
With Dynatrace version 1.198, all Dynatrace metrics (built-in as well as custom) can now use auto-adaptive baselines rather than static thresholds for root cause analysis and alerting. Auto-adaptive baselines adapt to changing metric behavior over time, thereby avoiding false-positive alert spam.
While most monitoring solutions still rely on manual thresholds or baselines to identify the root causes of detected issues, Dynatrace Davis® AI has proven over the past four years that a fully automated approach to problem analysis is the only valid approach—especially in highly dynamic, web-scale cloud environments where manual root cause analysis is impossible. With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements.
Dynatrace, as the leading software intelligence platform (Gartner Magic Quadrant), has been known for many years for its unique auto-adaptive, multidimensional baselining in the APM space.
Today we’re happy to announce, that with the release of Dynatrace version 1.198 (SaaS and Managed), auto-adaptive baseline extends beyond application performance (APM) metrics to include thousands of infrastructure and cloud metrics as well.
AI-powered root cause analysis via auto-adaptive baselines for more than classic APM metrics
Auto-adaptive baselining represents a dynamic approach to baselining where the reference value that is used to detect anomalies changes over time. The main advantage of this over static thresholds is that the reference values dynamically adapt over time and no threshold need be determined up front. In many cases, metric behavior changes over time. To avoid the effort of manually adjusting thousands of static thresholds, adaptive baselines are used.
Static vs. auto-adaptive baselining
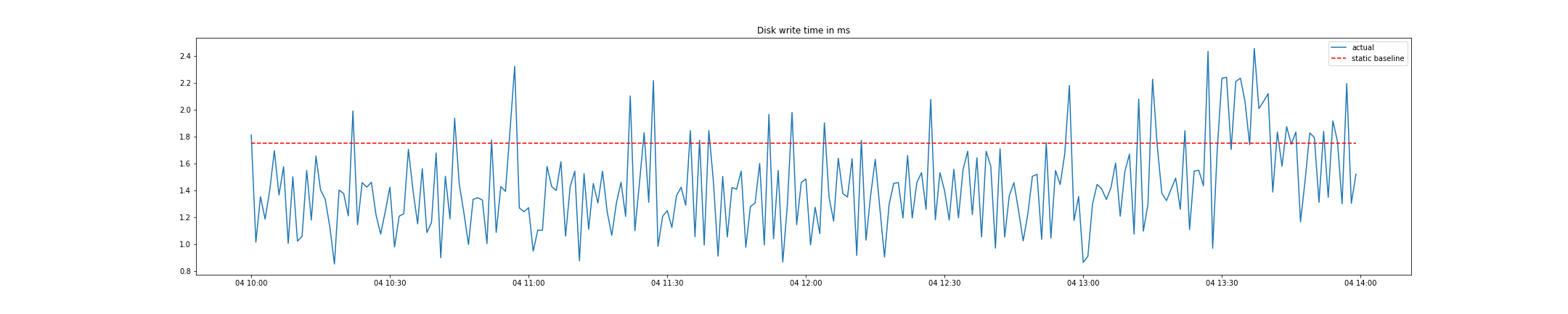
Below is a typical example, where an adaptive baseline has a clear advantage over a statically defined threshold. The chart below shows the measured disk write times in milliseconds for a given disk.
Disk write time is a volatile metric that spikes depending on the amount of write pressure the disk faces. Of course, we could define a static threshold for each disk within the IT system. For this example, we’ll set the static threshold to 20 milliseconds at the start of the chart measurement period. Once defined, you see in the chart below that the usage behavior of the disk changes slightly and that a higher threshold would produce fewer false-positive alerts.
The auto-adaptive baseline however automatically adapts its reference threshold daily, considering the measurements of the previous week. In the example below, this means that the threshold increased after the metric changed its typical level, and a new reference value is used for alerting:
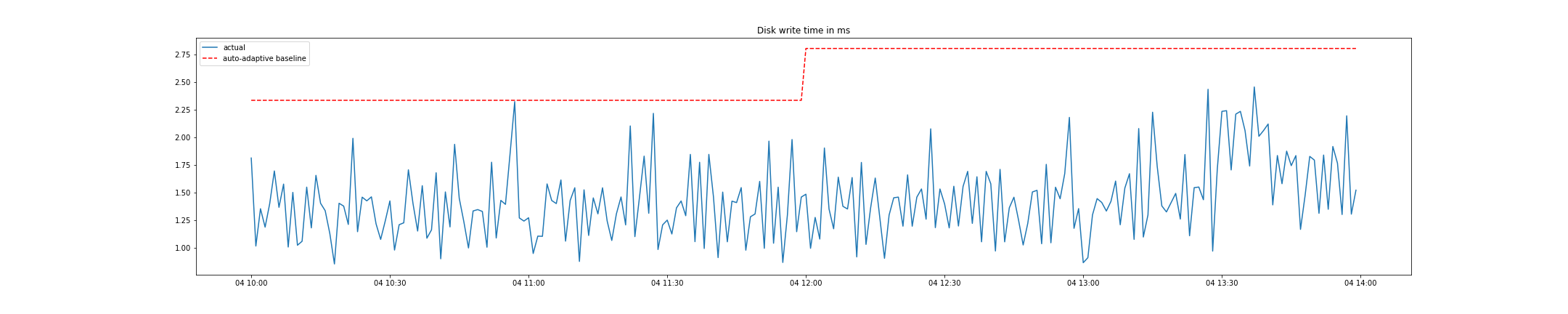
As you can see, the key benefit of an auto-adaptive baseline is that it adapts to changing metric behavior over time, thus avoiding false-positive alert spam.
Seamlessly integrate auto-adaptive baselines into all your metrics
This release extends auto-adaptive baselines to the following generic metric sources, all in the context of Dynatrace Smartscape topology:
- Built-in OneAgent infrastructure monitoring metrics (host, process, network, etc.)
- Built-in OneAgent service metrics (request duration, errors, resource consumption, etc.)
- Calculated service/DEM metrics (revenue numbers, conversions, event counts, etc.)
- Custom log metrics
- Synthetic monitor metrics
- Cloud platform metrics (AWS, Azure, Kubernetes, etc.)
- VMware integration metrics
- Your own ingested OneAgent extension metrics
- Your own ingested ActiveGate extension metrics
- Your own API ingested custom metrics
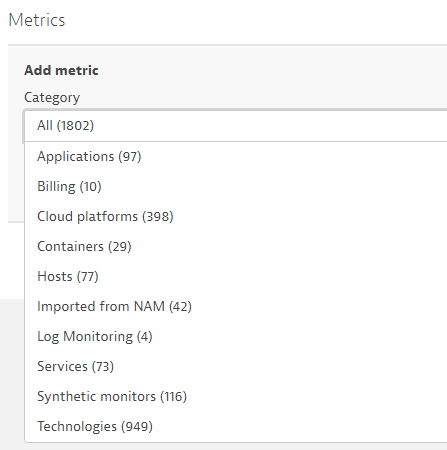
The screenshot below shows all the different metric categories for which you can opt into auto-adaptive baselining:
FAQs
How does Dynatrace calculate auto-adaptive baselines?
To adapt to changing metric behaviors over time, adaptive baselines must “learn” a new baseline value at regular intervals, based on historical data. When updating the reference value, the data of the last seven days is evaluated. Measurements for each minute are used to calculate the 99th percentile of all measurements, which results in our baseline.
The inter-quantile range between the twenty-fifth and seventy-fifth percentiles (25th–75th) is then used as the signal fluctuation, which can be added to the baseline. By using the number of signal fluctuations (n x signal fluctuations) parameter, you can control how often that inter-quantile range is added on top of the baseline, which results in the actual alerting threshold (see the screenshot of the settings page below).
Important parameters for this baseline model are the sliding time window (the “evaluation window”) that is used to compare the current incoming measurements against the baseline and the number of signal fluctuations that’s used to adjust the sensitivity of alerting. By default, to raise an event, any three minutes out of a sliding window of five minutes must violate your baseline-based threshold. The sliding window can be changed to a maximum of 60 minutes to adjust the sensitivity of alerting in order to avoid events over shorter periods of time.
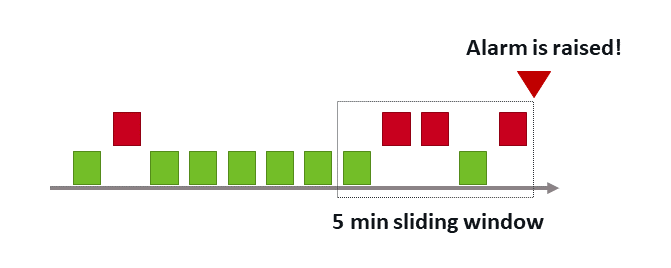
The number of signal fluctuations can also be used to adjust the sensitivity of alerting based on the calculated baseline. n times the normal signal fluctuation, defined as the timeseries variance over the past seven days, is added to the learned baseline reference value.
How can I define an auto-adaptive baseline alert to trigger Davis?
Auto-adaptive baselines are seamlessly integrated into the custom event settings of your Dynatrace environment.
Navigate to Settings > Anomaly detection > Custom events for alerting.
Select your metric using the standard metric picker. Filter by metric dimensions and then choose Auto-adaptive baseline as your monitoring strategy:
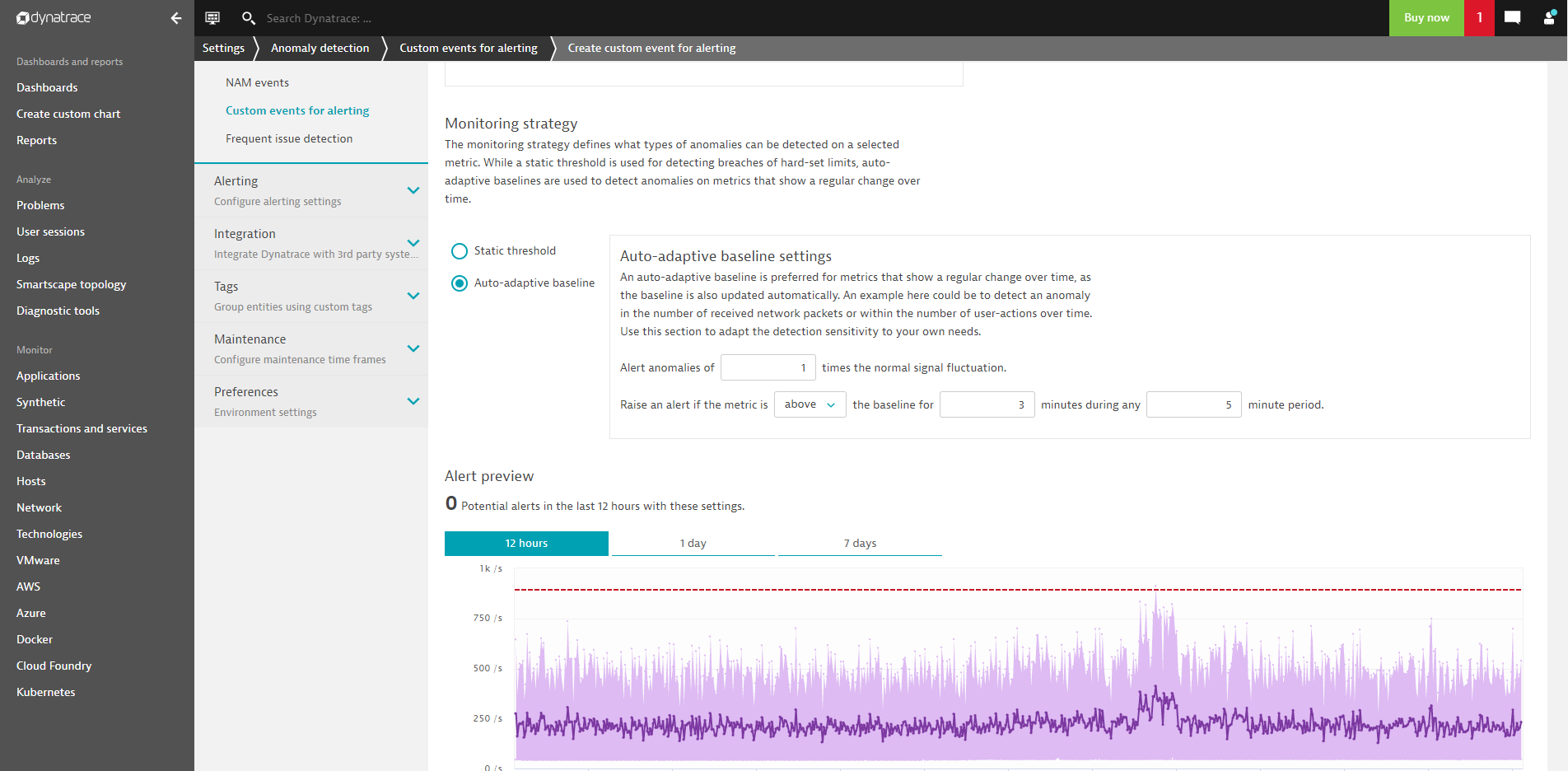
Both monitoring strategies (static and adaptive baselines) offer a convenient alert preview that allows you to review the potential number of alerts when using the given settings.
The number of signal fluctuations and the sliding evaluation window for alerting allow you to further fine-tune alerting sensitivity.
Configuration settings also include meta-information such as the title of the resulting event, a textual description, and a severity level.
The following table summarizes the semantics of all available event severities (which severity types trigger a problem and which severities are analyzed by Davis).
| Severity | Problem raised? | Davis analyzed? | Semantic |
| Availability | Yes | Yes | Reports any kind of severe component outage. |
| Error | Yes | Yes | Reports any kind of degradation of operational health due to errors. |
| Slowdown | Yes | Yes | Reports a slowdown of an IT component. |
| Resource | Yes | Yes | Reports a lack of resources or a resource-conflict situation. |
| Info | No | Yes | Reports any kind of interesting situation with a component, such as a deployment change. |
| Custom alert | Yes | No | Triggers an alert without causation and Davis AI involvement. |
Can I use this feature in my own automation scripts?
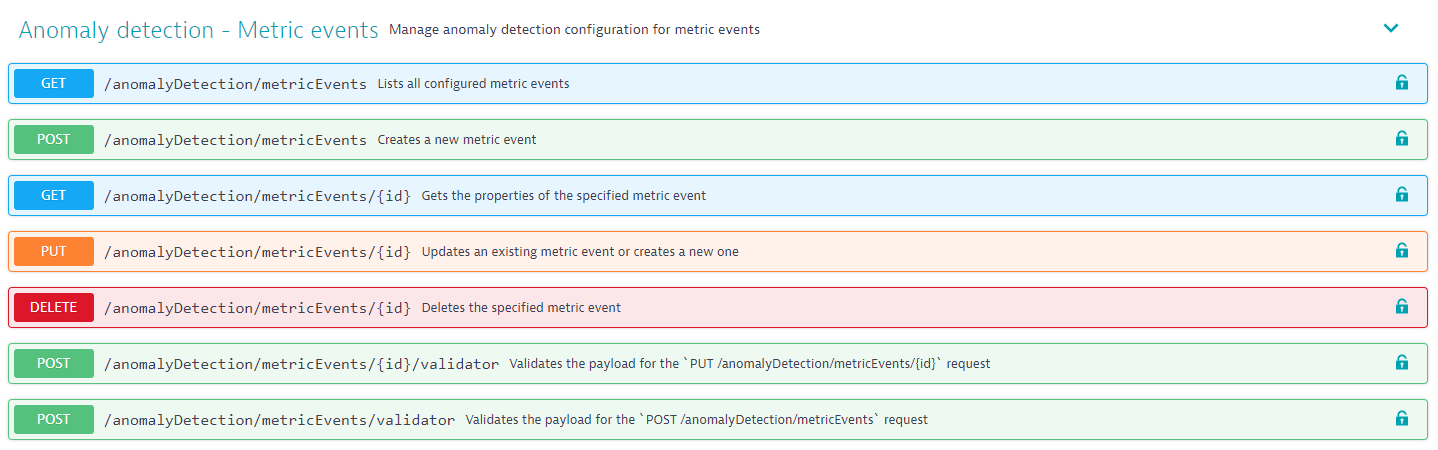
The complete configuration of custom events for alerting along with its auto-adaptive baseline monitoring strategy can be configured using our Configuration API. See the relevant Anomaly detection (Metric events) API endpoints below.
Do I require a special license to use auto-adaptive baselines?
Auto-adaptive baselines are shipped as core functionality within your Dynatrace monitoring environment, which means that they are not bound to any additional cost or license.
In Dynatrace environments, a technical limit of up to 100 baseline configurations is enforced. Each configuration can baseline up to 100 metric dimensions. Whenever a configuration reaches that limit, an alert is raised on the environment level and the related configuration is disabled.
Summary
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve again pushed the boundaries of automatic, AI-based root cause analysis and introduced auto-adaptive baselines as a foundational concept.
With this release, you can define an auto-adaptive baseline on any kind of metric, whether it’s a built-in OneAgent metric or one of your own custom ingested metrics. Auto-adaptive baselines are a great monitoring strategy for triggering the Davis AI to provide deep root-cause analysis. Also, they enable infrastructure monitoring use cases where static thresholds would trigger too many false-positive alerts due to changes in metric behavior.
For more details, see our Auto-adaptive baselining for custom metric events documentation.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum