
In this blog post, we share insights into how Dynatrace automates software delivery and quality validation tasks using the Dynatrace® Site Reliability Guardian. Announced at Perform 2023, the Site Reliability Guardian exemplifies our commitment to DevOps and SRE best practices that ensure reliable, secure, and high-quality releases.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. The Dynatrace Site Reliability Guardian is designed for this practice; it allows development teams to define quality objectives in their code, which is validated throughout the delivery process before the code reaches production.
While quality standards and validations should ideally be implemented throughout the software development lifecycle, we see teams adopting the Site Reliability Guardian at various stages, from development to production environments. Our discussions with teams who use Site Reliability Guardian in production reveal that starting with post-deployment validation provides quick insights into the status quo and helps identify areas that need improvement via pre-production validations. This approach, known as “shift-left,” is preferred by organizations that derive insights from their production environments and plan improvements from there.
How Dynatrace uses Site Reliability Guardian
In each of these Dynatrace examples, insight is made in a production-like environment. Validation tasks are then extended left to cover performance testing and release validation in a pre-production environment. These examples can help you define your starting point for establishing DevOps and SRE best practices in your organization.
Ensure expected production behavior
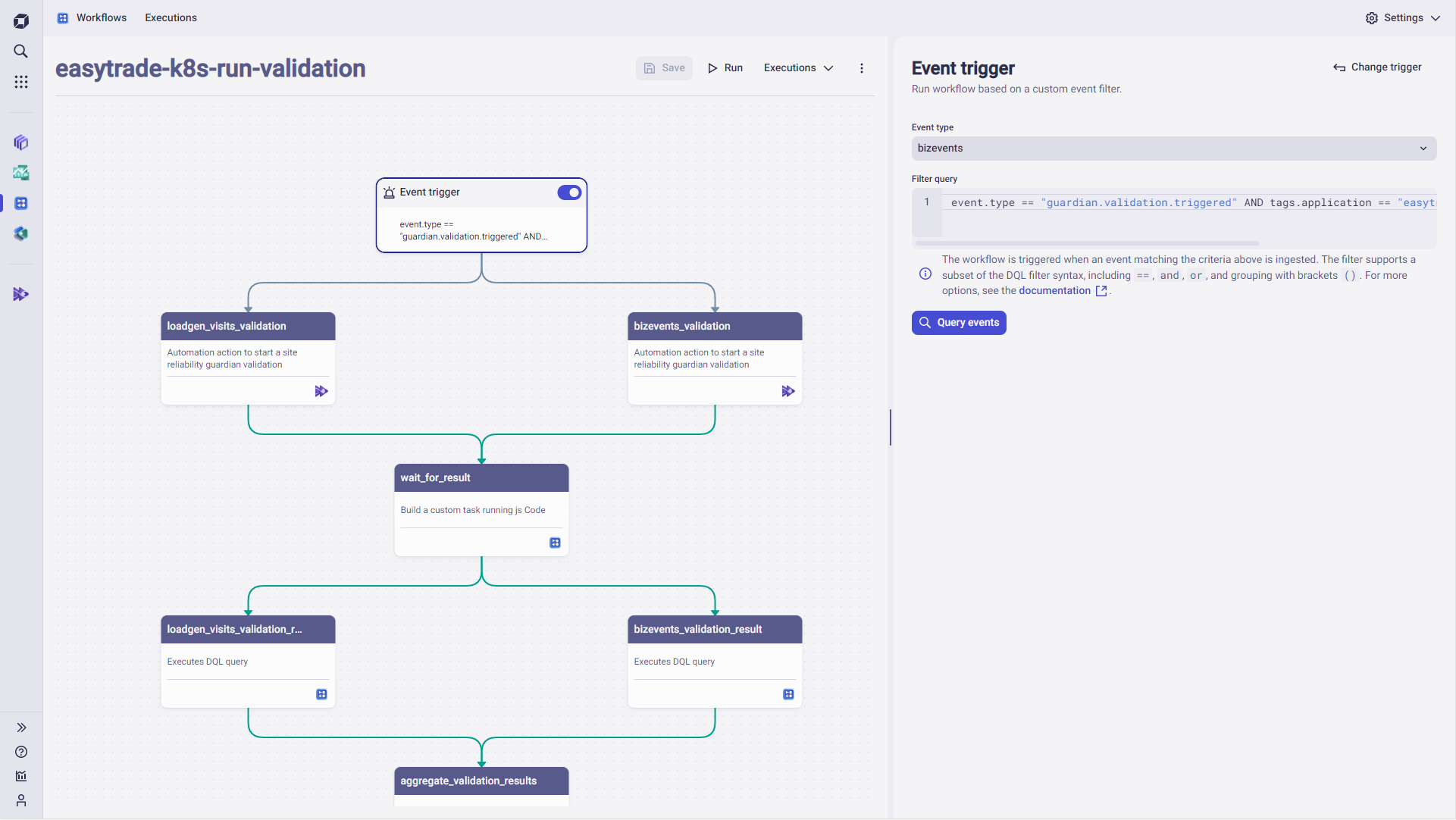
One Dynatrace team is responsible for the demo applications we use to demonstrate Dynatrace capabilities. We use monitored demo applications to deliver constant load and a defined set of business transactions. Without demo applications, it would not be possible for our sales teams in the field to show off the full power of Dynatrace. To ensure these objectives, the team leverages the Site Reliability Guardian to check for a potential decrease in business transactions whenever a new application release is deployed.
Two guardians, which are managed by the team’s Site Reliability Guardian and contain different sets of objectives, are used in this setup. While the first guardian validates the traffic, the second guardian checks the business transactions generated during the observation period. The functionality is implemented via an automated workflow.
The Workflows screenshot below shows that a task is triggered by a change event related to the application, execution of the guardians, and final aggregation of the results. Ultimately, the result is shared via a Slack notification to report on the current business behavior.
Resilient applications with chaos testing in pre-production
Another Dynatrace team uses a guardian as a safeguard during chaos testing. More precisely, this team uses AWS Fault Injection Simulator (FIS) to run fault injection to improve the application’s performance and resiliency. These experiments are accompanied by well-defined objectives formulated as Dynatrace service-level objectives (SLOs). The guardian is used to bring the experiment of the fault injection simulator and the SLOs together. Hence, it validates the status of the SLOs for the experiment period to derive potential regressions that might have been introduced in a newer release.
While this team uses Fault Injection Simulator (FIS) to run their chaos testing experiments, the Site Reliability Guardian is not limited to this testing practice. It fits well into the entire performance testing domain where reliability, performance, and security indicators must be continuously validated.
Release validation on the four golden signals in pre-production
Another Dynatrace team adopted Site Reliability Guardian with an early version of our Traces in Grail capability for a classic approach to release validation within its delivery pipeline. In other words, they use it as a quality gate that detects bad releases before they reach production. They first explore relevant objectives in their production environment. Based on those insights, they implemented automated validation tasks, and shifted left in their software delivery pipeline.
In this case, the four golden signals (latency, traffic, errors, and saturation) are derived from span attributes and DQL metric queries via Dynatrace Grail™. The queries are depicted below (sensitive data has been removed).
Latency – Response time (below 50 ms) derived from spans
fetch spans
| filter application.name == "APPLICATION-NAME"
| filter application.environment == "hardening"
| filter dt.entity.service_method.name == "getEffectivePolicies"
| filter span.kind == "SERVER"
| summarize toDouble(countIf(duration <= 50ms)) / count()Traffic – Number of requests derived from log lines
fetch logs
| filter log.source == "projects/APPLICATION-NAME/logs/requests"
| parse content,"JSON:request"
| fieldsAdd httpRequest = request[httpRequest]
| summarize count = count()Error rate – Number of HTTP 5xx errors derived from spans
fetch spans
| filter application.name == "APPLICATION-NAME"
| filter application.environment == "hardening"
| filter dt.entity.service_method.name == "getEffectivePolicies"
| filter span.kind == "SERVER"
| summarize response_500_error_rate = toDouble(countIf(http.status_code >= 500 AND http.status.code < 600))/count()Saturation – Memory requested by a Kubernetes workload
timeseries avg(dt.kubernetes.workload.requests_memory),
filter: in(dt.kubernetes.workload.name, "WORKLOAD-NAME")Please note that “Traces in Grail” are currently in private preview, and the DQL syntax could be subject to change.
What’s next?
Dynatrace strives to enable DevOps and SREs to ship software that works perfectly. Accordingly, we provide the Site Reliability Guardian as one way to establish reliability, security, and quality practices early in your software development lifecycle.
Stay tuned for an upcoming blog post that shows how you can shift your DevOps and SRE practices even further left by declaring your standards in code—leveraging the Dynatrace configuration-as-code approach—and validating them via Site Reliability Guardian as part of your delivery process.
Check out the Site Reliability Guardian for yourself by installing it using the Dynatrace Hub, then share your feedback with us and let us know how you intend to use it. Head over to the Dynatrace Community to see our plans for additional features. We’d love to hear your suggestions and ideas.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum