
How your organization can move from DevOps to NoOps and ACE, taking advantage of Dynatrace's experience on our own transformational journey.
It feels like just yesterday DevOps was all the rage, and everything had to be “Cloud” in order to be modern. These days, most organizations have embraced the benefits of DevOps and are running one or more of their applications on somebody else’s computer.
But what made organizations adopt these techniques and technologies? It was the promise that they could deliver software faster, more frequently, and with higher degrees of quality, enabling the business to respond better to constantly changing customer demand.
The faster you could take an idea from conception to your end users, the larger your competitive advantage. Alternatively, your competitive edge would surely dwindle if you had to wait six months for the next release window to get that much wanted feature into production.
The Dynatrace journey
At Dynatrace, we went through such a transformation ourselves, back in 2011 when we saw the need to create a new platform that was purpose-built for these dynamic, cloud-native IT environments. But when we first embarked on this journey, we looked like a very traditional software company:
- Two releases per year
- 100% of our production issues were discovered and reported by our users
- A relatively simple environment of 5 EC2 instances
- Zero daily deployments
Fast forward 6-7 years and the situation looks entirely different:
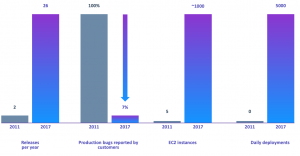
We realized the importance of transforming the way we built and deployed our new solution, and today, we now release new features to our customers 26 times per year.
And while our environments have exploded in terms of complexity, we’ve reduced the number of production issues reported by our customers to around 7%, and we deploy about five thousand times per day in production-like environments to continuously test our platform.
How did we achieve that? With our Dynatrace secret sauce, where automation was the key ingredient.
The Dynatrace way
Our platform now had AI and automation built in its core, enabling us to deliver better software, faster and provide a platform that could scale and resonate with these new cloud-native IT environments.
Over time, our story resonated with our customers, partners. Even analysts like Forrester who wrote a non-commissioned case study on our successful transformation.
And the more we started talking about our story, the more we saw IT leaders across our market, and other industries alike, recognize the importance AI and automation hold as they demonstrated a strong desire and to move towards NoOps and Autonomous Cloud Enablement (ACE) too.
The Road to ACE
Recognizing this market change, we felt that given the right mindset, approach and dedication any enterprise could embark on their own ACE journey just like we did.
And so, to further our impact on our own customers we conducted a study, in an effort to determine where our customers were in terms of maturity on their road to NoOps and ACE, and found that whilst most of our customers were doing DevOps and running applications in the cloud, they were not realizing the results they hoped to see:
- Not every sprint was resulting in new features being deployed in production
- Deploying a code change into production was often a matter of weeks, not hours
- They had a very ops-centric model with manual steps in many phases of the pipeline
- There was little to no automation of issue remediation and MTTR remained a high five business days
It got us thinking: “Why is that?”.
So, we began designing a repeatable solution to this challenge, represented in our ACE methodology below.
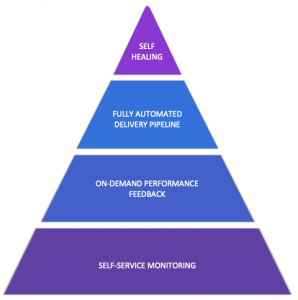
As with building any pyramid, you need to work your way from the bottom up:
- Self-service monitoring needs to be everywhere. Every application in every environment should be uniformly monitored, without any human intervention. With a single glance, you should be able to identify the components of interest to you and this also means that every time an application or microservice is deployed, or configuration or feature flag changes, your monitoring tool is aware of this.
- On-demand performance feedback builds on that by allowing you to make performance part of your delivery pipeline. This means shifting your tests left so that you can detect performance regressions and other issues straight away, making them easier and cheaper to resolve. However, performance test execution and evaluation shouldn’t be a manual process and certainly shouldn’t be limited to dedicated testing teams. So, to truly shift left and reduce the risk associated with pushing changes into production more frequently, developers must be accountable for their changes and need on-demand feedback from performance tests in order to find defects earlier in the SDLC.
- Once we can build high-quality software, faster, and more often, the Fully Automated Delivery Pipeline is there to ensure we can get that functionality to our users in an efficient and safe way. Introducing intelligent quality gates significantly reduces the time and effort to evaluate changes, and introduces a more proactive approach to traditional change management. Zero-downtime deployment strategies such as blue/green or canary releases introduce built-in recovery mechanisms to reduce the impact of defects on production users. Whichever strategy we choose, an important factor is being able to monitor our new deployment and see how it compares to the existing version and act upon a regression either manually or automatically.
- At the pinnacle of ACE lies the ability for Self-Healing. Often misunderstood, this is not limited to reactively triggering a runbook to roll back to a previous version (or blue/green switch) or triggering some infrastructure automation. Self-Healing also means setting up your architecture, application, code, and infrastructure to deal with situations that go past operational requirements and inevitable failure of components. Your application should not grind to a halt because of the recommendation engine not working, so design your application with that goal in mind. For example, what if there is a data center outage? Dynatrace can be an integral part of your auto-remediation workflows. Change is often the biggest reason for failure and, with every organization moving to a more rapid pace of change, any change may cause failure and we need to be ready to quickly revert it. When you make a change, make sure you have deployed AND tested your remediation strategy in case a fire breaks out.
By applying these four concepts throughout your organization, you can deliver on the premise that we started off with: delivering software faster, more frequently and more reliably in a world that demands innovation at the speed of light without diminishing quality.
Where to next?
Now you’re excited about the benefits ACE can bring to your organization, and you’ve learned a thing or two about our own transformation at Dynatrace, you may wonder where to go next?
First of all, I suggest that you fill in the Dynatrace Autonomous Cloud Survey and see how you stack up against your peers. Also, check out my colleague Katalin’s blog post on what these results mean for your organization.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum