
Dynatrace automatically detects process types such as Tomcat, JBoss, Apache web server, MongoDB, and many others. We also take technologies like Docker, Kubernetes, OpenShift, Cloud Foundry, and Azure into account. A process group is a set of processes that run on separate hosts but belong to the same application or deployment unit.
While we’ve worked hard to provide you with 100% automated process group detection, there are some scenarios for which manual customization of process group detection is required via settings in the Dynatrace UI. Until now, process group detection was achieved by designating a specific environment variable (DT_CLUSTER_ID). For Java processes, we have long provided the option of designating specific Java system properties as identifiers. The advantage of this approach is that it leverages your existing configuration and doesn’t require changes to your deployment configuration. We’ve now added a similar configuration option for non-Java processes!
Process group detection rules
Dynatrace process group detection settings have been extended to now additionally cover non-java processes like Nginx, Apache HTTPserver, FPM/PHP, Node.js, IIS, and .NET. As with Java processes, process group detection for non-Java processes also relies on environment variables.
To add a process-group detection rule
- Go to Settings > Monitoring overview > Process group detection.
Any pre-existing detection rules are listed at the bottom of the page. - Click the Add detection rule button.
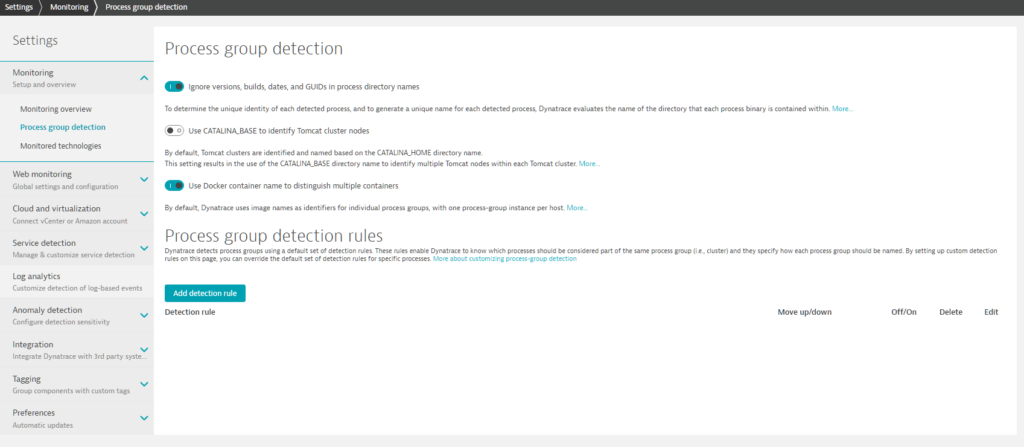
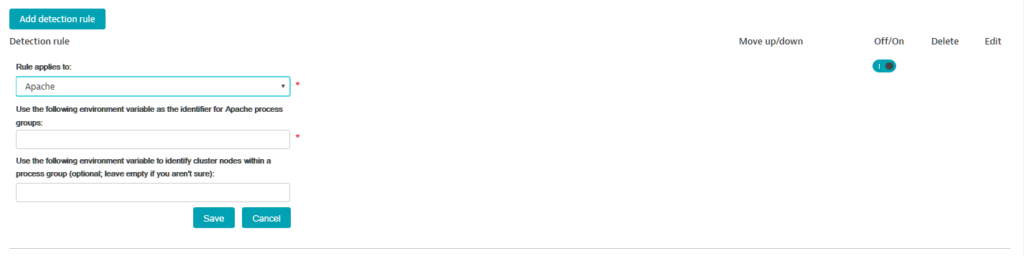
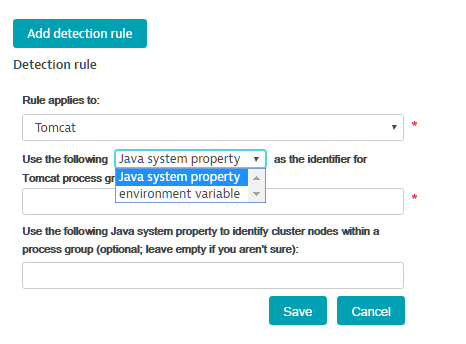
- From the Select process type drop list, select the technology type of the processes you want to group.
- Type in the environment variable that should be used as the identifier for the process group.
- (optional) You can additionally type in an environmental variable that should be used to identify cluster nodes within a process group.
- Click Save.
Environment variables
The environment variables that you select to serve as process group identifiers must exist within the scope of the detected processes. Identifiers have the same effect as DT_CLUSTER_ID variables. Identifiers also serve as the default name for detected process groups.
For example, consider two nearly identical Apache HTTP server deployments that reside within the same deployment directory but on different hosts. By default, Dynatrace can’t distinguish between the two deployments because they don’t possess any unique characteristics that can be used for identification. Now consider the following rule:
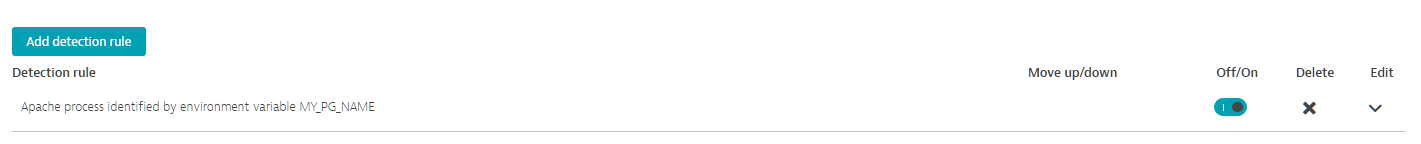
Any Apache HTTP process that includes the environment variable MY_PG_NAME within its scope will use the content of “MY_PG_NAME” as both its identifier and its default name. In this scenario, you can have Dynatrace separately identify and name each deployment by assigning one deployment the environment variable MY_PG_NAME=dynatrace.com-production and assigning the other deployment with MY_PG_NAME=dynatrace.com-staging.
Using environment variables for Java processes
While system properties remain the preferred method for setting up process-group detection for Java processes, we’ve extended the new functionality to Java process-group detection as well. So, now when you set up process-group detection for Java processes, you have the option of using either Java system properties or environment variables to identify your process groups.
Note: Enhanced process-group detection requires Dynatrace OneAgent 1.111 or higher.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum