
As our customers adopt agile software development and continuous delivery to drive value faster, they face new risks that could impact availability, performance, and business KPIs. These new risks have driven our customers to adopt Site Reliability Engineering (SRE) teams to help create reliable and scalable software systems without slowing down. However, adding more stakeholders can also run the risk of silos developing between internal organizations.
At Dynatrace, we recognized this increased need for SRE teams and the need to break down silos. The solution is a cohesive platform that enables SRE teams, application developers, support teams, and other stakeholders to work together from the same intelligence.
To meet this need for cross-team collaboration, the Dynatrace Software Intelligence Platform provides a place for SREs to define Service-Level Objectives (SLOs) and Service-Level Indicators (SLIs). By defining a common set of SLOs in a unified observability platform, stakeholders can work together to build reliable and scalable software systems that automatically meet agreed-upon service levels without slowing down.
Scaling out SLOs
Because of the ever-evolving nature of continuous delivery, it’s not enough to just create a single SLO. Teams need to continuously define SLOs. To define SLOs at scale, Dynatrace provides an all-in-one SLO API. We’ll explore the process of defining SLOs and using the API to scale-out SLOs.
Defining and Configuring Service Level Indicators (SLIs)
Defining SLIs
An SLI is a measurement of the performance or availability of an entity. The measurement equates to a metric that captures expected results. The first step to defining an SLO is to identify the success metric. Dynatrace provides many Built-in metrics you can use, or you can create your own calculated metrics for any of the following entities:
- Web apps and mobile apps (Application)
- Services (Service)
- Synthetic metrics (Synthetic)
- Log Metrics (Log)
Here is an example of a calculated metric for a service. This calculated metric is a Request Count of all requests for a service with a response time of less than 4 seconds (see red boxes). Later, we’ll explore creating an SLO example for this calculated metric. (To see the example, skip to the measure section in the Creating SLOs):
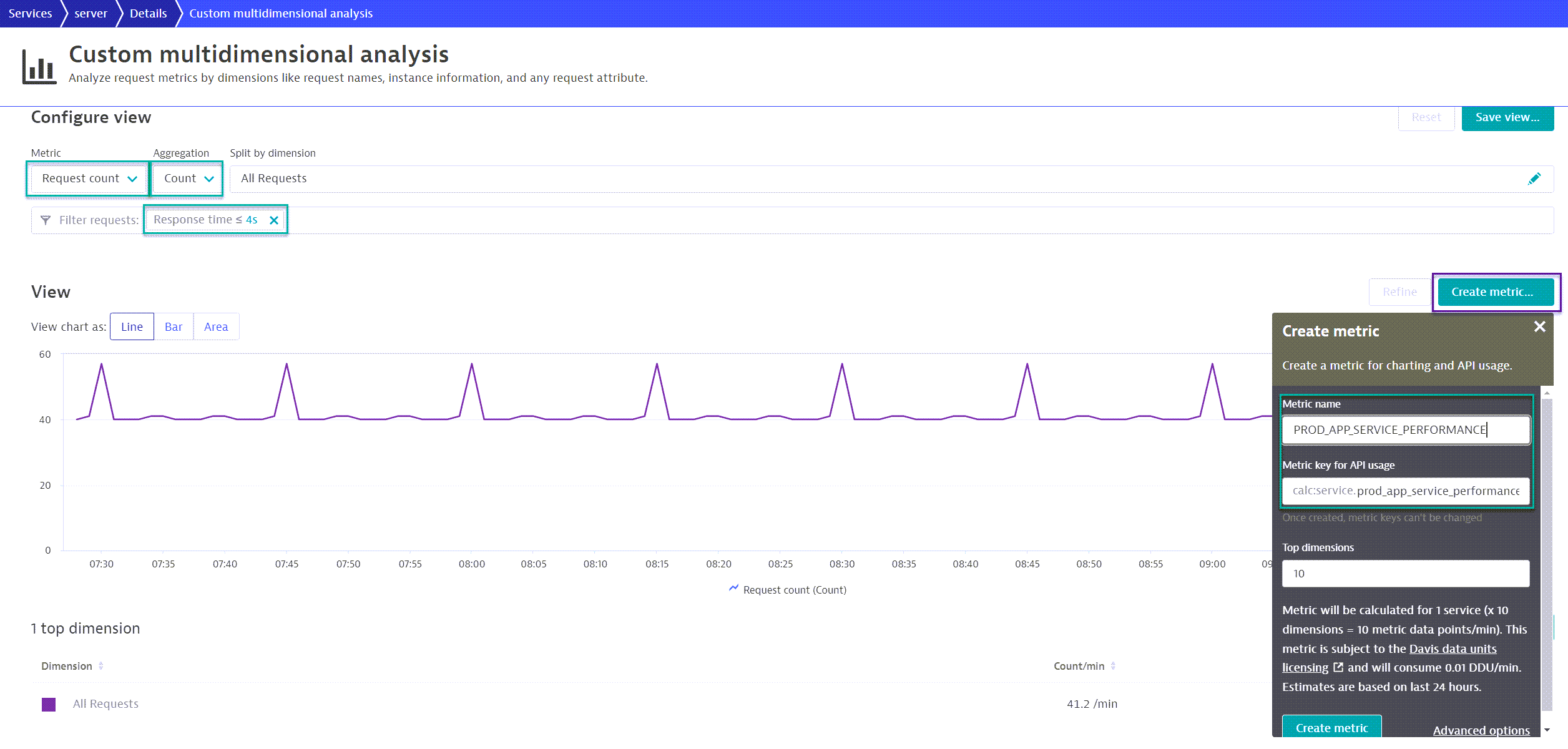
Tip: The calculated metric should be a count/value metric, which counts all the instances that meet the filter criteria, in this case, Response time ≤ 4s. This is a good practice because the objective of SLIs is to measure the expected results. In this scenario, the expectation is that requests will process under or equal to 4 seconds.
Configuring SLIs
Once you identify the success metric, you can create the SLO. In this example, the success metric is a performance measure of request-response times of less than 4 seconds, which can result in the following SLO “95% of service requests will respond in less than 4 seconds.” To further automate this process; You can use the calculated metric APIs to create a template of a calculated metric.
Tip: When generating calculated metrics via API, use a naming convention. This makes it easier to keep track of your calculated metrics. One example of a naming convention can be {Environment}_{App Name}_{Component}_{Measure type}, where:
- Environment – Production vs staging vs non-production.
- App Name – The name of the product or application/OR any other identifier which distinguishes groups of products/applications.
- Component – Additional identifier of the calculated metric, typically some dimension of the measurement or how it’s used. For example, if a specific request is used for a calculated service metric, the component could be the request name.
- Measure type – The SLI’s measurement type, for example, performance or availability.
Below is a list of possible SLI measurements possibilities sorted by entity and measure. Use this list to copy and create your SLOs. This list contains metrics used in the numerator of the SLO.
| Entity | Measure | Metric (calculated metric filter, if applicable) | Calculated metric required? |
| Application | Performance |
|
Yes |
| Application | Availability | builtin:apps.web.actionCount.category:filter(eq("Apdex category",SATISFIED)):splitBy():sum |
No |
| User Action | Performance |
|
Yes |
| User Action | Availability |
|
Yes |
| Service | Performance |
|
Yes |
| Service | Availability | builtin:service.errors.total.successCount:splitBy():sum |
No |
| Service Request | Performance |
|
Yes |
| Service Request | Availability | Built-in Metric
Calculated Service Metric
|
Both |
| Synthetic (Browser) | Performance |
|
Yes |
| Synthetic (Browser) | Availability | builtin:synthetic.browser.success:splitBy():sum |
No |
| Synthetic (HTTP) | Performance |
|
Yes |
| Synthetic (HTTP) | Availability | builtin:synthetic.http.resultStatus:filter(eq("Result status",SUCCESS)):splitBy():sum |
No |
How to Read:
|
|||
Create SLOs
Now we’ve identified the SLI, we can create the SLO. There are four components of an SLO:
- Measure
- Entity selector
- SLO Target
- Evaluation timeframe
The measure
You can define the measure as either a rate or metric expression.
A rate measure simply consists of a single rate metric, for example, the availability rate for HTTP monitors. The metric expression consists of a numerator, the SLI we identified above, and the denominator (the total count). To learn more about how to use metric expressions in SLOs, see Level up your SLOs by adding math to the equation. Once you’ve identified the numerator and respective denominator, the metric expression is complete. In our example, we’ll use the following metric expression for all SLOs:
(100)*((numerator)/(denominator))
Below is a list of the Overall Count metric sorted by entity (denominator) and the metric used for each:
| Entity | Built-in Metric SLI (numerator) | Calculated Metric SLI (numerator) |
| Application | builtin:apps.web.actionCount.category:splitBy():sum |
builtin:apps.web.actionCount.category:splitBy("dt.entity.application")
:filter(in("dt.entity.application",entitySelector("type(APPLICATION),entityName({App Name})")):sum
|
| User Action |
|
builtin:apps.web.action.count.xhr.browser:splitBy("dt.entity.application_method")
:filter(in("dt.entity.application_method",entitySelector("type(APPLICATION_METHOD),entityName({App Method Name})")):sum
builtin:apps.web.action.count.load.browser:splitBy("dt.entity.application_method")
:filter(in("dt.entity.application_method",entitySelector("type(APPLICATION_METHOD),entityName({App Method Name})")):sum
builtin:apps.web.action.count.custom.browser:splitBy("dt.entity.application_method")
:filter(in("dt.entity.application_method",entitySelector("type(APPLICATION_METHOD),entityName({App Method Name})")):sum
|
| Service | builtin:service.requestCount.total:splitBy():sum |
builtin:service.requestCount.total:splitBy("dt.entity.service")
:filter(in("dt.entity.application_method",entitySelector("type(SERVICE),entityName({Service Name})")):sum
|
| Service Request | builtin:service.keyRequest.count.total:splitBy():sum |
builtin:service.keyRequest.count.total:splitBy("dt.entity.service_method")
:filter(in("dt.entity.application_method",entitySelector("type(SERVICE_METHOD),entityName({Request Name}))")):sum
|
| Synthetic (Browser) | builtin:synthetic.browser.total:splitBy():sum |
builtin:synthetic.browser.total:splitBy("dt.entity.synthetic_test")
:filter(in("dt.entity.application_method",entitySelector("type(SYNTHETIC_TEST),entityName({Browser Name})")):sum
|
| Synthetic (HTTP) | builtin:synthetic.http.resultStatus:splitBy():sum |
N/A |
Here is an example of an SLO with a calculated service metric expression (service Performance):
| Metric Expression | (100) *(({Numerator})/({Denominator})) |
Expression used to define an SLO |
| Numerator | PROD_APP_SERVICE_PERFORMANCE |
SLI using a calculated service metric, where service requests <= 4 secs are counted |
| Denominator | builtin:service.requestCount.total:splitBy("dt.entity.service"):sum: filter(in("dt.entity.service"),entitySelector("type(SERVICE),entityName(Important Service)")) |
Overall count metric for Services. Includes entitySelector because the SLI is a calculated metric |
| EntitySelector | N/A | EntitySelector is defined in the denominator. |
| Result | (100) *((PROD_APP_SERVICE_PERFORMANCE)/(builtin:service.requestCount.total:splitBy():sum: filter(in("dt.entity.service"),entitySelector("type(SERVICE),entityName(Important Service)")))) |
Final measure used in the SLO |
The entity selector
The entity selector identifies the entities (applications, services, user actions, and so on) the SLO should apply to. SLOs have problem indicators to let us know there’s an active problem with the identified entities. Dynatrace uses the entity selector during problem analysis. As such, all SLOs should have an entity selector to allow Dynatrace to apply problem analysis. We’ve identified the typical entity selectors, but to study more combinations, see Environment API v2 – Entity Selector.
The SLO target
The SLO target can be considered as the SLO requirement. An SLO requirement is the agreed-upon threshold for the metric and equates to some amount of acceptable downtime. The SLO target is made up of a target and warning. An example of an SLO requirement can be “95% of service requests will respond in less than 4 seconds”. The target will be 95%. The warning is a way to be aware of when the measurement is still in an acceptable range but is approaching the target (for example, 96% would be displayed in yellow text). Any percentage above the warning threshold will be shown in green text (for example, 97% or greater). The chart below breaks down possible SLO targets and their downtime.
| Availability % | Downtime per year | Downtime per quarter | Downtime per week | Downtime per day |
| 90% (“one nine”) |
36.53 days | 9.13 days | 16.80 hours | 2.40 hours |
| 95% (“one and a half nines”) |
18.26 days | 4.56 days | 8.40 hours | 1.20 hours |
| 97% | 10.96 days | 2.74 days | 5.04 hours | 43.20 minutes |
| 99% (“two nines”) |
3.65 days | 21.9 hours | 1.68 hours | 14.40 minutes |
| 99.9% (“three nines”) |
8.77 hours | 2.19 hours | 10.08 minutes | 1.44 minutes |
| 99.99% (“four nines”) |
52.60 minutes | 13.15 minutes | 1.01 minutes | 8.64 secs |
The evaluation timeframe
The evaluation timeframe is the agreed-upon period you are measuring to evaluate the SLO. You can define the evaluation timeframe using Dynatrace TimeFrame Selector Expressions. A typical evaluation timeframe can be a full month, which you can express with the timeframe selector ‘-1M/M to now/M’. This selector reads this way: Start 1 month ago and round the month (to always get the start of the previous month) to the end of the current month and round up the month (to always get the start of the current month).
Once you generate the SLO, you can use the SLO API to get the JSON template of the SLO to automate SLOs for similar measures.
Tip: When generating SLOs using the SLO API, apply a naming convention. For example, you can use the naming convention we expressed earlier: {Environment}_{App Name}_{Component}_{Measure Type}.
Taking on SLOs
Start utilizing SLOs TODAY to take control of your agile software development and continuous delivery practices. First, start small and end big: start with a single application and identify all the key user actions, key service requests, and so on, and define SLOs for each. Eventually, set a requirement for each application to have a preset of SLOs defined. You can then work your way to full-on SLO automation. Explore how Dynatrace can help you create and monitor SLOs, track error budgets, and predict violations/problems before they occur, so teams can prevent failures and downtime.
Tip: This community tool can help automate SLOs – MONACO. MONACO is a CLI tool to automate the deployment of Dynatrace monitoring configuration.
As you build out your SLO implementation utilize this Dynatrace Community SLO Forum, to read more about upcoming SLO features.
Happy tracking SLOs!
To learn more about how Dynatrace does SLOs, check out the on-demand performance clinic, Getting started with SLOs in Dynatrace.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum