
組織がダウンタイムの測定可能な削減に苦戦する中、平均修復時間(MTTR)やその他のインシデント管理指標は、DevOpsの成功にとって極めて重要です。しかし、MTTRとは何でしょうか?それは単なる平均修復時間を超えた意味を持っています。
DevOpsチーム やITOpsチームは、平均修復時間(MTTR)などのインシデント管理指標を重視しています。これらの指標は、ネットワークシステムの稼働を維持するために役立ちます。これは極めて重要な課題ですが、口で言うほど簡単ではありません。その他の指標としては、稼働時間、ダウンタイム、インシデント件数、インシデント間の間隔、および問題への対応・解決にかかる時間などが挙げられます。
2022年の「アウトエイジ分析レポート」によると、企業は停止率や深刻度の測定可能な削減を達成するのに苦戦していることが明らかになりました。また、停止による財務的影響が着実に増大していることも判明しました。こうしたプレッシャーにより、MTTRやその他のインシデント管理指標に対する重要性はさらに高まっています。
では、MTTRとは何でしょうか?最も一般的な解釈では、平均修復時間(Mean Time to Repair)を指します。しかし、平均対応時間、平均解決時間、平均復旧時間(Mean Time to Respond、Resolve、Recovery)を表す場合もあります。これらの定義はすべて異なり、それぞれ重要です。しかし、同様に重要なのは、MTTRが他のインシデント管理指標とどのように関連しているかという点です。ここでは、これらの指標の意味と、MTTA、MTTF、MTBFといった他のDevOps指標との関連性について解説します。
最も一般的なインシデント管理指標の理解
ITインシデントとは、サービスの混乱や停止を引き起こし、業務を中断させる予期せぬ出来事のことです。ITインシデントの主な4つの段階は以下の通りです:
- 特定: 発生した事象を検知して 詳細を記録し、影響度と緊急度に基づいてインシデントの優先順位を付け、顧客やビジネスへの影響度を評価します。
- 封じ込め:影響を受けたシステムを保護するための措置を講じ、インシデントを迅速に解決し、必要に応じて他のチームにイベントをエスカレーションします。
- 解決:是正措置が完了したことを確認し、現在のビジネスへの影響が終了した時点を特定します。
- 維持:根本原因の分析とシステムの継続的な改善を通じて、インシデントの再発リスクを低減します。
ほとんどのITインシデント管理システムでは、インシデントを効率的に処理し、最適な顧客体験のためにサービスを中断なく維持するために、以下の指標のいずれかを使用しています。
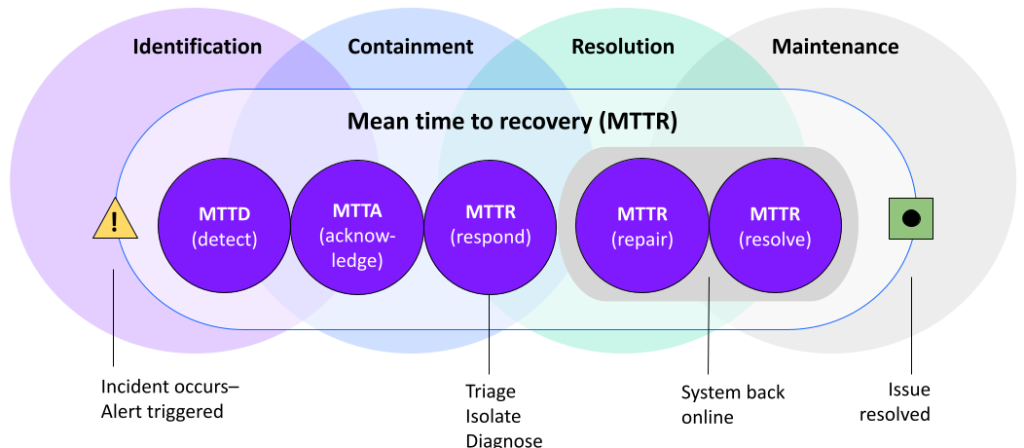
MTTRとは?その違いを詳しく解説
MTTRは、平均対応時間(Mean Time to Respond)、平均修復時間(Mean Time to Repair)、平均解決時間(Mean Time to Resolve)、および平均復旧時間(Mean Time to Recovery)の頭文字を取ったものです。それぞれが異なる概念であり、インシデント管理フレームワークの中で独自の位置を占めています。
| メトリック | 説明 |
|---|---|
平均応答時間 |
平均対応時間(MTTR)とは、DevOpsチームがアラートを受信してから対応するまでの平均時間を指します。チームは、インシデントを検知してから是正措置を開始するまでの時間を測定するために、この指標をよく使用します。多くのチームでは、問題の修復や是正に要する時間もこの指標に含めています。これには、アラートシステムにおける遅延時間は含まれません。
MTTRを算出するには、チームがインシデントを検知してから、修復または是正計画を開始(または完了)するまでの時間を測定します。その時間を、特定の期間内にチームが対応したアラートの数で割ります 。 MTTRは、サイバーセキュリティの分野で、平均検知時間(MTTD)と併せて、システムへの攻撃を無力化するチームの成果や、将来のセキュリティ侵害を予測・防止する能力を測定するために頻繁に使用されます。 |
平均修理時間 |
平均修復時間(MTTR)とは、故障したコンポーネント、アプリケーション、またはサービスを修復するのにかかる平均時間のことです。この測定値には、サービスが完全に機能するようになるまでのテストに費やされた時間も含まれます。一般的に、平均修復時間は、 チームが 問題を診断した後、修正を実施するのにかかる平均時間のみに焦点を当てています。MTTRを算出するには、チームが障害の修正に費やした合計時間を、完了した修復件数で割ります。 5件の問題を修正するのに30時間かかった場合、平均修復時間は6時間となります。このデータを継続的に収集し、平均MTTRスコアを算出します。 組織では、保守契約やサービスレベル契約(SLA)にMTTRを盛り込むことがよくあります。あるシステムのMTTRが24時間、別のシステムのMTTRが3日であり、両システムの障害発生間隔が同じ場合、前者のシステムの方が可用性が高いため、より価値があると言えます。 |
平均解決時間 |
平均復旧時間(MTTR)とは、不具合が発生したシステムを完全に診断し、修復するまでに要する時間のことです。これには、問題が再発しないよう根本原因を解消することも含まれます。これは、DevOpsチームが問題を迅速に診断し、修正策を実行する効率性を示す指標です。MTTRの数値が良好であることは、チームが不具合をどの程度的確に予測し、対策を講じているかを反映しています。
MTTRを算出するには、特定の期間内にインシデントを診断し解決するのにかかった時間を合計し、その合計をインシデント件数で割ります。例えば、24時間の期間中にシステムが2時間ダウンし、チームがその障害の診断と修復に2時間を費やした場合、解決までの時間は4時間となります。 平均解決時間(MTTR)とは、DevOpsチームが問題を診断し、修正するのにかかる平均時間を指します。これには、調査、修復、およびテストにチームが費やす時間が含まれます。システムが完全に稼働し、将来の停止を防ぐために根本的な問題が解決されるまで、この計測は終了しません。 |
復旧までの平均時間 |
平均復旧時間(MTTR)は、ダウンしたネットワークやシステムを復旧させ、正常に稼働させるまでに要する総時間を測定するものです。これは、アラートが最初にトリガーされた時点から始まり、影響を受けたすべてのシステムが正常に機能するようになった時点で終了します。
MTTRは、特定の期間のダウンタイムをインシデント数で割ることで算出します。例えば、2日間にわたり2つの異なる事象によって合計20分のダウンタイムが発生した場合、平均復旧時間は10分となります。 MTTRは、インシデント対応能力全体の効率性を測定する指標です。システムや製品の不具合が発生した瞬間から正常な動作が再開されるまでの、停止期間全体を網羅します。MTTRは、インシデント対応チームがビジネスおよび影響を受けた顧客をどの程度の速さで正常な状態に戻せるかについて、洞察を提供します。これは、インシデント対応プロトコルのあらゆる側面における全体的な効率性を測定するための、優れた集計指標です。 |
DevOpsの実践におけるインシデント管理のメリットについて詳しく知りたい方は、ebook『DevOps入門ガイド』をご覧ください。
MTTD、MTTA、MTTF、MTBFとは何ですか?
平均復旧時間(MTTR)のライフサイクルには、プロセスの最初と最後にさらに多くの測定項目が含まれます。これらのインシデント指標は、チームが問題をどれだけ迅速に検出し、初期段階でステークホルダーに通知するかを測定します。また、全体的な障害統計を測定し、長期的な信頼性や修復効率を判断します。
| 指標 | 説明 |
|---|---|
平均検知時間 |
平均検出時間(MTTD)は、問題が発見されるまでにどれだけの時間が経過しているかを測定します。MTTDは、ITチームやDevOpsチームにとって主要な主要業績評価指標(KPI)です。インシデントが未検出のまま放置される時間が長ければ長いほど、システムに甚大な被害をもたらす時間が長くなります。MTTDは、平均特定時間(MTTI)とも呼ばれます。MTTDとは、インシデントを検出するか、またはアラートを受信するまでに要する時間のことです。
MTTDは、一定期間におけるインシデントの発見にかかる平均時間を測定し、それをインシデント件数で割ることで算出します。 MTTDを低く抑えることは重要です。なぜなら、問題を早く発見すればするほど、システムへの潜在的な被害が少なくなり、修復にかかるコストも抑えられる可能性があるからです。 |
応答までの平均時間 |
平均応答時間(MTTA)とは、システムがアラートを生成してからチームメンバーが対応するまでの時間のことです。MTTAは、チームメンバーがアラートを受信してから問題の対応を開始するまでに要する時間を示します。
MTTAが短いということは、チームが迅速に対応しており、最も深刻なダウンタイムやサービス停止を引き起こす可能性のある高リスクのアラートを優先していることを示しています 。 MTTAは、アラートシステムの効果を測定し、チームが応答性に関する合意事項を満たすのに役立ちます。MTTAが短いということは、デジタルエクスペリエンス管理にとって重要なサービスの損失を防ぐための「迅速な対応」という姿勢を示しています。 |
平均故障間隔 |
|
平均故障間隔(MTBF) |
平均故障間隔(MTBF)は、修理可能なシステムのシステム障害が発生するまでの平均間隔を測定します。MTBFは、システムの信頼性を測定するもう一つの方法です。
MTBFが短いほど、ダウンタイムの可能性が高くなります。なぜなら、障害が発生すると、その特定、封じ込め、および解決措置が必要となるためです。MTTFと同様に、MTBFもメンテナンスサイクルの一部であり、コンポーネントの運用フェーズを測定します。 |
AIと自動化を活用してMTTRを測定し、インシデント対応時間を短縮する方法
MTTRの測定には、監視対象のすべてのシステムからの詳細なメトリクスが必要です。従来のオンプレミス環境では、それだけでも十分に複雑です。しかし、現代のマルチクラウド環境の規模でインシデント対応を効果的に管理するには、IT運用向け人工知能(AIOps)と自動化を活用したプラットフォームアプローチが必要です。
Dynatraceのソフトウェアインテリジェンスプラットフォームは、マルチクラウドスタック全体を監視します。Dynatraceはフォールトツリー分析を活用し、問題を自動的に特定し、コンテキストに基づいて根本原因を特定します。この自動検出機能により、MTTD、MTTA、MTTR、MTBFを含むすべてのインシデント管理段階において、メトリクスの収集と根本原因分析にかかる時間をほぼゼロに短縮します。
Dynatraceによる自動的かつインテリジェントな分析により、早期検知と自動対応が可能となり、問題がサービス停止へとエスカレートするのを防ぎます。DevOpsチームは、インシデント管理のメトリクスのいずれかをサービスレベル目標(SLO)として設定し、インシデント対応を自動化してMTTRを大幅に短縮することができます。
MTTRやインシデント管理がサイトリライアビリティエンジニアリング(SRE)戦略にどのように組み込まれるかについて詳しく知りたい方は、『DynatraceSREレポート』をご覧ください。


ご質問がありますか?
Q&Aフォーラムで新しいディスカッションを開始するか、助けを求めてください。
フォーラムへ