
Updated Jan 25, 2021: Premium High Availability for Dynatrace Managed is now available in a GA release
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. This means that Dynatrace continues full operation when a majority of nodes are up and a maximum of two nodes are down at a time. For example, in a three-node cluster, one node can go down; in a cluster with five or more nodes, two nodes can go down. The network latency between cluster nodes should be around 10 ms or less.
With Dynatrace actively managing business-critical applications, some of our globally distributed enterprise customers require Dynatrace Managed to continue operating even when an entire data center goes down. In other words, they need to meet a Geographic Redundancy Objective (GRO).
We’re therefore proud to announce Premium High Availability for Dynatrace Managed to address exactly this need in a completely turnkey manner without any external load balancing or replication technologies. Thus, you can achieve a resilient, fault-tolerant deployment with effective replication between regions. Our Premium High Availability comes with the following features:
- Active-active deployment model for optimum hardware utilization
- Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios
- Automatic recovery for outages for up to 72 hours
- Self-contained turnkey solution
- Minimized cross-data center network traffic
Turnkey high availability across globally distributed data centers
Premium High Availability allows for Dynatrace Managed installations across globally distributed data centers and provides fully automatic failover capabilities in case an entire data center experiences an outage. This extends the existing high availability capabilities of Dynatrace Managed to now also provide geographic redundancy for globally distributed enterprises that run highly critical services in a fully turnkey manner without depending on external replication or load balancing solutions.
“Dynatrace is a Tier 0 application for us. It is more critical than any other individual application.”
– A Dynatrace customer, Head of Performance Engineering
Achieve high SLOs with seamless monitoring when entire data centers experience outages
Dynatrace Premium High Availability (Premium HA) is a self-contained turnkey solution. It ensures that Dynatrace fulfills the most important service level objectives (SLOs) in terms of availability:
- Recovery Point Objective (RPO) specifies how far to roll back in time and defines the maximum allowable amount of lost data, measured in time from the occurrence of a failure to the last valid backup. Currently, for regular Dynatrace Managed deployments, RPO is 24 hours, as we create daily backups. Dynatrace Premium HA allows monitoring to continue with near-zero data loss in failover scenarios.
- Recovery Time Objective (RTO) is related to downtime and represents how long it should take from a failure incident until normal operations are available to users. Currently, RTO depends on the data and cluster size and starts at one hour for a single node with a small amount of data. With Premium HA, you’re equipped with zero downtime.
- Geographic Redundancy Objective (GRO) is an objective that defines what data needs to be replicated off site, how often, and how far. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms network latency due to asynchronous data replication between regions.
The images below demonstrate the added value that Premium High Availability provides compared to regular Dynatrace Managed deployments for different outage scenarios.
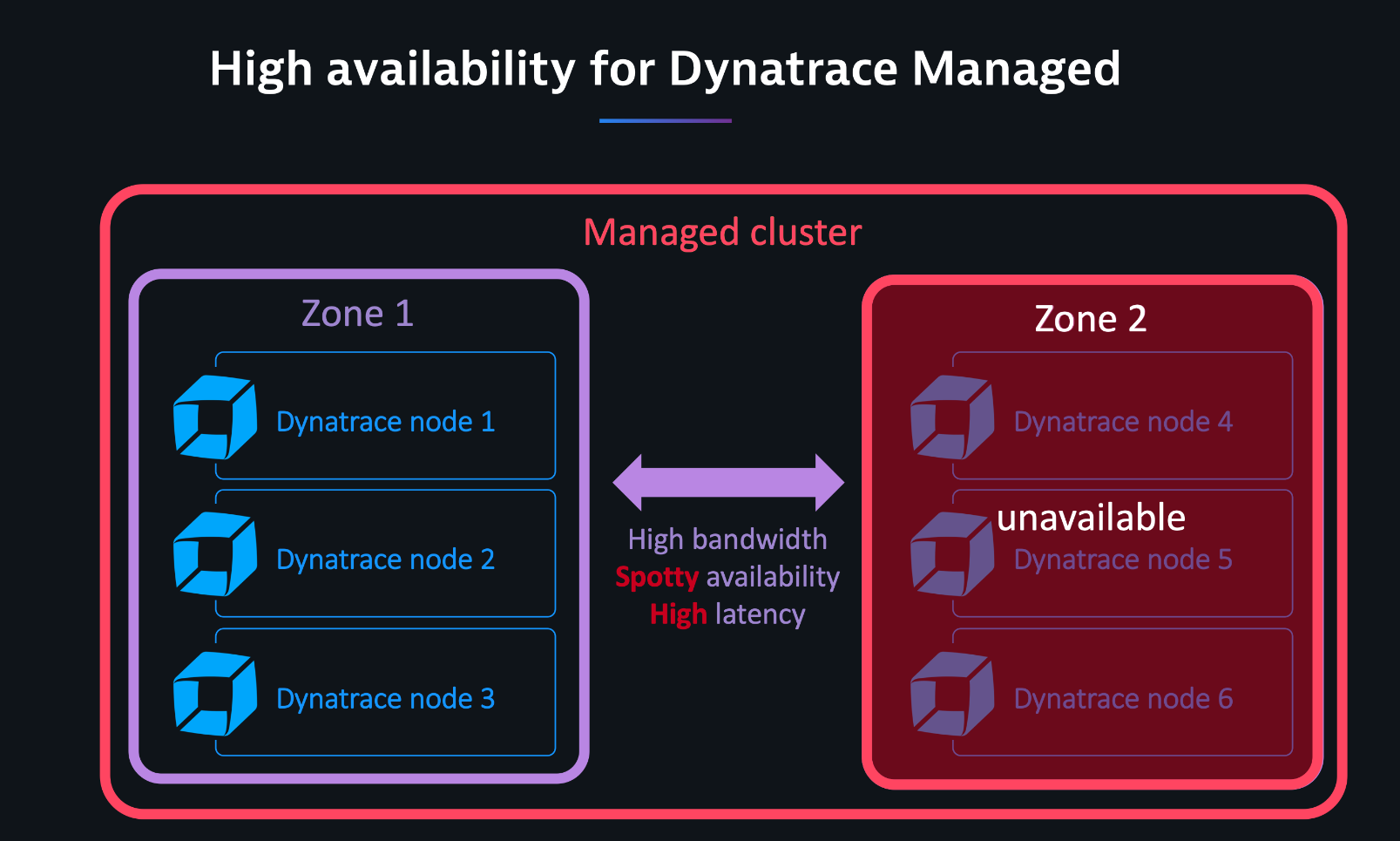
Regular Dynatrace Managed deployments can work seamlessly when a maximum of two nodes are down at a time and the network has low latency. In the image below, three downed nodes make an entire cluster unavailable.
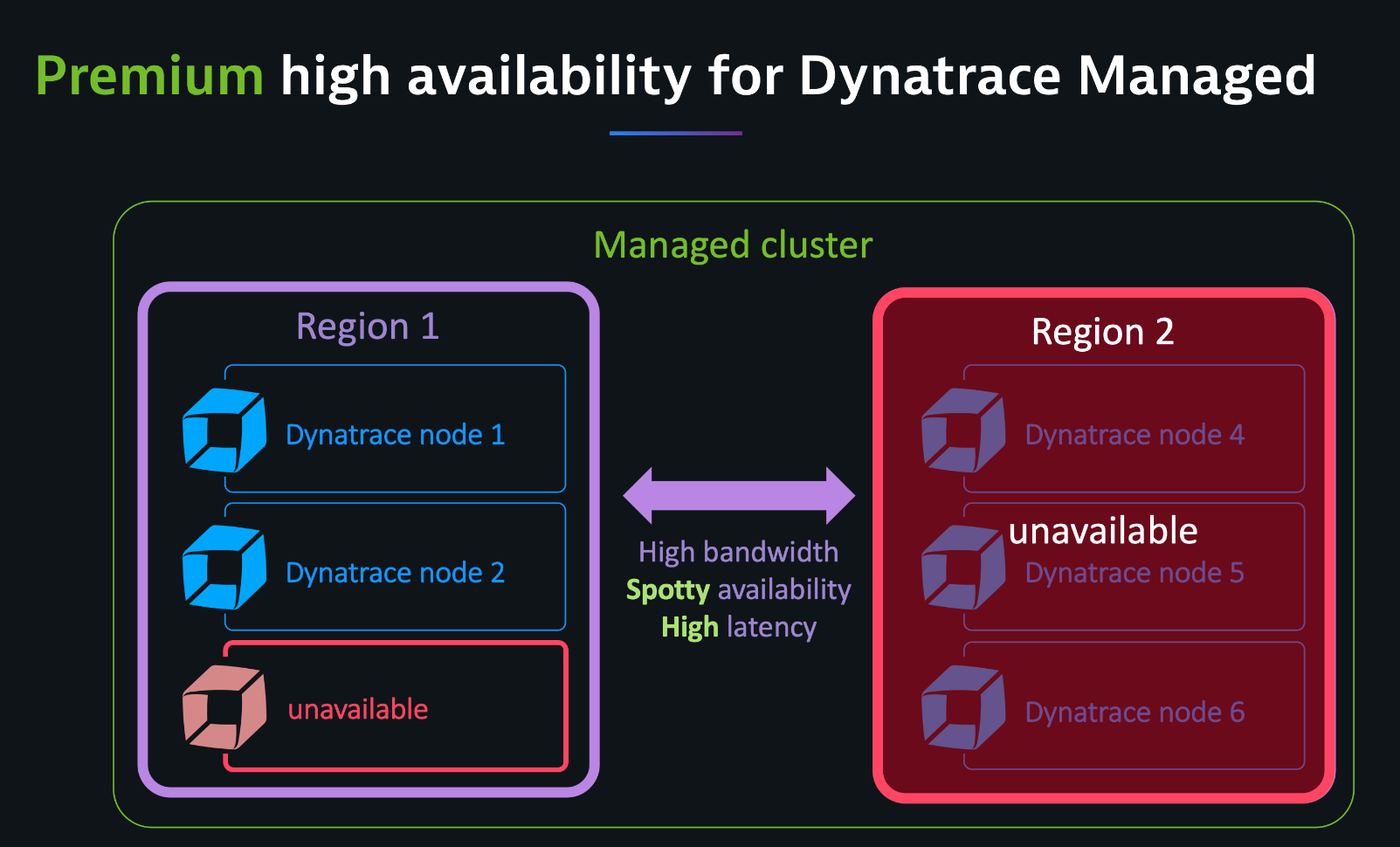
Premium High Availability ensures that Dynatrace Managed works reliably in long-distance networks and can survive a complete data center outage with automatic failover. In the image below, the cluster remains available when a node in the first region and the entire second region are down.
Save on costs for hardware and network bandwidth to optimize total cost of ownership
Cost is a critical factor but it shouldn’t be the only criterion you look at to protect your data. You’ll find that as RTO and RPO requirements go up, cost increases at a rate of diminishing returns. A similar analysis can be performed on your GRO.
Dynatrace Managed Premium High Availability provides cost savings in terms of compute and storage allocations. This is achieved by active-active deployment for optimum hardware utilization, thus eliminating the need for separate standby disaster recovery (passive) hosts and the associated infrastructure to store and transfer backup data. By utilizing embedded smart routing capabilities, Dynatrace minimizes cross-region network traffic—OneAgent traffic stays within the same network region. Moreover, as a turnkey solution, Premium HA saves operations costs related to the setup and maintenance of disaster recovery and business continuity procedures. This is enabled by automatic fallback for outages for up to 72 hours, along with the lowest possible RPO and RTO.
How it works
Now that you understand the value and costs associated with Premium High Availability, let’s explain how this is designed and assure you of the resilience of the solution. Premium HA stands on the four pillars of data consistency and availability—replication, distribution, synchronization, and failover:
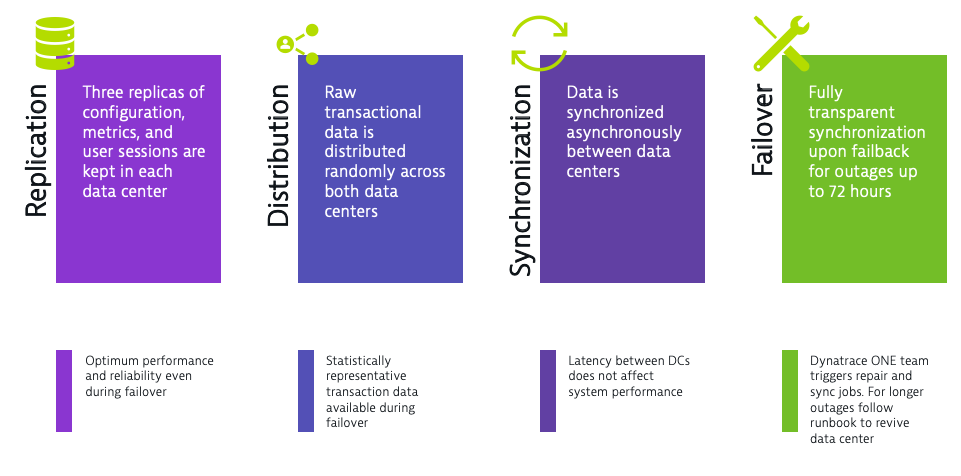
Premium HA utilizes two active-active data centers to ensure availability. Cluster nodes reside in both data centers and they continuously process, store, and replicate data. It should be noted that while the compute capacity available to the cluster is positively affected by the additional nodes in the peered data center, the impact is not linear. For the purposes of capacity planning, the nodes in the second data center should be considered redundant rather than as expanded capacity. This is because the second data center has a copy of all the Cassandra and ElasticSearch data from the first data center.
The Cluster Management Console has been extended to support two data centers:
- The CMC Home page displays data center names next to cluster nodes.
- Backup configuration allows you to select the data center that performs the backup. Nodes from that data center have to be configured with access to NFS.
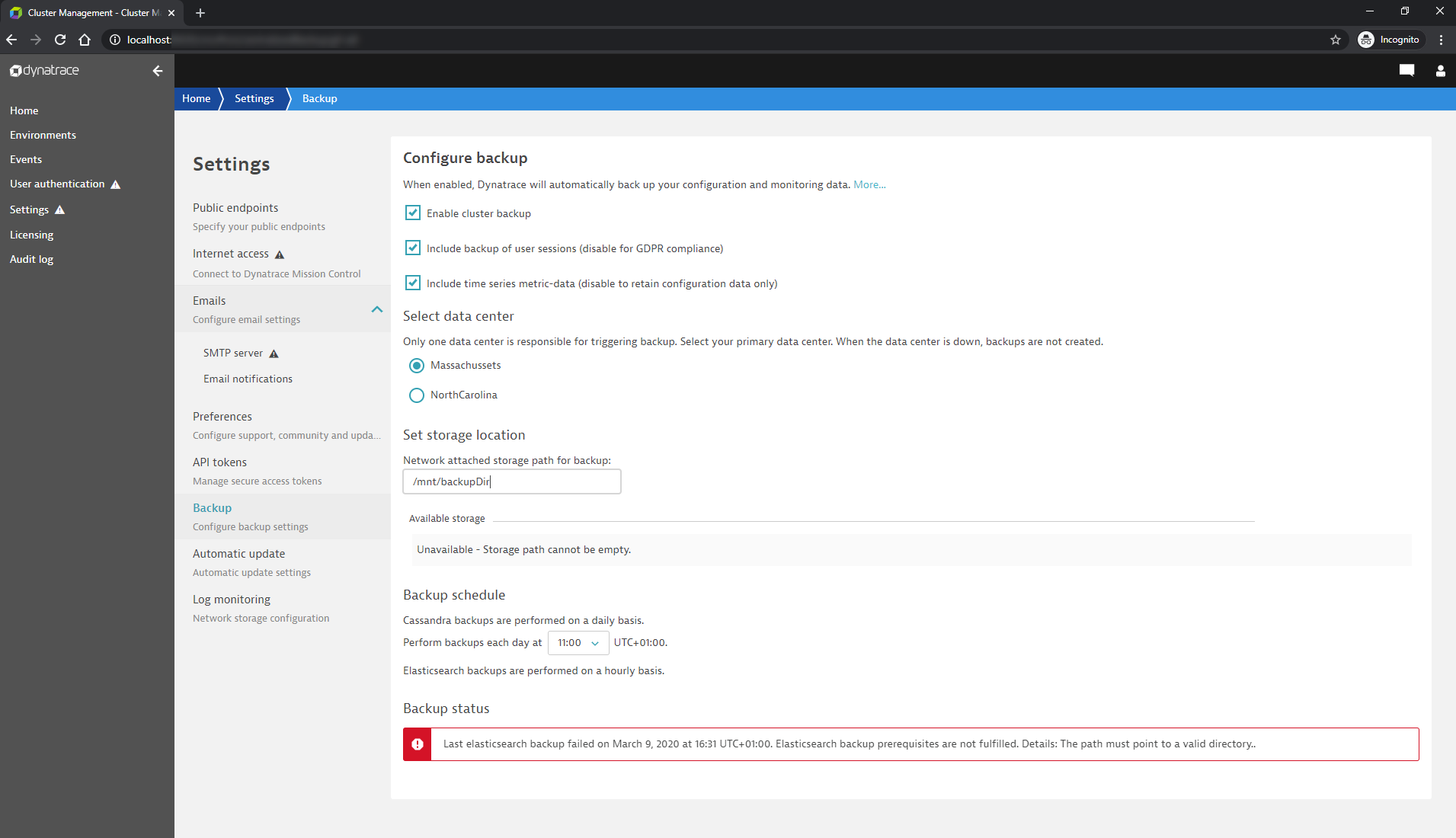
- You can set up different proxy servers for the Mission Control uplink for each data center
When and how can you get Premium HA
Premium High Availability is licensed separately and intended for installations with 1,000+ host units. Before getting started, your license needs to be extended. Please contact your Dynatrace account representative for pricing and licensing questions.
We are announcing Early Adopter release that is planned to start with version 196, available in July 2020. Take your time to prepare hardware, network and other infrastructure adjustments so you are ready. In the following release in August, General Availability (GA) is planned. It will be announced separately.
Participation in this Early Adopter release requires Dynatrace R&D involvement for initial setup. This release isn’t recommended for production clusters.
Initial restrictions—these will be addressed later this year
- Premium Log Monitoring requires access from all nodes from both data centers.
- Not available for offline clusters.
- After an outage longer than 3 hours, but shorter than 3 days – repair script has to be run by Dynatrace ACE team or a cluster operator
- Manual resolution is required during a split brain – for the time it is not resolved data inconsistencies might happen
- Requires a minimum of 3 large nodes and plans for replicating all nodes in a new data center.
- Supports a maximum 9 nodes per data center (18 nodes in total).
Additionally, a Linux operating system with support for cgroups and systemd (for example, RHEL/CentOS 7+), is required.
Updated Jan 25, 2021:
- Access from all nodes for Premium Log Monitoring will be solved in CQ1/CQ2 of 2021.
- Work to support air-gapped (offline) clusters is currently on hold.
What’s next?
The Premium High Availability turnkey solution for Dynatrace Managed fulfills the highest SLOs with near-zero RPO and RTO when an entire data center has an outage. Total cost of ownership (TCO) is reduced as you save costs on hardware, network bandwidth, and operations to set up disaster recovery. We plan to improve on this solution continuously in upcoming releases. In addition to addressing the initial restrictions mentioned above, we currently plan to:
- Upgrade the user interface so it supports the filtering of cluster nodes by network region and other properties so it’s more manageable at scale.
- Reduce cross-region traffic for Log Monitoring and Synthetic Monitoring.
- Increase resilience by adding rack-aware redundancy.
Your opinions and input matter to us. Go to Dynatrace answers and share your feedback by posting your questions and comments. Ensuring disaster recovery is like having an insurance policy—you may never have to use it, but someday, it may save your business.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum