションの構築方法と、Dynatraceによるデータ計測の実践例をご紹介します。




ご質問がおありですか?
Q&Aフォーラムで新しいディスカッションを開始するか、ご支援をお求めください。
フォーラムへ