
Organizations across the world are fast adopting Kubernetes. That is because Kubernetes provides several benefits from a performance perspective. Its ability to densely schedule containers into the underlying machines translates to low infrastructure costs. It prevents a runaway container from impacting other applications by isolating applications from each other.
However, setting the right parameters for Kubernetes clusters to ensure application availability, performance, and resilience while avoiding overspending isn’t a walk in the park. During a joint webinar, Henrik Rexed (Cloud Native Advocate, Dynatrace) joined us to talk about the Kubernetes challenges and how to leverage Dynatrace observability and Akamas AI-powered optimization to address them.

The Akamas approach
Kubernetes microservices applications are a striking example of the complexity of today’s modern application and IT stacks. Tuning thousands of parameters has become an impossible task to achieve via a manual and time-consuming approach. The Akamas vision is that only an autonomous optimization approach powered by AI can effectively enable performance engineers, SREs, and architects to identify the best configurations that ensure maximum service performance and resilience, at the lowest possible cost and at business speed.
To illustrate how Akamas approach works for Kubernetes microservices applications the webinar, the example of Google Online Boutique is used during the webinar. The following figure shows the high-level architecture where any load testing solution (e.g. JMeter, MicroFocus LoadRunner, and Tricentis Neoload) can be used to test the target system against the workloads and where Dynatrace is the single telemetry provider for all the KPIs measuring the results of applying that load to a specific configuration.
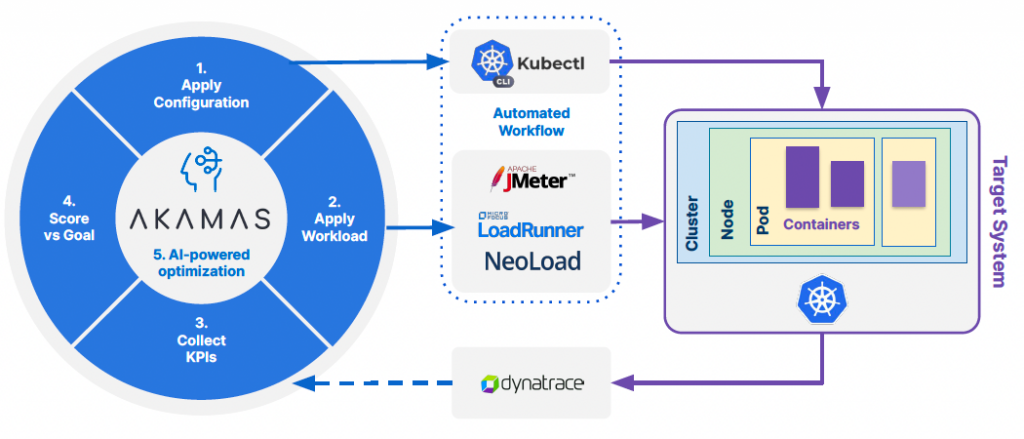
The optimization goal was to improve the application efficiency, that is to improve the ratio between service throughput and cloud costs while not increasing the application latency (e.g. below 500ms) and error rates (e.g. lower than 2%.). In this example, the cost associate to CPU and memory resources allocated to each microservice was calculated with respect to AWS Fargate pricing, which charges 29$/month for each CPU requested and about $3/month for each GB of memory.
During the webinar, we demonstrated how, in about 24 hours, Akamas was able to automatically identify the best configuration that improved the cost efficiency by 77%. The baseline configuration—the initial sizing of microservices—only provided an efficiency of 0.29 TPS/$/mo, while the best configuration provided 0.52 TPS/$/mo. This best configuration could be achieved by reducing CPU limits for several microservices, while increasing both assigned CPU and memory of two particular microservices that were underprovisioned in the baseline configuration.
The following figure also shows how the baseline and best configurations compare in terms of service throughput. The best configuration is not just more cost-efficient, but also improves throughput by 19%, reduces latency peaks by 60%, and makes the service latency much more stable.
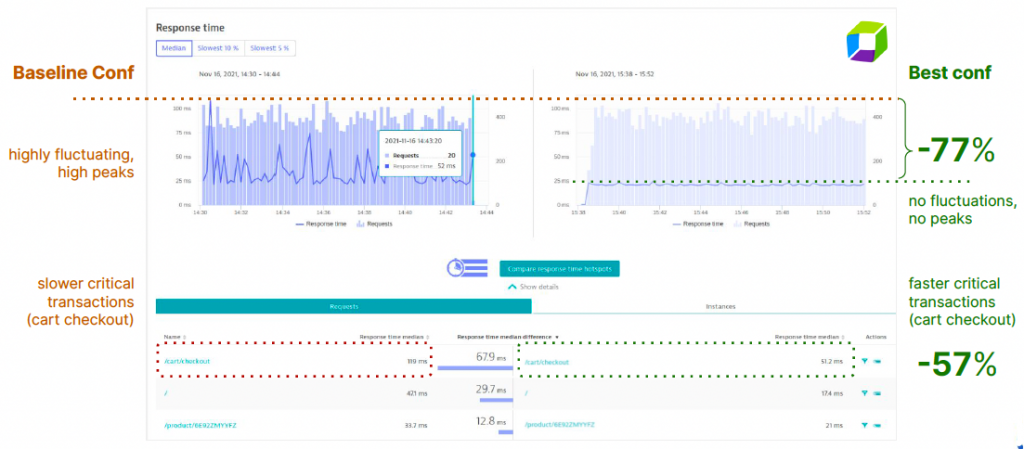
This real-world example illustrates the benefits of the Akamas autonomous optimization approach when applied to Kubernetes microservices application to maximize the application performance and stability while also minimizing costs.
Conclusions
The Akamas approach can be effectively applied to any application by also including any other relevant parameters (e.g. JVM, databases, middleware, operating system, cloud instances, etc) by also taking advantage of Dynatrace full-stack observability.
Additional resources
If you want to learn more about Kubernetes, check out these video resources:
- Performance Clinic: Kubernetes Observability for SREs with Dynatrace
- SREcon21 – Automating Performance Tuning with Machine Learning
- How I learned to love Kubernetes and stop worrying about costs and SLOs




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum