
This article will take a deeper look into continuous delivery (CD), and describe how this phase of the continuous integration and continuous delivery (CI/CD) process is the key to achieving greater efficiency in your software development life cycle.
Software releases can be full of unknowns, and when the unknown happens, it can be highly stressful and time-consuming for DevOps and SRE teams. Adopting CD practices can help make the release process go more smoothly and remove the guesswork involved in deploying new code, and most importantly, help you automate the software delivery process to be more predictable and efficient.
CD may sound daunting to teams already stretched to the limit. But once established, these game-changing practices and the automation that comes with them can take your software delivery practices to the next level.
What is continuous delivery?
Continuous delivery (CD) is a series of processes for delivering software in which DevOps teams use automation to deliver complete portions of software in short, controlled cycles to different environments as part of a software delivery pipeline. These deliveries should be frequent, carrying incremental changes to the code, which makes releases low-risk, low-stress events for DevOps teams, and seamless for end-users with little or no downtime. Organizations that operate using CD practices strive to always keep code in a deployable state so updates can go live at a moment’s notice with predictable results.
Where continuous delivery fits into the development process
For software to be delivered in a deployable state at all times requires that it be developed with that mindset. In this way, development teams implement small code changes and frequently check them into a central control repository, often many times per day. This process of frequent check-ins is called continuous integration (CI).
CD is the next step in the process that automates the delivery of applications to selected infrastructure environments, such as a development environment for a related feature, or testing environments to verify feature functionality and proper integration with other parts of the software. CD ensures there is an automated way to push code changes consistently and reliably to multiple environments in a “pipeline”. CD pipelines package and deliver applications within a cyclical process of coding, testing, and release.
Continuous integration and continuous delivery together are known as CI/CD.
What are the benefits of continuous delivery?
As software development environments adopt more cloud-native technologies, microservices, and container-based architecture, delivering software manually becomes increasingly impractical. With CD, DevOps engineers write configuration and create custom tests and quality checks that become part of each stage in an automated pipeline.
Adopting and automating CD pipelines offers teams several benefits over the traditional approach:
Developer productivity increases
Without CD, pushing code to a target environment requires manual processes. CD automates the process, so time developers spend manually moving code through the pipeline can be spent creating and optimizing great code.
Automation becomes easier to implement
Because development, testing, release, and deployment are all combined into a tightly coordinated process that focuses on frequent small releases, work is easier to plan and automate. Once automated, steps like testing and provisioning can be integrated into development and performed as soon as needed instead of waiting for humans to be available to do it. Features can be developed faster, and issues identified earlier before they affect the user.
Feedback comes in faster
Releasing small features and fixes very frequently means developers get faster user feedback on new capabilities. Feedback on these smaller increments is specific and enables teams to address fixes while the feature still fresh in their minds. This rapid feedback enables developers to stay focused on innovation instead of managing infrastructure.
Testing quality improves
Under traditional delivery practices, bugs and inefficiencies in code can progress unseen all the way through the delivery process only to be discovered once the bad code has been built upon and entrenched, making it harder to remedy. Under CD methodology, fast, automated testing is part of every stage of the delivery pipeline. This means only good code progresses and faulty code can be discovered and fixed immediately.
New capabilities get to market faster
As automation improves quality and efficiency, the simplest result — and perhaps the most noticeable — is getting features to users faster.
What to measure when calibrating a CD pipeline
Every CD pipeline is unique to the organization it serves, and varies according to architectures, computing environments, tool sets, and corporate, industry, and regulatory requirements. Here are a few common metrics teams should track for every CD pipeline to help you evaluate its efficacy.
Lead time
Lead time is defined by the Agile Alliance as the time between when a requirement is identified and when the final functionality is released. By evaluating lead times for each software increment, you can determine whether to break down deliverables into smaller packages and further reduce time to release.
Cycle time
CD allows for faster and more frequent releases, and events within this process are measured in cycle times—the time it takes for a process to be completed. You can measure cycle time for the entire software delivery life cycle or for smaller, more tactical processes in your pipeline. Tracking cycle times lets you discover ways to improve efficiency. Group similar or complementary features together and plan in a way that reduces cycle time.
Mean time to recovery
Mean time to recovery (MTTR) is the time it takes for a system to roll back updates. If an update failed, this is the time it takes to get back to a working or workable product. To shorten MTTR, developers need data to troubleshoot problems. CD can reduce the time it takes to restore service by providing data about your build quickly, creating the fast feedback loops DevOps teams need to recover quickly.
Defect resolution time
Defect resolution time measures the period from when an issue was discovered to when your developers resolve it. If your defect resolution loop is too long, it can significantly impact your customer churn rate. This measurement can help you optimize your CD process to improve response times.
Test pass rate
Measuring test pass rate gives you an idea of the quality of your product based on the percentage of test cases that pass. It also helps measure how well your automated tests work and how often code changes are causing your tests to break. CD depends on automated testing, and test pass rate helps you fine tune testing methods and improve the effectiveness of your developer feedback loop.
Best practices for adopting continuous delivery
Building a fast and reliable release process requires implementing quality checks, logging practices, and monitoring solutions.
Here are some best practices to consider for automating delivery effectively.
1. Develop Service Level Objectives (SLOs)
Service level objectives (SLOs) are a set of specific criteria that software must meet to satisfy stakeholder requirements. They are defined within a service level agreement (SLA) based on service level indicators (SLIs). Organizations can deliver higher-quality releases faster once SLOs are established and continuously tested at every stage of the development lifecycle.
Establish a multi-stage environment with built-in SLO-based quality gates that can orchestrate your CD workflow and integrate your testing tools for performance testing, chaos testing, and more. When you can be sure your code stands up to SLO-based quality evaluations, you can deploy with confidence.
2. Automate SLO evaluation with quality gates
Once SLOs are in place, you have a framework to begin automating test evaluation. A great way to implement this automation is by designing quality gates, which set out specific success criteria software must meet before going to the next stage in the delivery pipeline. Quality gates take in data from multiple test tools, such as performance testing, integration testing, and observability data, and evaluate it against the criteria specified by your SLOs. This creates a consistent process that’s easily repeatable and easily tunable. AI-assistance helps quickly pinpoint why a test may have failed and how to fix it.
3. Automate every repeatable process
A common pitfall for anyone new to DevOps is to overlook one or two manual steps when automating the delivery pipeline, requiring some action either before, during or after a release is deployed. This can happen for many reasons, including perceived difficulty or up-front cost, or the habit of involving a key member of the staff to make a decision. For CD processes to continuously improve and scale, however, it’s important that you automate every repeatable process throughout software development, testing and deployment.
As you evaluate your processes, make sure you are automating all tests, configuration changes, quality checks, and dependency gathering, taking special consideration for any repeatable process, even if it involves traditionally manual steps or approvals.
4. Eliminate complexity where you can
The complexity of a pipeline grows with the number of tools you use. Managing the process requires streamlining the many tasks involved in checking the final product.
In many cases, automation is built gradually and as needed. As a result, automation code is often spread across several tools making it harder to use and monitor. A solution that can offer an SLO-based orchestration framework is useful to help organizations streamline and automate the continuous delivery process. Having a central control plane for CD pipelines enables teams to keep all their automation code in one place.
5. Establish observability and continuous monitoring
Establishing end-to-end observability for a highly dynamic, cloud-native CD pipeline is crucial for DevOps and SRE teams to deliver applications that meet agreed-upon SLOs. To avoid blind spots and establish efficient root-cause analysis of issues at any stage in the pipeline, teams need reliable telemetry that starts with metrics, logs, and traces, adds user experience data, and also includes the full context of processes upstream and downstream. The ability to capture code-level detail is also critical for debugging and troubleshooting.
As applications and services become more distributed and are based on more open-source technologies, this telemetry can come from many disparate sources, which all require their own instrumentation. Monitoring sources should be automatic and continuous, and flexible enough to deal with continuous updates.
Use automation and intelligence to orchestrate the software development lifecycle
Observability data, such as metrics, logs, traces, user data, and business context, can help you acquire these metrics from your build and test systems directly and automatically. A single observability platform enables you to bypass the clutter and blind spots caused by using many disparate tools and data sources.
To achieve faster time to value with optimized CI/CD pipelines, organizations need intelligent, automated quality gates and SLO-based evaluation so code can automatically progress through the delivery pipeline once it passes pre-defined quality checks. An enterprise-grade control plane that can orchestrate CI, CD, and remediation workflows automatically is essential for managing the cloud-native application life cycle at scale.
Keptn, the open-source, cloud-native, lifecycle orchestration control plane, to the core Dynatrace platform so teams can automate the entire software development life cycle for faster innovation with less risk.
Quality gates make it possible to automate the process of evaluating service level indicators and deliver software increments to the next stage in the CD pipeline only once SLOs are met. This observability and pipeline orchestration help teams identify quality issues earlier in the software life cycle, speed up delivery times, and deliver better customer experiences.
Keep reading
 BLOG POSTUnderstanding continuous integration and continuous delivery (CI/CD)
BLOG POSTUnderstanding continuous integration and continuous delivery (CI/CD) Blog postWhat is DevOps?
Blog postWhat is DevOps?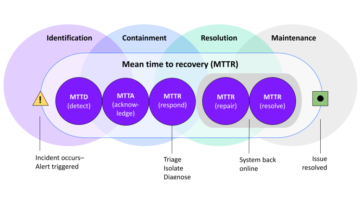 Knowledge BaseWhat is MTTR? How mean time to repair helps define DevOps incident management
Knowledge BaseWhat is MTTR? How mean time to repair helps define DevOps incident management EBOOKThe Developer’s Guide to Observability
EBOOKThe Developer’s Guide to Observability
Explore the ways observability supports secure, efficient cloud-native development.



