
Dynatrace anomaly detection automatically alerts on unexpected system issues without requiring that you configure any thresholds or alerts. Because anomalies in server and process availability are the most critical type of detected anomaly, several enhancements have been introduced in the latest Dynatrace release that provide you with more fine-grained control over alerting for availability anomalies on the server level.
Host availability issues
Having highly stable and available production servers and business-critical software processes is one of the most important aspects of IT operations management. Dynatrace shows the overall availability state of your production servers along with any scheduled maintenance periods (see example below). Each host and process information page includes an overall Availability section.
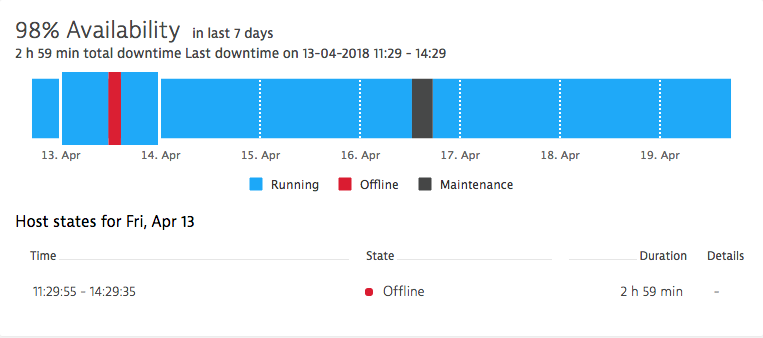
While server availability within classic IT architectures has long been an important consideration in anomaly-detection alerting, within cloud and microservices environments, server availability is now even more challenging to track because numerous new server instances can be spun up on a moment’s notice to accommodate surges in load.
Causes of host availability issues
By default, Dynatrace generates a new availability problem whenever the connection to a running OneAgent is lost unexpectedly. There can be multiple root causes for losing a connection to a monitored host:
- The host may have gone offline unexpectedly, and so OneAgent receives no shutdown signal. This is considered a non-graceful shutdown or crash.
- Network issues may prevent Dynatrace from receiving monitoring signals from a running host. In such cases, it’s unknown if the host is still running.
- The host may shut down gracefully, which means that the operating system sent a shutdown signal notifying OneAgent that an operator is intentionally shutting down the server.
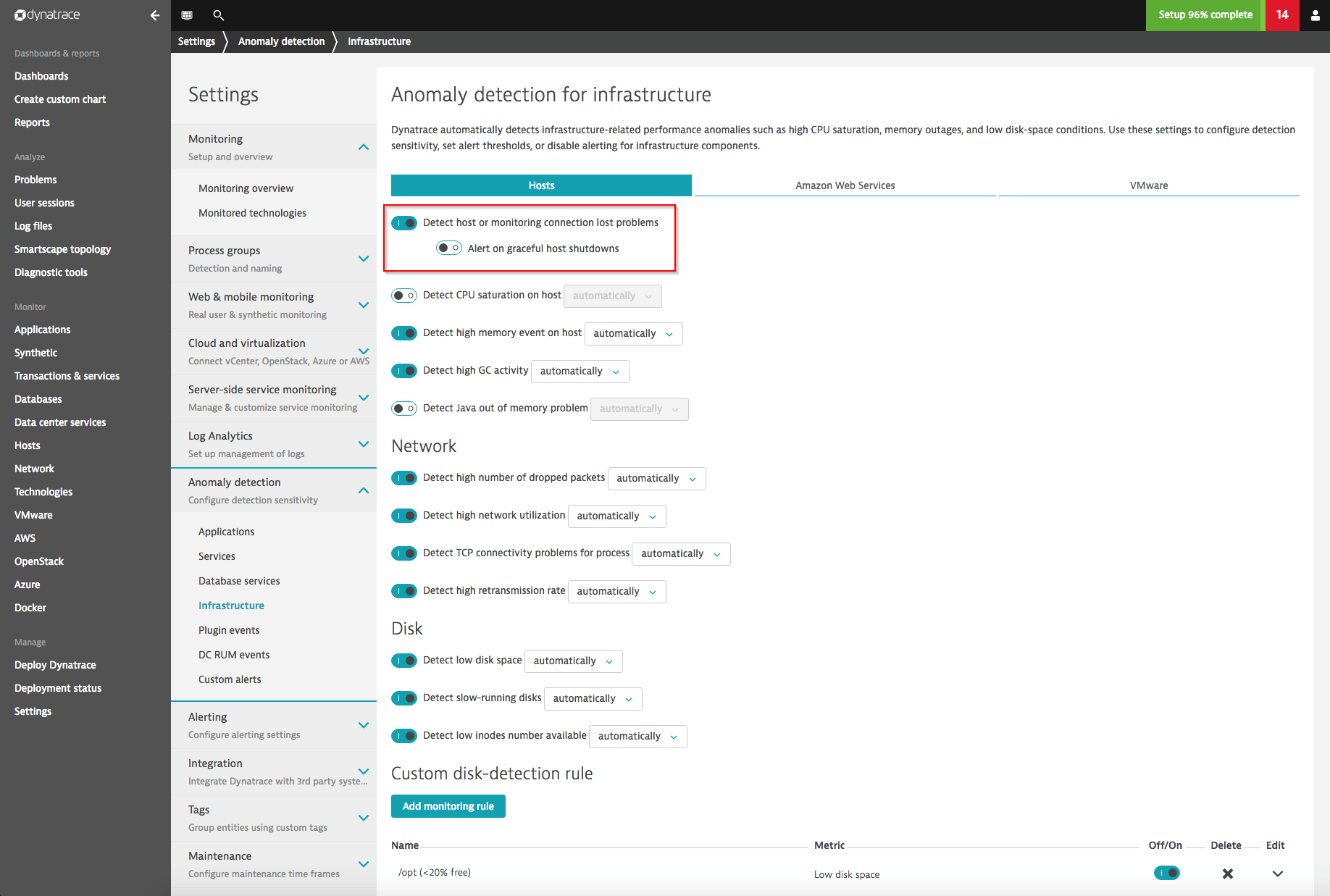
The default host availability-alerting behavior automatically alerts on causes 1 and 2 in the list above. An opt-in setting is available for cause 3. If your DevOps team wants to open alerts for graceful host shutdowns, this can be done either on the global settings level (Settings > Anomaly detection > Infrastructure) or for individual hosts. See global setting example below.
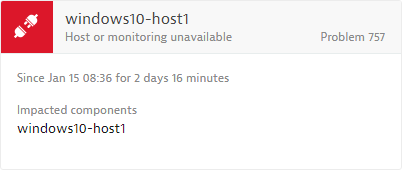
Once you’ve configured a host availability alerting strategy, the next time an affected host becomes unavailable, a Host or monitoring unavailable problem card will appear in your Problems feed (See example below).
Process availability issues
OneAgent detects and reports on the availability of each individual process on each of your monitored hosts—it’s possible that hundreds of thousands of processes are running in your environment at any given moment; Dynatrace monitors them all in real-time. Dynatrace, however, correlates process unavailability with other open issues that impact real users (for example, service error rate increases and slowdowns) before alerts are sent out. We decided against alerting on process availability by default because it tends to introduce a huge amount of alerting noise from processes that aren’t central to the success of your digital business. Typically, individual process availability isn’t crucial within dynamic microservices-based clusters, and so it doesn’t make sense to alert on the availability of individual processes, except when Dynatrace determines that real users are affected by the issue.
However, you may have a number of highly critically-important processes that you want to monitor for availability. Or possibly you want to ensure that a cluster never has less than a specified minimum number of processes. For such scenarios, select the availability alerting strategy that best meets your needs.
To adjust anomaly detection alerting for a process group
- Select Technologies from the navigation menu.
- Select the technology tile of the process group.
- Scroll down and select the process group you want to configure.
- Click the Process group details button.
- Click the Edit button.
- Select the Availability monitoring tab.
- From the Open a new problem drop list, select an alerting option:
– if service requests are impacted: Open aprocess unavailableevent only if Dynatrace detects active client requests hitting the selected process.
– if any process becomes unavailable: Open an event if any of the processes within the process group become unavailable.
– if the minimum threshold isn’t met: Open an event if the minimum number of running processes within that process group isn’t met within an observation period of at least two minutes.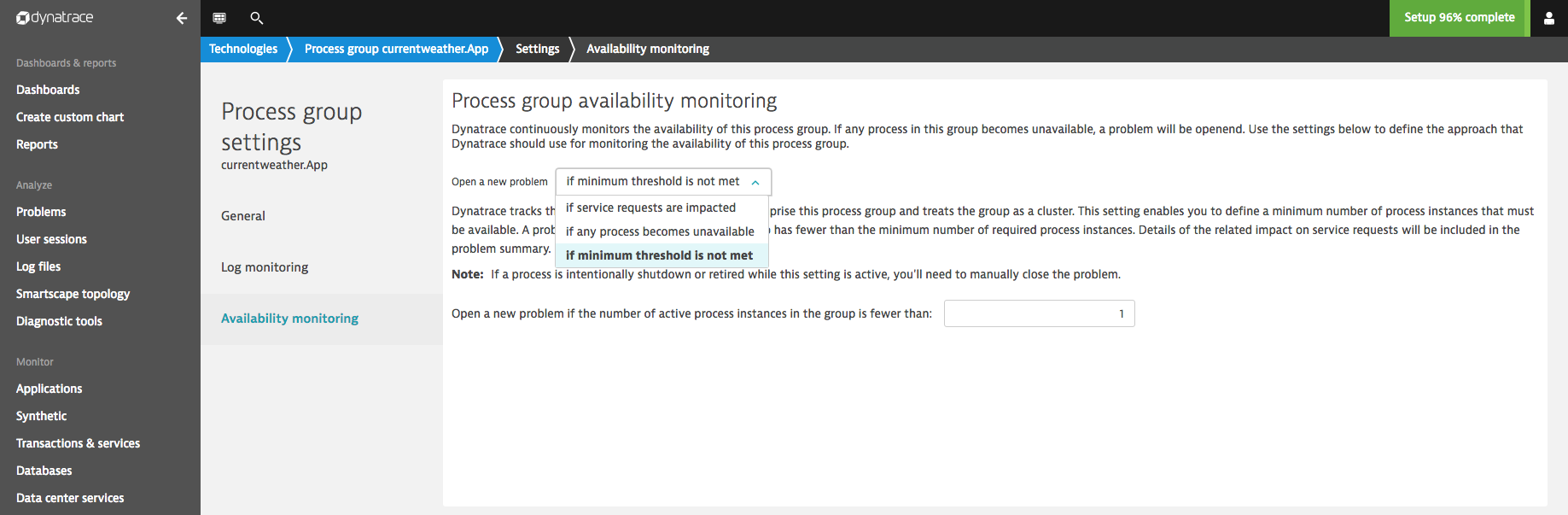
Once you’ve configured a process-group availability alerting strategy, the next time an affected process group becomes unavailable, a Process unavailable problem card will appear in your Problems feed (See example below).
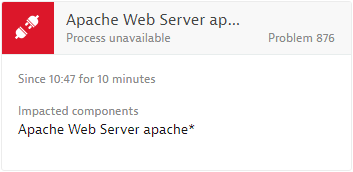
With the latest release, Dynatrace has further enhanced your options for host and process availability reporting. To learn more about which types of events and problem types are reported and evaluated by the Dynatrace AI, see Event types



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum