
In part two of this series, I showed how I‘m consolidating multiple Dynatrace API endpoints across my thousands of Dynatrace environments into one. The purpose of this consolidated API was mainly for being able to easily access a large number of tenants for various management purposes. I’ve also shown a preview of another use-case: Visualizing the Problem Status of many environments in a single view:
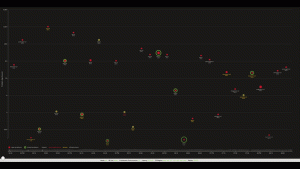
Although with Dynatrace Davis® and its AI-driven problem detection the need for a lot of dashboards to visualize metrics becomes less important, sometimes it’s quite nice to have a big screen that shows a high-level view on your whole landscape – easy to understand and powerful in the information represented.
Real-time problem visualization of lots of environments
I wanted to present as much information as possible. Everybody should be able to understand what’s going on without a long introduction or user manual.
I’ve put out these requirements, that I want to see or understand:
- Every environment that currently has any open problems in real-time
- How long problems exist in those environments
- What type of problems exist in an environment
- If an environment is “healing” as problems get resolved again
- Any cross-environment problems, e.g. an issue in a datacenter that impacts many environments
- The problem status of the past (e.g. what was the situation like tonight at 2am)
Before we dive into the technical implementation, let me explain the visual concept of this “Global Status Page”:
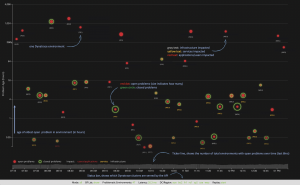
Another requirement for this status page was that it has to be lightweight, with no data storage at all. This is where the consolidated API, which I presented in my last post, comes into play. Getting the problem status of all environments has to be efficient. For the real-time aspect of the visualization I wanted to update the view at least every 30 seconds.
Lightweight architecture
I’ve decided to build the problem status page using Python Flask and flask-socketio extension for Websockets communication with clients. For the client-side visualization, I decided to go with the D3.js framework.
Websockets allows efficient data push via multicast to browsers and D3.js is a JavaScript framework used for powerful and even animated data visualization.
The overall architecture – including the consolidated Dynatrace API – is shown below:
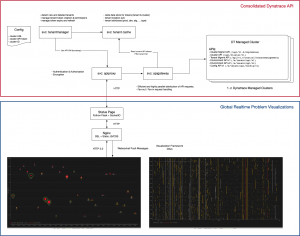
The Python-Flask backend uses the consolidated API to fetch the problems via the problem feed API. It uses the same options that the standard Dynatrace API provides for fetching the problem feed. In my case, a timeframe of 6 hours is used to get the problems from all Dynatrace environments.
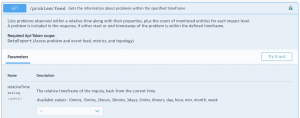
Instead of iterating through all ~1000 tenants, we can just use one fast call that will return all the problem data we need for our visualization:
![]()
Then we extract all the relevant information we need for the visualization and compose a compressed WebSocket message which we emit to all connected browsers/clients. On the client-side, the payload of the message is then rendered via the D3.js framework. What you get is a realtime animated visualization of the problem status across all environments. The page also provides functionality to jump to a specific point in time via a click on the ticker-line. It also allows you to replay the last 6 hours in a “fast-replay” mode.
This page can now be placed on a big screen in your operations center, coffee corner or management offices. Everyone can get a quick idea of how every environment is doing!
Usage examples and lessons learned
Only a few days after I put this visualization live, I had a first big success moment. During a normal meeting the status page was suddenly flooded with red circles. It was immediately clear that this was a datacenter-wide problem, affection all environments!
A quick look into the problem details of a few environments revealed an issue with a VMWare storage system that was impacting them all. None of the infrastructure monitoring solutions was detecting this problem as fast as Dynatrace did on every single environment, and the visualization revealed that this was a global problem that immediately needed to be taken care of.
Another example where this visualization proved very useful was the detection of noise; once I had this visualization put up on my second desktop monitor I quickly realized that this was not only giving everybody a great status overview and insight, but there was also a lot of movement in the lower section of the screen.
Of course, the fact that I use a logarithmic axis also means that the animation of problems “getting older” creates more movement, but I also realized that quite some problem “dots” showed up only to disappear again within a few minutes.
This visual noise was nice to watch as it drew people’s attention. But this also implied that in my Dynatrace environments a lot of short-living problems occurred which could mean irrelevant problems were detected that no one would look into as they only last a few minutes.
This “noise” and the impact on our operations and support team was something I wanted to investigate further! Stay tuned for my next part of this series where I will cover another visualization and how it helped me optimize the Dynatrace Anomaly Detection settings and our operations processes!




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum